파이썬을 파이썬답게 노트정리
프로그래머스 실습강의를 정리한 노트입니다.



📜 제목으로 보기✏마지막 댓글로
- 출저
- 공부 이유
- 정수 (2)
- 문자열 (2)
- iterable 다루기 (4)
- Sequence Types 다루기 (2)
- Itertools / Collections 모듈 (4)
- 기타 (7)
출저
- 파이썬을 파이썬답게 실습강의를 듣고 느낀점과 함께 풀어낸 노트입니다.
공부 이유
-
정수를 담은 이차원 리스트, mylist 가 solution 함수의 파라미터로 주어집니다. mylist에 들은 각 원소의 길이를 담은 리스트를 리턴하도록 solution 함수를 작성해주세요.
- 제한 조건
- mylist의 길이는 100 이하인 자연수입니다.
- mylist 각 원소의 길이는 100 이하인 자연수입니다.
-
위 문제를 아래와 같이 짰다면, 수강해야한다.
나는 list comp로 짬
-
아래와 같은 풀이는 c언어 or 자바 풀이임.
-
이것과 같이 짜야함

- 용어 설명
-
iterable: 자신의 멤버를 한 번에 하나씩 리턴할 수 있는 객체입니다. list, str, tuple, dict 등이 여기에 속합니다. -
sequence: int 타입 인덱스를 통해, 원소에 접근할 수 있는 iterable 입니다.- iterable의 하위 카테고리라고 생각하시면 됩니다.
- list, str, tuple이 여기 속합니다. ( dictionary는 다양한 타입을 통해 원소에 접근할 수 있기 때문에 sequence에 속하지 않습니다.)
-
unpacking: 적절한 번역을 찾고 있습니다.
-
input_ = '5 3'
num_ = input_.strip().split(' ')
a, b = [int(x) for x in num_]
str(a//b) + ' ' + str(a%b)
a, b = map(int, input_.strip().split(' '))
a
b
divmod(a, b) # 순서대로 몫, 나머지를 반환함.
print(*divmod(a, b)) #unpakcking을 print하면, 각각을 공백으로 나누어서 프린트해준다.
문제 설명
base 진법으로 표기된 숫자를 10진법 숫자 출력해보세요.
입력 설명
입력으로는 공백으로 구분된 숫자가 두 개 주어집니다.
첫 번째 숫자는 num을 나타내며, 두 번째 숫자는 base를 나타냅니다.
출력 설명
base 진법으로 표기된 num을 10진법 숫자로 출력해보세요.
제한 조건
base는 10 이하인 자연수입니다.
num은 3000 이하인 자연수입니다.
예시
input output
12 3 5
444 5 124
입출력 예 설명
입출력 예 1
3진법으로 표기된 12는 10진법으로 표현하면 5입니다. ( 1*3 + 2 )
입출력 예 2
5진법으로 표기된 444는 10진법으로 표현하면 124입니다. ( 455 + 4*5 + 4 )num, base = map(int, input().strip().split(' '))
div_sum = 0
for n in sorted(range(0, len(str(num))), reverse=True):
k, num = divmod(num, 10**(n))
div_sum += k * (base**(n))
print(div_sum)
n진법으로 표기된 string을 10진법 숫자로 변환하기 - int 함수
진법 변환 문제는 알고리즘 문제나 숙제로 자주 나오는 유형이지요. 이번 시간에는 n 진법으로 표기된 문자열을 10진법 숫자로 변환하는 방법을 배워봅시다.
예시) 5진법으로 적힌 문자열 '3212'를 10진법으로 바꾸기
다른 언어에서는..(또는 이 기능을 모르시는 분은) 보통 사람들은 for 문을 이용해 숫자를 곱해가며 문제를 풉니다.
num = '3212'
base = 5
answer = 0
for idx, number in enumerate(num[::-1]):
answer += int(number) * (base ** idx)
파이썬에서는 파이썬의 int(x, base=10) 함수는 진법 변환을 지원합니다. 이 기본적인 함수를 잘 쓰면 코드를 짧게 쓸 수 있고, 또 시간을 절약할 수 있습니다.
num = '3212'
base = 5
answer = int(num, base)
느낀점(enumerate, int( , base), 문자열도 sequence, [::-1])
- 순서가 필요한 list나 문자열은 enumerate를 활용하자. ex> 진법변환 계산
- 뒤에서부터 시작을 꼭 sorted( ,reverse=True)에 집착X iterable전용인 문자열, array, dataframe등을 생각할 때 [::-1]을 활용하자.
- 문자열도, list처럼 sequence이다. (flat
containerimmutablemutable) -> 인덱싱으로 꺼꾸로 시작하게 할 수 있다.
