의연방11) PSA 분석2(층화, 가중치, 공변량)
Propensity Score Analysis II(stratification, weighting, covariate adjustment)



📜 제목으로 보기✏마지막 댓글로
- R 고급 실습(ps matching with datacleaning-dplyr, MatchIt, tableone-CreateTableOne, geepack-geeglm, broom-회귀계수를 OR로 변환) 포함됨
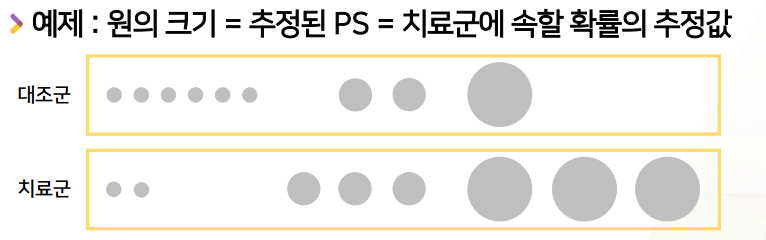
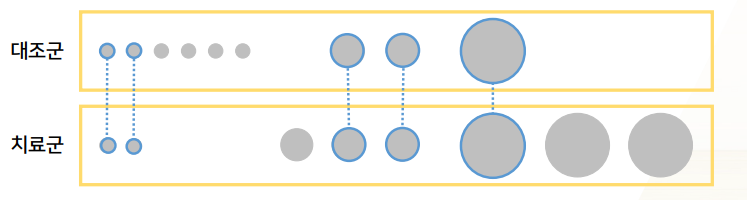
Stratification (요즘 비추)
- PS가 비슷한 환자들끼리 strata를 나눈다 (보통 4~5개)
- 각각의 stratum에서 (치료방법과 )outcome(의 상관관계를 분석)을 비교하고, 그 결과를 전체 strata에 대해서 합친다
- PS score가 같은 그룹 / 중간 그룹 / 큰 그룹을 각각을 stratum으로서 그룹을 나누고
- 그룹별(stratum별) 분석하고
- 나중에 합친다.
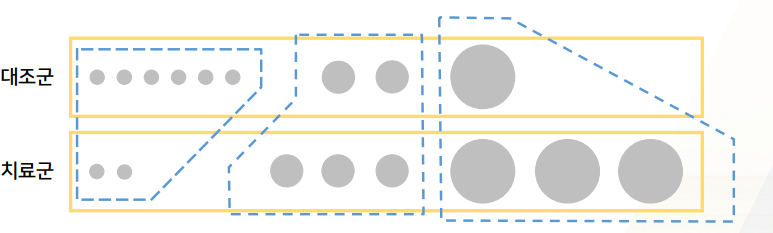
- 단점:
- strata를 나누는 기준이 뚜렷하지 않다
- PS score 몇을 기준으로 나눌지 기준 X가 대부분
- stratum 별로 (너무) 다른 결과가 나올 경우 해석의 문제
- 한쪽에서는 상관관계 높, 한쪽에서는 낮.. 어떻게 합치고 어떻게 해석할지 애매해짐
- 요즘은 안쓰이는 방법
- strata를 나누는 기준이 뚜렷하지 않다
- probability of treatment의 역수이다.
- 치료군의 weight는
- probability of treatment = 치료 받을 확률 = 치료군에 속할 확률 = PS score자체
- 치료군의 weight = Inverse probability of treatment = 1/PS
- 대조군의 weight
- 대조군의 probability of treatment = 치료받지 않을 확률 = 1 - PS
- 대조군의 weight: 1/(1-PS)
- Inverse probability of treatment를 weight로 준다
- 치료군 weight : 1/PS
- 대조군 weight : 1/(1-PS)
-
이렇게
weight를 준 데이터에서는치료군과 대조군 간 PS 분포가 비슷해진다- PS 추정에 쓰인
변수들의 분포(confounding)가 비슷해진다
- PS 추정에 쓰인
-
why? weight를 주면 PS가 비슷해질까?
- 각 stratum별 치료여부별(치료군/대조군별 각각)
probability of treatment를 계산해보자.-
PS가 작은 (원의 size가 작은) 환자들을 보면, 총 8명 중 2명이 치료를 받았다.- 치료군 PS(치.속.확) = 1/4
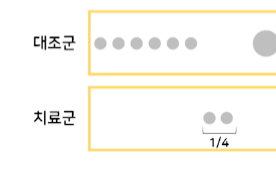
- 대조군 PS = 3/4
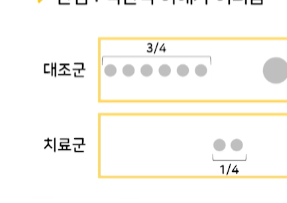
- 치료군 PS(치.속.확) = 1/4
-
중간 size 환자들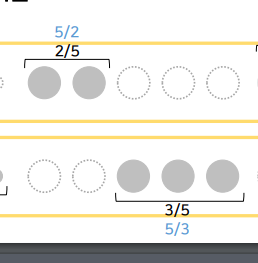
-
큰 size 환자들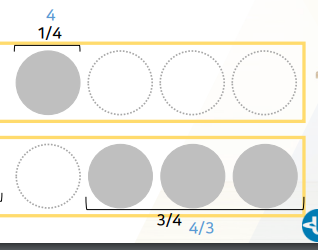
-
- 각 stratum별 치료여부별 PS(probability of treatment)를
Inverse해서 weight로주자.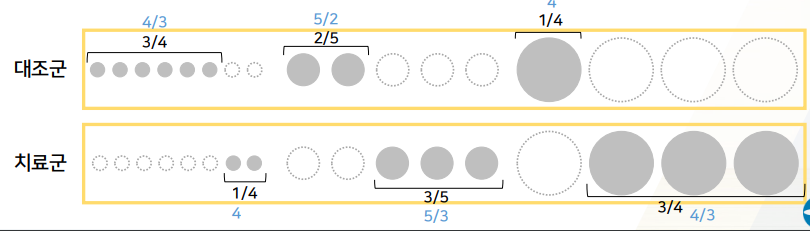
-
작은 size 환자들은 weight가 1보다 큰 4/3이다. 6명 -> 8명으로 뻥튀기 되는 효과를 가진다.- 대조군: 6명 x 4/3 = 8명
- 치료군: 2명 x 4 = 8명
-
중간size- 대조군: 2명 x 5/2 = 5명
- 치료군: 3명 x 5/3 = 5명
-
큰size- 대조군: 1명 x 4 = 4명
- 치료군: 3명 x 4/3 = 4명
-
-
weight를 준 데이터를 보면, 대조군과 치료군 사이에서, PS의 분포가 완전히 똑같아진다.
- PS 역수를 weight로 주어
뻥튀기된 데이터를 이용하면, 2군간 PS가 같아져서 balance가 맞게 됨을 이용하여 -> 2군간의 confounding이 없어진다.
- PS 역수를 weight로 주어