- 문자열도, list처럼 sequence이다. (flat
- 파이썬에서는 진법변환함수를 int( , base)로 제공한다. 필요하다면 쓰자.
- 진법변환시 첫자리부터 하지말고, str()+ [::-1]을 활용해 일의 자리에서부터 풀자
num = '432'
base = '5'
# 일의 자리부터 풀어보자. + enumerate로 번호를 줘가면서 풀어보자.
num[::-1]
answer = 0
for idx, number in enumerate(num[::-1]):
answer += int(number) * ( int(base) ** (idx) )
answer
# base진법으로 표기된 string num을 -> 10진법 숫자(int())변환
answer = int(num, base=int(base))
answer
문제 설명
문자열 s와 자연수 n이 입력으로 주어집니다. 문자열 s를 좌측 / 가운데 / 우측 정렬한 길이 n인 문자열을 한 줄씩 프린트해보세요.
제한조건
s의 길이는 n보다 작습니다.
(n - s의 길이)는 짝수입니다.
s는 알파벳과 숫자로만 이루어져 있으며, 공백 문자가 포함되어있지 않습니다.s, n = input().strip().split(' ')
n = int(n)
space_num = n-len(s)
print(s+' '*space_num)
print(' '*(space_num//2)+s+' '*(space_num//2))
print(' '*space_num+s)
# -> answer ='' 빈 문자열에 공백의 갯수만큼 돌면서(반복작업용for) 누적합으로 공백을 채운다.
s = '가나다라'
n = 7
answer = ''
for i in range(n-(len(s))):
answer+=' '
answer+=s
answer
s = '가나다라'
n = 7
s.ljust(7)
s.center(7)
s.rjust(7)
ord('a')
chr(97)
chr(122)
chr(65), chr(90)
answer = ''
for i in range(65, 90+1):
answer+=chr(i)
print(answer)
num = int(input().strip())
answer = ""
if num:
# num이 0이면, 소문자로
# ord('a') = 97 -> z ->122
for i in range(65, 90+1):
answer+=chr(i)
else:
for i in range(97, 122+1):
answer+=chr(i)
print(answer)
import string
string.ascii_lowercase # 소문자 abcdefghijklmnopqrstuvwxyz
string.ascii_uppercase # 대문자 ABCDEFGHIJKLMNOPQRSTUVWXYZ
string.ascii_letters # 대소문자 모두 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
string.digits # 숫자 0123456789
num = int(input().strip())
# answer = ""
if num:
# num이 0이면, 소문자로
# ord('a') = 97 -> z ->122
#for i in range(65, 90+1):
# answer+=chr(i)
print(string.ascii_uppercase)
else:
#for i in range(97, 122+1):
# answer+=chr(i)
print(string.ascii_lowercase)
# print(answer)
느낀점(str.lower(), upper() -> string상수, string모듈.ascii_ , string모듈.digits, )
- string모듈이란 것이 따로 있고, 소문자모음, 대문자모음, 소->대문자모음, 숫자모음을 상수로 제공한다.
- string.ascii_lowercase # 소문자 abcdefghijklmnopqrstuvwxyz
- string.ascii_uppercase # 대문자 ABCDEFGHIJKLMNOPQRSTUVWXYZ
- string.ascii_letters # 대소문자 모두 abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
- string.digits # 숫자 0123456789
- 다른 사람 풀이를 보고선
- chr(), ord()를 안써도되고
- 소문자만 or 대문자만 작성해서 str.lower() / str.upper() 메소드도 활용하자.
파이썬의 sort() 함수를 사용하면 리스트의 원소를 정렬할 수 있습니다. 이때, sort 함수는 원본의 멤버 순서를 변경하지요. 따라서 원본의 순서는 변경하지 않고, 정렬된 값을 구하려면 sort 함수를 사용할 수 없습니다.
이런 경우는 어떻게 해야 할까요?
다른 언어에서는..(또는 이 기능을 모르시는 분은) 보통 사람들은 deep copy와 sort 함수를 이용합니다.
list1 = [3, 2, 1]
list2 = [i for i in list1] # 또는 copy.deepcopy를 사용
list2.sort()
파이썬에서는 파이썬의 sorted를 사용해보세요. 반복문이나, deepcopy 함수를 사용하지 않아도 새로운 정렬된 리스트를 구할 수 있습니다.
list1 = [3, 2, 1]
list2 = sorted(list1)
(쳌) 2차원 리스트 뒤집기 ( transpose문제, 어려움 )
다음을 만족하는 함수, solution을 완성해주세요.
solution 함수는 이차원 리스트, mylist를 인자로 받습니다
solution 함수는 mylist 원소의 행과 열을 뒤집은 한 값을 리턴해야합니다.
예를 들어 mylist [[1, 2, 3], [4, 5, 6], [7, 8, 9]]가 주어진 경우, solution 함수는 [[1, 4, 7], [2, 5, 8], [3, 6, 9]] 을 리턴하면 됩니다.
제한 조건
mylist의 원소의 길이는 모두 같습니다.
mylist의 길이는 mylist[0]의 길이와 같습니다.
각 리스트의 길이는 100 이하인 자연수입니다.mylist = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
mylist[::-1]
# 1x1 -> 1
# 2x2 -> 3
# 3x3 -> 5
# nxn -> 2n-1 line
# 각 k in 2n-1 마다..
# k=1, -> 길이 1 0.0
# k=2, -> 길이 2 1.0 0.1
# k=3, -> 길이 3 2.0 1.1 0.2
# k=4, -> 길이 2
# k=5, -> 길이 5
# gg
# 타 문제에서는 각 행마다 길이가 같다는 보장이 없기 때문???
이번 강의에서는 zip 함수를 이용해 2차원 배열을 뒤집는 방법을 알아봅시다.
다른 언어에서는..(또는 이 기능을 모르시는 분은)
보통은 다음과 같이 2중 for 문을 이용해 리스트의 row와 column을 뒤집습니다.
[[]]*4
[[]]*len(mylist)
mylist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = [[], [], []]
for i in range(len(mylist)):
for j in range(len(mylist[i])):
new_list[i].append(mylist[j][i])
new_list
mylist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# new_list = [[], [], []]
# new_list = [[]]*3 # 주의! 안에 요소가 콤마로 붙는다고 해서 list바깥에서 *3 하지말 것. id똑같은놈들임.
# new_list = [[] for x in range(len(mylist))]
for i in range(len(mylist)):
for j in range(len(mylist)):
if i > j:
mylist[j][i], mylist[i][j] = mylist[i][j], mylist[j][i]
mylist
mylist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = list(map(list, zip(*mylist)))
느낀점( zip(*매핑 2차원 리스트) -> 각 행들마다 1개씩 뽑아 tuple로 )
- 행렬(2차원리스트)를 *매핑해서 zip()에 던져주면, 각 행들을 zip(a,b,c,...,n_rows)로 판단해서 나눠쓴다.
- 즉, for문으로 받을 때는 각 행마다 0열요소들 / 1열 요소들 / ... 들이 튜플로 모여서 들어온다.
- 번역 : zip(*iterables)는 각 iterables 의 요소들을 모으는 이터레이터를 만듭니다.
-
튜플의 이터레이터를 돌려주는데, i 번째 튜플은 각 인자로 전달된 시퀀스나 이터러블의 i 번째 요소를 포함합니다.
-
- 즉, 각 iter들(*매핑리스트시 - 각행들)의 요소를 하나씩 빼와서
튜플형태로 반환한다.i번째 튜플은각 데이터(행)의 i번째열들의 모아아두었다. - 길이가 다르면, 짧은 데이터를 기준으로 끝난다.
- 원래 집은 **zip으로 튜플
들을 반환한다. 꼭 튜플 리스트가 아니더라도 2개의 짝을 이룬 튜플요소들이 반환되면 dict로 반환 가능하다.- for문에서는 zip이 반환하는 tuple을 언패킹하는 것일 뿐
print(mylist)
#[[*1*, 2, 3],
# [*4*, 5, 6],
# [*7*, 8, 9]]
zip(*mylist)
list(zip(*mylist)) # 각 행마다 같은 열들을 튜플로 묶어서, 마치 대각선으로 transpose된다.
list(map(list, zip(*mylist))) # zip으로 만들어진 transpose 튜플 리스트를 map으로 각 요소 list로 변환한다.
print('mylist', mylist)
print('*mylist', *mylist) # 함수에 튜플이나 리스트를 매핑해주면, 알아서 나눠서 쓴다는 의미다.
# 인자로 대입한다면, 콤마로 나눠서 넣어줘야한다. (튜플, 리스트로 인자대입X)
list(zip(*mylist))
list1 = [1, 2, 3, 4, 5]
list2 = [100, 120, 30, 300]
list3 = [392, 2, 33]
answer = []
for number1, number2, number3 in zip(list1, list2, list3):
print(number1 + number2 + number3)
# 짝을 이룬 튜플리스트는 dict로 변환가능하다!
animals = ['cat', 'dog', 'lion']
sounds = ['meow', 'woof', 'roar']
# print(list(zip(animals, sounds)))
dict(zip(animals, sounds))
숫자를 담은 리스트 mylist가 solution 함수의 파라미터로 주어집니다. solution 함수가 mylist의 i번째 원소와 i+1번째 원소의 차를 담은 일차원 리스트에 차례로 담아 리턴하도록 코드를 작성해주세요.