- 각 stratum별 치료여부별(치료군/대조군별 각각)
-
장/단점
- 장점 : outcome 분석 방법의 flexibility
- R에서는 weight를 줘서 분석하기에 편함. 다 적용 가능.
- 단점 : 직관적 이해가 어려움
- 간단한 예제도 여러 계산을 거침. matching처럼 확 이해되지 않음. Weighted data에서의 치료군과 대조군의 balance를 평가해야한다
- 장점 : outcome 분석 방법의 flexibility
- PS matching과 마찬가지로 SMD 이용 Weighting 이후 분석 : weighting을 고려한 분석을 해야 한다
- 회귀분석 : weight 사용. robust variance estimator 사용.
- Survival outcome의 경우: adjusted Kaplan-Meier curve, modified log-rank test
-
PS matching과 마찬가지로, 치료군/대조군 여부 이외에 다른 공변량을 포함할 필요가 없으나, 포함을 할 경우 doubly robust 해진다
-
주의점
- 경우에 따라서 PS가 0에 가깝거나 1에 가까워서 weight의 분모가 무한대 or 0에 근접하는 경우가 있어서 분석 결과가 불안정하게 된다.
- weight를 안정화시켜주는 방법들이 개발되어있다.
-
Stabilized weight(추천):
-
marginal probability of treatment (MPT): 전체 환자 n명 중 치료군 m명의 비율 -> 계산이 간단함.- 환자 특성 고려없이 전체적으로 봤을 때 치료군에 속할 확률
- 치료군 weight에는 바로 곱해준다. :
MPT x (1/PS) - 대조군 weight에는 (1-MPT)를 곱해준다 :
(1-MPT) x (1/(1-PS))
- IPWS보다는 더 안정적으로 값을 가지며, 2군간의 weight된 데이터가 PS분포가 비슷한 것 자체는 유지됨.
-
- trimmed or truncated weights
- Stabilized weight의 방법외에 weight가 너무 크거나 작은 환자를 분석에서 제외 or 분석에 포함시키되 weight값을 truncate(한계점 넘어가면 잘라내서 고정)해주는 방법도 있다.
- 경우에 따라서 PS가 0에 가깝거나 1에 가까워서 weight의 분모가 무한대 or 0에 근접하는 경우가 있어서 분석 결과가 불안정하게 된다.
-
weight된 데이터는 PS matching처럼 balance가 잘 맞을까?
- PS matching과 마찬가지로
SMD 이용해서 평가한다
- PS matching과 마찬가지로
-
Weighting 이후 분석 : weighting을 고려한 분석을 해야 한다
- 회귀분석 : weight 사용.
- 매칭처럼 p-value/신뢰구간 계산시
robust variance estimator사용.
- 매칭처럼 p-value/신뢰구간 계산시
- Survival outcome의 경우: adjusted Kaplan-Meier curve, modified log-rank test
- weight를 줄 경우 시행해주는 평가방법?!
- PS matching과 마찬가지로, 치료군/대조군 여부 이외에 다른 공변량을 포함할 필요가 없으나, 포함을 할 경우 doubly robust 해진다
- 회귀분석 : weight 사용.
- 4번째 PS 방법
-
PS 추정후 데이터를 수정하는 것이 아니라구한 PS를 최종 모델에 공변량으로서 추가한다.
-
- outcome 비교를 위한 회귀분석 모델에 PS를 공변량으로 넣는다
- model: outcome~ 치료군/대조군 +
PS
- model: outcome~ 치료군/대조군 +
- 장점 : (모든 회귀분석에 적용할 수 있어서)outcome 분석 방법의 flexibility
- 단점 :
- outcome과 PS의 관계가 올바르게 모델 되어야 한다
- PS가 선형 모델이 맞는지 취약하다.
- 디자인 단계와 분석 단계의 완벽한 분리가 되지 않는다
-
PS matching이나 weighting은 데이터를 새롭게 만들어서 쓰면 되므로,데이터 가공단계로서 분석과 별개의 단계 - 공변량으로 추가하는 것은, 분석단계 실패시, PS를 다시 추정하는 단계로 돌아가 디자인<-> 분석단계가 분리되지 않음.
-
- outcome과 PS의 관계가 올바르게 모델 되어야 한다