단, 마지막에 있는 원소는 (마지막+1)번째의 원소와의 차를 구할 수 없으니, 이 값은 구하지 않습니다.
제한 조건
mylist의 길이는 1 이상 100 이하인 자연수입니다.
mylist의 원소는 1 이상 100 이하인 자연수입니다.
예시
mylist output
[83, 48, 13, 4, 71, 11] [35, 35, 9, 67, 60]
설명:
83과 48의 차는 35입니다.
48과 13의 차는 35입니다.
13과 4의 차는 9입니다.
4와 71의 차는 67입니다.
71과 11의 차는 60입니다.
따라서 [35, 35, 9, 67, 60]를 리턴합니다.def solution(mylist):
return [abs(mylist[i] - mylist[i+1]) for i in range(len(mylist)-1)]
def solution(mylist):
answer = []
for number1, number2 in zip(mylist, mylist[1:]):
answer.append(abs(number1 - number2))
return answer
모든 멤버의 type 변환하기
문제 설명
문자열 리스트 mylist를 입력받아, 이 리스트를 정수형 리스트로 바꾼 값을 리턴하는 함수, solution을 만들어주세요. 예를 들어 mylist가 ['1', '100', '33'] 인 경우, solution 함수는 [1, 100, 33] 을 리턴하면 됩니다.
제한조건
mylist의 길이는 100 이하인 자연수입니다.
mylist의 원소는 10진수 숫자로 표현할 수 있는 문자열입니다. 즉, 'as2' 와 같은 문자열은 들어있지 않습니다.
예시
input output
['1', '100', '33'] [1, 100, 33]def solution(mylist):
return [ int(x) for x in mylist ]
list1 = ['1', '100', '33']
list2 = list(map(len, list1))
list2
문제 설명
정수를 담은 이차원 리스트, mylist 가 solution 함수의 파라미터로 주어집니다. solution 함수가 mylist 각 원소의 길이를 담은 리스트를 리턴하도록 빈칸을 완성해보세요.
hint) 이전 강의에서 배운 map 함수를 활용해보세요
제한 조건
mylist의 길이는 100 이하인 자연수입니다.
mylist 각 원소의 길이는 100 이하인 자연수입니다.
예시
input output
[[1], [2]] [1, 1]
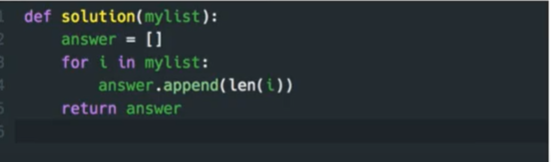
[[1, 2], [3, 4], [5]] [2, 2, 1]def solution(mylist):
answer = list(map(len, mylist))
return answer
문자열 리스트 mylist를 입력받아, 이 리스트의 원소를 모두 이어붙인 문자열을 리턴하는 함수, solution을 만들어주세요. 예를 들어 mylist가 ['1', '100', '33'] 인 경우, solution 함수는 '110033'을 리턴하면 됩니다.
제한 조건
mylist의 길이는 100 이하인 자연수입니다.
mylist의 원소의 길이는 100 이하인 자연수입니다.my_list = ['1', '100', '33']
answer = ''
for value in my_list:
answer += value
my_list = ['1', '100', '33']
answer = ''.join(my_list)
문제 설명
이 문제에는 표준 입력으로 정수 n이 주어집니다.
별(*) 문자를 이용해 높이가 n인 삼각형을 출력해보세요.
제한 조건
n은 100 이하인 자연수입니다.
예시
입력
3
출력
*
**
***n = int(input().strip())
for i in range(1,n+1):
print(('*'*i).ljust(n))
n = int(input().strip())
for i in range(1,n+1):
print(('*'*i).center(n))
answer = ''
n = 5
for _ in range(n):
answer += 'abc'
print(answer)
# - sequence라 * 연산을 희한하게 한다.
answer = 'abc' * n
answer
n = 3
answer= [123, 456] * n
print(answer)
answer[3]=3
answer
iterable1 = 'ABCD'
iterable2 = 'xy'
iterable3 = '1234'
for value1 in iterable1:
for value2 in iterable2:
for value3 in iterable3:
print(value1, value2, value3)
# itertools.product를 이용하면, for 문을 사용하지 않고도 곱집합을 구할 수 있습니다.
import itertools
iterable1 = 'ABCD'
iterable2 = 'xy'
iterable3 = '1234'
print(list(itertools.product(iterable1, iterable2, iterable3)))
itertools.product(iterable1, iterable2, iterable3)
import itertools
iter1 = list('ABCD')
iter2 = '조재성 조재경 조아라'.split(' ')
iter3 = '1234'
print(itertools.product(iter1)) # 1개의 iter도 받으며, list()로 변환해야 보인다.
print(list(itertools.product(iter1))) # 1개의 iter도 받으며, list()로 변환해야 보인다.
print(list(itertools.product(iter1, iter2))) # 2개의 iterable객체를 넣은 순간부터, 곱집합 튜플들의 리스트가 나온다.
# 2중 for문을 도는 효과다.
[ a + b + c for a,b,c in itertools.product(iter1, iter2, iter3)][:5]
느낀점( itertools.product(iter1, 2, 3) -> 중첩for 반복을 제거 + 순서대가 정해진 조합이다.)
- itertools.product의 결과물은 list()를 씌워야 튜플 리스트로 들어온다.
- 1개의iter를 넣어도 (a, ) (b, )의 튜플형태로 받는다.
- zip은 i, i+1, 같은 위상의 iter들을 동시에 받거나 *2차원리스트 등을 받아서 -> 1차원으로 동시에 처리
- itertools.product는 for iter1, for iter2처럼, 누적해서 곱집합을 처리한다.
- 문자열도 iter로 인식하여 한 문자씩 돌아간다.
def solution(mylist):
answer = []
for list_ in mylist:
for li in list_:
answer.append(li)
return answer
my_list = [[1, 2], [3, 4], [5, 6]]
[ li for list_ in my_list for li in list_ ]
# 빈리스트[]에 +로 <<괄호떼고>>누적합으로 이어붙이기
.
my_list = [[1, 2], [3, 4], [5, 6]]
answer = []
for element in my_list:
answer += element
answer
sum(my_list, [])
print(itertools.chain.from_iterable( my_list ) )
list(itertools.chain.from_iterable( my_list ) )
# itertools.chain()은 여러 1차 iterable(1글자씩조합-문자열 or list 등)을 분해해서
# -> 통합한 1차 iterable을 만든다.
list(itertools.chain('ABC', ['abc',2,3], 'F'))
list(itertools.chain(my_list))
list(itertools.chain(*my_list))
- 파이썬 * 의 사용 (https://mingrammer.com/understanding-the-asterisk-of-python/)
- 곱셈 및 거듭제곱 연산으로 사용할 때
- 리스트형 컨테이너 타입의 데이터를 반복 확장하고자 할 때
- 가변인자 (Variadic Arguments)를 사용하고자 할 때 -> 인자시 패킹(내부에서는 *떼고 묶어서 써줘)
- 컨테이너 타입의 데이터를 Unpacking 할 때 -> 사용시언패킹(알아서 쪼개줘)
from functools import reduce
primes = [2, 3, 5, 7, 11, 13]
def product(*numbers):
p = reduce(lambda x, y: x * y, numbers)
return p
product(*primes) # product() 함수가 <이미 내부에서> 가변인자를 받고 있기 때문에,
# 실제 입력시에는 콤마로 언패킹상태로 리스트의 데이터를 모두 unpacking하여 함수에 전달해야한다.
# -> 인자가 패킹하고있다면, 실제 대입은 콤마, , ,로 나눠서 주던지 *iterable로 알아서 처리하라고 넘겨주면 된다.
# 30030
product(primes) # XXXXXXXXXX -> 콤마로 줘야할 곳을 list로 주고 있다. *list로 하면 콤마로 알아서 입력해줘다.
# [2, 3, 5, 7, 11, 13]
list(itertools.chain.from_iterable( my_list ))
from functools import reduce
reduce(lambda x, y: x+y, my_list)
from operator import add
reduce(add, my_list)
느낀점( 2차원 : [ ] for += 괄떼이어붙이기 / sum( , start =[ ]) / 한꺼풀 : itertools.chain(*)과 자동 2꺼풀: chain.from_iterable() / reduce(lambda x,y:x(list)+(new_list), <--2차원리스트)
- 가장 단순하게 2중 for문 or 2중 list comp로 element까지 가는 것
- 비 파이썬이라도 빈_list[ ]에 for문 1개의 list element에서
append가 아닌빈_list += 괄호떼고 이어붙이기 - 내장sum(iter)함수에 , start=값을 default 0이 아닌 빈 []에다가 iter각 요소(2차원->1차원 리스트들)누적되도록 !
sum(iter , start = [] ) - itertools.chain( 1차원or문자열 iterable1 , iter2, ... ) -> 문자열은 1개씩 풀어서, list는 element단위로 풀어서 1차원 iterable로 통합
- itertools.chain()은 여러 1차 iterable들을 각각 분해하여 각각 한꺼풀만 벗겨, 통합한 1차 iterable을 만든다.