- HPV백신은 임산부들에게 recommend되지 않는데, 임신하지 모르고 맞는 경우가 가끔 있을 것이다.
- 이 경우, 안전한가? 임신이라는 outcome에 영향을 주지 않는가? 는 중요하다.
- 의학적으로 중요. HPV 백신 이후에 임신 사실을 알았을 때 어떻게 해야할지 의사결정을 해야하기 때문
- 임상시험도 할 수가 없어서 관찰연구 밖에 할 수 없다.
-
Research question: 임신 초기에 HPV 백신을 맞을 경우 안전한가?
- 임신기간 중 HPV 백신은 권장되지 않기 때문에 임상시험을 통해 조사할 수 없음 → 후향적 관찰연구만 가능
- 덴마크의 nationwide register 자료를 이용,
약 7년간 단태아 임신 자료 분석를 분석
-
Outcomes 6가지 분석:
- major birth defect
- spontaneous abortion(유산)
- preterm birth(조산)
- low birth weight(저체중아)
- small size for gestational age
- still birth
-
HPV백신 맞았다 vs 안맞았다
치료군vs대조군 정의먼저 나누는데, 이 논문에서는 특이하게 6개의 outcome마다 치료군의 정의를 다르게 했다.- outcome마다 치료군을 다르게 한 이유: 각 outcome마다 언제 맞은 HPV백신이 영향이 있을 것이다 라는 가설이 각각 달라서 일 것이다.
- 치료군을 5군으로 정의했다 -> 같은 데이터지만, 5번의 다른 분석을 한 것이나 마찬가지 -> 총 5번의
PS matching을 한 것이다. -
치료군정의 : 각 outcome 마다 정의가 달라짐- major birth defect : 임신 초기 12주 내에 HPV 백신을 맞은 사람
- spontaneous abortion : 임신 7주~22주에 HPV 백신을 맞은 사람
- Stillbirth : 임신 7주 이후에 HPV 백신을 맞은 사람
- preterm birth : 임신 37주 이전에 HPV 백신을 맞은 사람
- low birth weight, small size for gestational age : 임신 기간 중 HPV 백신을 맞은 사람
-
대조군정의 : 치료군이 아닌 사람 - 즉, 총 5번의 PS matching을 시행