- 2차원을 넣으면 그대로 2차원 반환됨. 한 꺼풀만 벗겨서 다시 통합하므로 -> chain(*2차원)으로 사용시언패킹 시켜주자
- %timeit 결과를 보면 sum()함수만 끔찍하게 느리고 나머지 셋은 고만고만함을 알 수 있다. 성능과 가독성 중 무엇을 중시하냐의 차이지만 개인적으로 itertools.chain() 자체도 가독성이 나쁘다고 볼 수 없기에 sum()보다는 chain()을 쓰지 않을까 싶다.
- reduce도 각 데이터 요소들이 와서 연산하는데 lambda로 +연산 or operator.add를 사용해서 list들이 += 누적합이 되도록 해주면 된다.
from itertools import permutations
sorted(list(permutations([2, 1,3], 2)))
문제 설명
숫자를 담은 일차원 리스트, mylist에 대해 mylist의 원소로 이루어진 모든 순열을 사전순으로 리턴하는 함수 solution을 완성해주세요.
제한 조건
mylist 의 길이는 1 이상 100 이하인 자연수입니다.
예시
mylist output
[2, 1] [[1, 2], [2, 1]]
[1, 2, 3] [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]from itertools import permutations
sorted(list(permutations([2, 1,3],2)))
# # - 자기자신의 index와 value가 같아지는 순간까지만 반복되다가, 다음 index로 넘어가서 반복된다.
# # - index가 더크면, 값+1 index 초기화후
# # - 값이 더크거나 같으면, <인덱스+1> 값 초기화
# # my) 값을 인덱스랑 같아질때까지 늘려주는데, 값 증가시 그때마다 i=0부터 시작.. -> 같아지면 index+1 값은 0
# # my) index가 n-1까지 = arr갯수까지만 시행.
# # - 그럼, 0` [0`,0] -> `1 [0,`0] -> `0 [`0,1] -> `1 [0, `1] -> 2 [0, 0] -> 조건위배 while중지
# def permute_first(arr):
# result = [arr[:]]
# c = [0] * len(arr)
# i = 0
# while i < len(arr):
# print(i, c, arr, result)
# # 1. i번째 데이터가 자기 순서(i)보다 값이 작다? 1증가시키고, 처음부터 돌려라.
# if c[i] < i :
# c[i] +=1 # 값을 +1
# i = 0 # index를 0부터 다시 시작.
# # 2. i번째 데이터가 자기 순서(i)보다 크거나 같다? 값을 초기화시키고, 다음 index순서로 넘어가라
# else:
# c[i] = 0
# i+=1
# permute_first([0,0])
# # my) 값을 인덱스랑 같아질때까지 늘려주는데, 값 증가시 그때마다 i=0부터 시작.. -> 같아지면 index+1 값은 0
# # my) index가 n-1까지 = arr갯수까지만 시행.
# # - 그럼, 0` [0`,0] -> `1 [0,`0] -> `0 [`0,1] -> `1 [0, `1] -> 2 [0, 0] -> 조건위배 while중지
# # 3. 인덱스가 짝수면, arr[0]번째 값과 해당 index값 arr[i] swap한다.
# def permute_two(arr):
# result = [arr[:]]
# c = [0] * len(arr)
# i = 0
# while i < len(arr):
# print(i, c[i], c, arr)
# if c[i] < i :
# # 3. 인덱스가 짝수면, 원본 0번째 값 현재(짝수번째) 값을 교환.
# if i % 2 ==0:
# arr[0], arr[i] = arr[i], arr[0]
# c[i] +=1
# i = 0
# else:
# c[i] = 0
# i+=1
# permute_two([0,1,4])
# result = [arr[:]]
# c = [0] * len(arr)
# i = 0
# while i < len(arr):
# print(i, c[i], c, arr)
# if c[i] < i :
# # 3. 인덱스가 짝수면, 0번째 값과, 짝수번째 값을 교환.
# if i % 2 ==0:
# arr[0], arr[i] = arr[i], arr[0]
# # 4. 인덱스가 홀수면, [c list의 i번째 값]을 index로 넣고, 데이터 홀수번재 값을 교환
# else:
# arr[c[i]], arr[i] = arr[i], arr[c[i]]
# c[i] +=1
# i = 0
# else:
# c[i] = 0
# i+=1
# permute_three([0,1,4])
# # - 값이 index랑 같아지는 부분은 횟수를 늘리는 용도일 뿐이라는 말이다.
# def permute_four(arr):
# result = [arr[:]] # 2차원에 1번째 행을 원본을 넣어놓는다.
# c = [0] * len(arr)
# i = 0
# while i < len(arr):
# print(i, c[i], c, arr)
# if c[i] < i :
# # 3. 인덱스가 짝수면, 0번째 값과, 짝수번째 값을 교환.
# if i % 2 ==0:
# arr[0], arr[i] = arr[i], arr[0]
# # 4. 인덱스가 홀수면, [c list의 i번째 값]을 index로 넣고, 데이터 홀수번재 값을 교환
# else:
# arr[c[i]], arr[i] = arr[i], arr[c[i]]
# # 5. arr결과를 result 2차원 리스트(원본을 1행에 가지고 있던 놈)에 append한다.
# # - c[i]가 0에서부터 불들어오는 순간부터 교환후 들어올리네.
# result.append(arr[:])
# c[i] +=1
# i = 0
# else:
# c[i] = 0
# i+=1
# # 6. result 2차원 리스트를 반환한다.
# return result
# permute_four([1,2,3])
def permute(arr):