- 로지스틱 회귀분석을 이용한 PS matching을 했다.
- 백신을 맞을 가능성(propability)를 계산함.
- all baseline characteristics 뿐만 아니라 all two-way
interactions between demographic variables
- 극단적이긴 한데, 모든 인터렉션을 다 포함했다.
- PS model에는 설명변수의 제한이 없기 때문에, 각 특징 이외에 인터렉션까지 포함시켜서 PS matching을 돌림.

- 5개의 outcome에 대해 각각 PS matching을 했는데 1:4비율로 시행함.
- 매칭 수행이
PS score뿐만 아니라. 나이, 임신 시작까지 추가로 넣어서 매칭을 수행했다.

- 오스틴이 추천하는 nearest with caliper의 방법을 썼다.
-
하지만, 이 방법은 PS score 단독으로만 사용될 때 쓸 수 있는 matching이다.
- 앞에 나온 age, calendar year와 부합되지 않는다 -> 약간 걱정됨.
- SMD를 이용해서 평가했다.

- 앞 부분은 생존분석을 통해 분석해서 넘어감
- outcome들에 대해 (이분형 결과변수로 분석했음을 알 수 있는)
로지스틱 회귀분석을 이용해서 prevalenceOR을 구했다.- 앞서 09에서 로지스틱 회귀분석으로 OR을 구해 효과를 추정했었음.
- GEE 방법을 썼다고 했는데
- 매칭을 고려해서 쓴 것은 아니고
-
데이터내 한 여성이 여러번 임신해서 여러번 들어가는 경우, 한 여자에서 나왔으므로 그 데이터들은 독립이 아니기 때문에 독립이 아니다를 보정하기 위해, GEE를 통해 correlation structure를 줘서 보정했다.
- possible correlation between pregnancies within the same mother....
- 매칭을 분석해서 따로 고려하지 않고, 일반적으로 매칭하지 않은 자료로로 분석하되 한 여성이 여러임신한 경우에 대해서만 GEE로 보정했다.
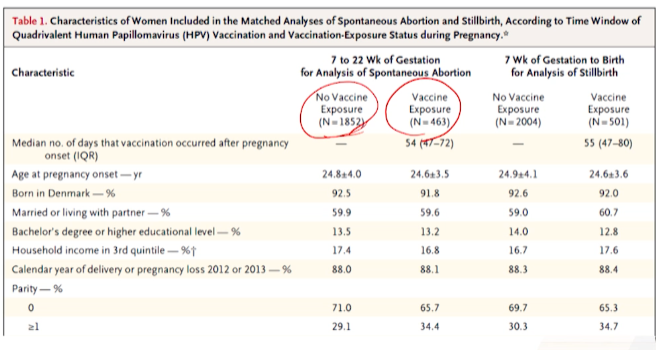
- PS matching을 5번 했는데, 각각에 대해서, 치료군이라고 생각한 군 / 대조군이라고 생각한 군에 기본 환자 특성만 비교한 표이다.
- 요약통계량만 나와있고
- p-value와 SMD를 계산하지 않았다.
- 수치로 2군간의 balance를 평가한 것 같진 않다.
- 앞에 기술에 의해 SMD를 이용했다 했으니, 표에만 표기하지 않은 것 같다.
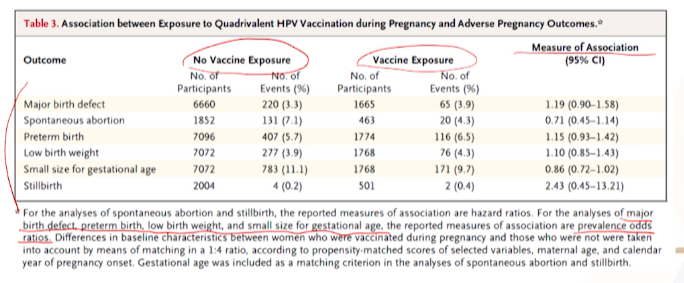
- table 3가 메인 결과인데
- 6가지 outcome들이 나오고
- 임신 중 백신 안맞은 그룹(대조군) vs 백신 맞은 그룹(실험군)을 비교했다.
- outcome마다 군이 달라진다(정의가 달라서)
- 각 군별로 안좋은 outcome의 비율이 요약되어있다.
-
OR이 아니라Measure of Association이라 적혀있는 이유는- outcome들 가운데, 어떤 것은 생존분석 ->
HR로 report - 어떤 것들은
OR로 report 했기 때문일 것이다. - 밑에 주석에 mbd, pb, lbw, ssforg에 대해서만 prevalence OR로 계산했다고 나온다.
- outcome들 가운데, 어떤 것은 생존분석 ->
- Major birth defect의 Measure of Association을 보면
- OR가 1.19에
신뢰구간이 1을 포함한다는 것은2군간 통계적 차이가 유의미하지 않음을 의미한다. - PS matching을 한 뒤, 임신중 HPV 백신여부는 -> Major birth defect발생에 유의하지 않았다. 2군간 차이가 없다.
- OR가 1.19에

- PCI(스텐트)수술과 캐비지(CABG, 관상동맥 우회술)수술을 비교한 논문
- 오래되고 아직도 디베이트 하고 있는 논문
- Research question: multivessel disease 환자에서 CABG와 PCI 중에어느 쪽이 결과가 좋은가?
- CABG : coronary-artery bypass grafting (관상동맥우회술 (수술))
- PCI : percutaneous coronary intervention (관상동맥중재술 (스텐트 시술))
- 기존 연구에서는 second-generation drug-eluting stent로 시술한 PCI를 평가하지 않음
- 당시에...는 새로운 pci수술을 실험함.
- Outcomes 4가지:
- all-cause mortality
- myocardial infarction
- stroke
- repeat revalscularization

- ps matching을 했다.
- 치료여부는 PCI냐 CABG냐 였다
-
PCI받을 확률을PS score로 추정하는 로지스틱 회귀분석을 했다.- nonparsimonious multivariable logistic-regression model : 간단하지 않은 모델 = 설명변수를 아주 많이 넣었다.

- 매칭은 1:1로 했다.
- without replacement = greedy-matching을 했다
- austin 추천방법대로 caliper를 썼다
- SMD를 계산해서 평가했다

- 매칭후 분석은 paired된 점을 고려해서 맥니머 테스트를 했고
- 연속 변수에 대해서는 paired Student’s t-test 를 이용했다
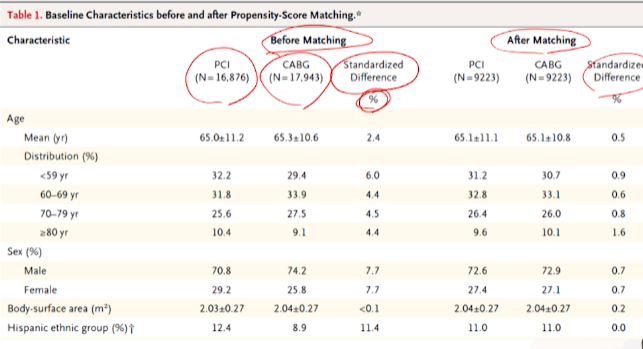
- table1을 보면 깔끔하게 정리되어있다.
- 매칭 전/매칭 후를 일단 나누고
- 매칭 전에는 각 그룹별로 요약통계량 + SMD계산이 됬는데 %로 한 것을 보니 smd x 100을 한 숫자
- %를 고려하면 매칭전 smd(차이)가 그리 크진 않았다.
- 매칭 후에는 확실히 smd가 줄었다.
- 매칭 전에는 각 그룹별로 요약통계량 + SMD계산이 됬는데 %로 한 것을 보니 smd x 100을 한 숫자
- 매칭후 balance가 좋아졌다는 것을 smd로 잘 보여줬다.
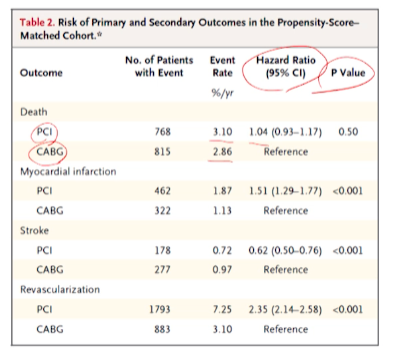
- 메인결과는 각 outcome들에 대해서 pci받은 그룹/cabg받은 그룹에 대해 환자수 / event / hr(생존자료분석) / p-value를 보여준다.
- 지금까지 생존자료분석을 하지 않고 있기 때문에, 배운 이분형 결과변수를 이용한 연구를 찾고 있었는데 없었다.
- ps matching에서는 생존자료분석 -> HR를 report하는 연구가 많음