result = [arr[:]]
c = [0] * len(arr)
i = 0
while i < len(arr):
if c[i] < i:
if i % 2 == 0:
arr[0], arr[i] = arr[i], arr[0]
else:
arr[c[i]], arr[i] = arr[i], arr[c[i]]
result.append(arr[:])
c[i] += 1
i = 0
else:
c[i] = 0
i += 1
return result
arr = [0,1,2,3]
r = 2
# def permutation(arr, r):
# 1. used(list) : 해당index의 원소 사용 여부 : arr의 길이만큼 빈 [0] * n를 만들자.
# - used(list)에는 해당index의 값이 사용됬는지 안됬는지 체크여부.
# - 누적합이 아니라도 여부 등은 0 default에서 1 왔다갔다 하면, if문에 False, True로 걸린다.
# used = [0] * len(arr)
used = [0 for _ in range(len(arr))]
# 2. generate( chosen, used ): 함수로 만들어야 -> 내부에서 같은 로직을 한번 더 호출할 수 있다.
# - 일단, 빈 list를 던져주고, 사용여부에 따라 append한 다음, 길이가 원하는 순열길이(r)과 같아졌다면 함수를 끝내는 return해준다.
# generate([], used) 형태로 사용된다.
def generate(chosen, used):
# 2-1) default [] chosen이 원하는 길이를 만족했으면 -> 탈출 -> 그전까지는 내부함수 호출로 반복됨.
if len(chosen) == r:
print(chosen) # 결과값 저장대신 각각 만들어진 경우를 print한다.
return
# 2-2) arr길이만큼 반복 -> used의 길이랑 arr이랑 같으며, 같이 움직이니까.
# arr와 같은 길이의 used는 arr[i]의 사용여부체크시 used[i]를 사용하는 위에 떠있는 데이터
for i in range(len(arr)):
# i번째 원소가 아직 사용이 안됬다?
print('used', used)
if not used[i]:
# 사용후 -> 사용표시 1
# - 일단 사용안된 i번째 요소를 chosen에 넣고, 사용했다는 표기를 한다.
print('chosen', chosen)
chosen.append(arr[i])
used[i]=1
# i번재 데이터가 담기고 + 사용되었다는 표시와함께 다시 호출하면
# - 재귀적? 반복적으로... i를 제외하고 사용안된 i를 =1,2,3,4에서부터 찾기..전에...
generate(chosen, used)
# 내부에서, 길이 못채웠고 & 사용된것 넘어가면서 사용안된 것을 j를 0에서부터 찾는다.
# 내부에서, 0은 used[0]이 이미 담겨있으니, 1을 chosen에 넣고, 0,1,을 넣은 상태에다.
# 내부에서 또 내부함수가 호출되지만, 초기검사에서 r==2를 만족시켜 반환되며
# 내부j에서는, used[j] = 0을 넣고, 안썼다고 표시 + 데이터도 뺀 체로, j=1이 된다.
# i=0는 고정상태에서 j=0을 쓴 뒤, j=1을 쓰고, r==2가 만족되면 j=2로 간다...
# i 고정 -> j를 돌면서 -> k에서 갯수가 맞추다가,, j를 다돌면, i가 도나보다...
used[i] = 0
chosen.pop()
# 재귀를 써서 구하는데
# base case가 chosen == r(input)을 맞추면 끝난다...
# 이 함수의 핵심이다. 모든 순열은 arr 의 0부터 i-1 번째 값으로 시작하기에 for 문으로 다 만들어야 한다.
# recusive case는 nPr = 시작자리에 arr[i] 가 들어갔다고 치면(for를 n번) = N * n-1Pr 이다.
# permutation([0,1,2,3], 2) =
# ([0],permutation([1,2,3], 1)) + ([1],permutation([0,2,3], 1)) + ([2],permutation([0,1,3], 1))+ ([3],permutation([0,1,2], 1))
# combination([0,1,2,3], 2) = ([0],combination([1,2,3], 1)) + ([1],combination([2,3], 1)) + ([2],combination([3], 1)))
# https://cotak.tistory.com/70
def permutation(arr, r):
# 1.
arr = sorted(arr)
# 해당원소가 사용되고 있는 상태인지 arr와 같은길이의 0과 1로 구성될 list 생성
# - 재귀로 내부에서 함수가 또 불려질텐데, 내부함수가 밖에서 어떤 원소가 고정된 상탠지 알려주기 위해
# - 함수 입장에서 전역변수로 만들어준다.
used = [0 for _ in range(len(arr))]
def generate(chosen, used):