- IPTW가 어떻게 기술되어있는지 가져온 논문
- 크론병에서 2가지 약(VDZ, 베돌리주맙 vs ADA, 아달이무밥)을 비교한 논문
- 어느 약이 효과가 더 좋은지 연구한 논문
- Research question : 크론병에서 VDZ과 ADA 중 어느 약이 더 효과가 좋은가?
- Sicilian Network for Inflammatory Bowel Disease 데이터를 이용한 관찰 연구
- Outcomes:
- failure-free survival (failure: discontinuation of VDZ or ADA due to AE or inefficacy)
- clinical response: reduction of Harvey-Bradshaw Index ≥3 with concomitant decrease of steroid dosage compared with baseline
- steroid-free clinical remission (Harvey-Bradshaw Index ‹5 without steroid use)
- rate of surgery at the end of FU (intestinal resection + stricturoplasty – perianal surgery)

- 간단하지 않은 모델: 설명변수들에 confounder의심 변수들을 넣었다고 나열해놓음
- 변수들을 넣고, 로지스틱 회귀분석을 통해, PS를 추정함

- 추정한 PS를 가지고, IPTW방법으로 weight를 줬는데, stablilized weights를 줬다.
- 분자에 marginal probability를 곱한 값을 weight로 줬다
- weight를 줘서 2군간의 balance를 맞추고, SMD로 평가했다.

- balance를 맞춘 뒤, 계산한 weight를 가지고 로지스틱을 했다.
- IPTW-adjusted logistic regression analyses
- 생존자료 outcome에서도 CoxPH regression에서도 마찬가지로 weight를 줘서 했다.
- weight를 고려해서 robust standard errors 더 보수적인 방법으로 p-value와 신뢰구간을 계산했다.
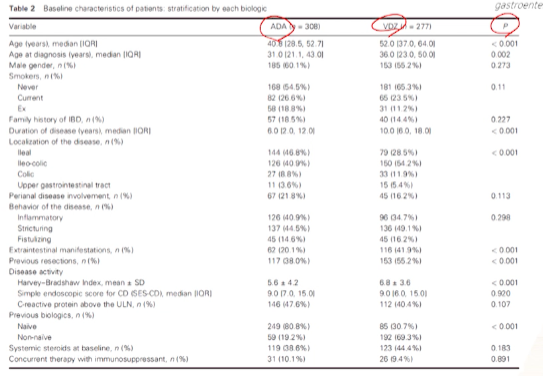
- table2에서 baseline characteristic을 비교했는데
- 2가지 약재에 속한 그룹별로 나와있는데, 여기서 p-value는 쓰는 것이 좋지 않다는 것을 author들이 알고 있었을 것이다. 리뷰어 요청으로 계산한 듯 보인다.
- 그 이유는 SMD를 계산한 그래프를 줬기 때문이다.
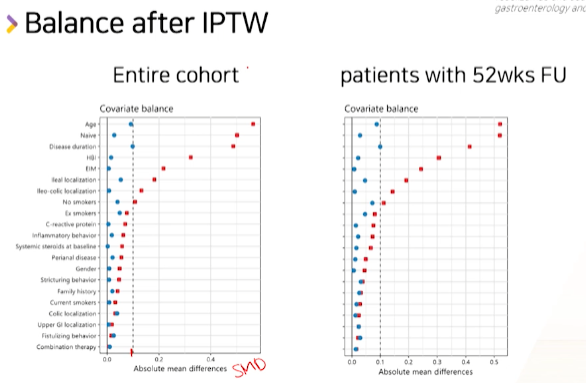
- x축이 Absolute mean difference라 적혀있어서 헤깔리는데, 논문을 읽어보면 SMD임을 알 수 있다.
- 빨간점: 매칭전 SMD
- 파란점: 매칭이후 SMD
- 매칭이후에는 모두 0.1보다 작은 SMD를 보인다.
- 전체 환자에 대해서도 IPTW를 했고, 52주이상 FollowUp된 환자들에 대해서도 IPTW를 계산했다.
- SMD를 표상의 숫자가 아닌 그래프로 balance를 예쁘게 평가했다.
- 변수가 많을 경우, 그래프로 나타내면 예쁘다.
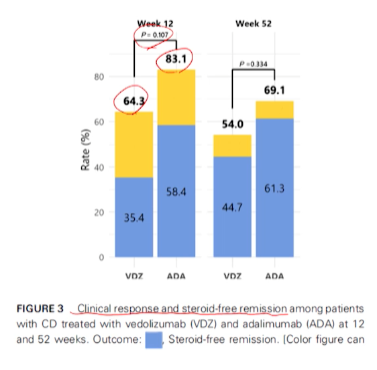
- outcome비교 방법이 OR이 대표적이지만, 여기서는 각 군별로 event ratio를 막대그래프로 직관적으로 보여줬다.
- main으로 본 outcome은 clinical response + steroid-free remission을 합쳐서 -> 둘중에 하나라도 있었는가이다.
- VDZ에서는 event 발생 비율이 64.3
- ADA에서는 event 발생 비율이 83.1
- 그 event 비율의 차이에 대한 p-value는 0.107
- 이러한 방식으로도 2분형 결과변수에 대한 두 군간의 차이를 보여줄 수 있다.
문제점
- “Research question과 명확한 가설 없이 일단 데이터부터
모은다”
- 연구 목적에 맞는 데이터 수집 기회 상실
- 디자인으로 인한 문제는 통계적으로 해결 어려움
- 질 높은 연구가 이루어지기 어려움
- 연구 목적에 맞는 데이터 수집 기회 상실
- “원하는 결과(p<0.05)가 나올 때까지 방법을 바꿔가며 분석한다”
- p-value hacking, data dredging
- 선택적으로 보고된 결과들의 Type I error확률이 유의수준 0.05보다 높아진다
- 결과를 믿을 수 있는 가능성이 높아진다.
- Hurts replicability
- 같은 데이터로 재현은 할 수 있겠지만, 다른 집단에서 다른 연구자가 분석하면 같은 결과가 안나올 가능성이 높아진다.
- 계속 바뀌는 분석방법으로 인한 피로도, 실수 가능성이 높아진다
- p-value 중심 연구 방식 자체의 문제
- p-value는 통계적 유의성만 알려주며, 이것은 임상적 유의성과는 완전히 다르다
- 귀무가설 기각 여부에 의해 Pass or fail로 나뉘는 dichotomy의 문제
- Propensity score(PS)를 추정한 후 분석하는 방법 중, stratification은 PS 가 비슷한 환자들끼리 strata를 나누어 분석한 후 그 결과를 합치는 방법이다.
- Inverse probability of treatment weighting(IPTW) 방법은 치료군은 1/PS, 대조군은 1/(1-PS)의 weight를 주어 분석하는 방법이다.
- Covariate adjustment는 outcome model에 PS를 공변량으로 넣는 방법 이다.
- 임상연구를 수행할 때에는 research question과 가설을 먼저 세우고 그에 맞 는 연구 계획을 세운 후, 계획한 방법으로 데이터 수집과 분석을 실시해야한다.
- 원하는 결과가 나올 때까지 분석 방법을 바꾸어 하며 p-value hacking을 하 는 것은 Type I error 확률을 높이며, 연구 재현성을 해친다.
01 다음 Propensity score analysis 방법 중, 데이터에 weight를 주어서 치료군과 대조군의 baseline covariates의 분포의 차이를 제거하는 방법은?
-
Matching
-
Stratification
-
Inverse probability of treatment weighting
-
Covariate adjustment
- 정답 : 3
- 해설 : IPTW 방법은 치료군에 1/PS, 대조군에 1/(1-PS)의 weight를 주어, weighted data에서 치료군과 대조군 간 PS 값이 분포가 비슷하게 만들고, 결과적으로 baseline covariates의 분포가 두 군간에 비슷해지게 만드는 방법이다.