# 2.재귀에서 탈출부이다. chosen이 원하는 갯수 r개가 되면 base case로 print하고 해당함수는 끝난다.
# - 내부함수들이 끝나는 것이기에... 어느것이 끝나는지는...
if len(chosen) == r:
print(chosen)
return
# 3.i번째를 고정시킨 상태에서,
# - i에 불이 안들어와있는 상태다 = 가장 바깥은 필요없지만.. 내부함수들은 바깥에서 고정된 것이기에 피해야한다.
for i in range(len(arr)):
# 사용했다는 불이 안들어온 상태다. 내부함수가 인식하도록, 내부함수호출직전에 켜주고, 직후에 꺼준다.
# 맨바깥은 for로 알아서 i가 돌아가고 있기 때문에 노상관. 내부에서 i불들어온 것 제끼고 r-1개 맞추라는 신호임.
if not used[i]:
# 4. 내부함수가 i원소를 채운 상태로 재귀호출하도록 넣어주고, 불을 켜준다.
chosen.append(arr[i])
used[i] = 1
generate(chosen, used) # 재귀상태로, 1개를 채운상태에서 r-1를 채우려고 호출된다.
# 5. i고정상태에서 r-1개를 다채워 r개를 완성했다는 뜻이니, 불을 꺼주고, 빼준다.
used[i] = 0
chosen.pop()
# 6. 자동으로 다음 i가 고정되서 시작한다.
generate([], used)
permutation('ABCD', 2)
# 출처: https://cotak.tistory.com/70 [Pool's Taek]
def gen_permutations(arr, n):
result = []
if n == 0:
return [[]]
for i, elem in enumerate(arr):
# i번재 원소만 빼고, 대신 n-1개만 나머지로 순열 부분문제 정복상태 -> 각 요소들P
for P in gen_permutations(arr[:i] + arr[i+1:], n-1):
# i번째 원소를 맨마지막에 extend해서 붙임.
# [[2]]
# [[1, 2]]
# [[0, 1, 2]]
# [[0, 1, 2]]
# 순열도 제일 마지막에 첨가하면, 조합처럼 n-1개 완성 + 1개요소(n가지)가 된다?
result += [[elem]+P]
print(result)
break
return result
arr = [0, 1, 2, 3, 4, 5]
print(gen_permutations(arr, 3))
# itertools.permutation를 이용하면, for문을 사용하지 않고도 순열을 구할 수 있습니다.
import itertools
# pool = ['A', 'B', 'C']
pool = 'ABC'
print(list(map(''.join, itertools.permutations(pool)))) # 3개의 원소로 수열 만들기
print(list(map(''.join, itertools.permutations(pool, 2)))) # 2개의 원소로 수열 만들기
문제 설명
이 문제에는 표준 입력으로 문자열, mystr이 주어집니다. mystr에서 가장 많이 등장하는 알파벳만을 사전 순으로 출력하는 코드를 작성해주세요.
제한 조건
mystr의 원소는 알파벳 소문자로만 주어집니다.
mystr의 길이는 1 이상 100 이하입니다.
예시
input output
'aab' 'a'
'dfdefdgf' 'df'
'bbaa' 'ab'my_str = input().strip()
counter_dict = {}
for key in my_str:
counter_dict.setdefault(key, 0)
counter_dict[key]+=1
max_value = sorted(counter_dict.items(), key=lambda x:x[1],reverse=True)[0][1]
answer_list = []
for k,v in counter_dict.items():
if v == max_value:
answer_list.append(k)
print(''.join(sorted(answer_list)))
# 다른 언어에서는..(또는 이 기능을 모르시는 분은) 보통 사람들은 반복문을 이용해 수를 셉니다.
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 7, 9, 1, 2, 3, 3, 5, 2, 6, 8, 9, 0, 1, 1, 4, 7, 0]
answer = {}
for number in my_list:
try:
answer[number] += 1
except KeyError:
answer[number] = 1
print(answer[1]) # = 4
print(answer[3]) # = 3
print(answer[100]) # = raise KeyError
import collections
my_str = input().strip()
answer = collections.Counter(my_str)
print(answer) # dict형태로 출력됨.
#Counter객체는 .most_common() 으로 key, count의 튜플리스트가 나옴.
answer.most_common() #
dict_ = {'k': 5, 'e': 3, 'a': 2, 's': 2, 'd': 2, 'f': 2, 'j': 2, 'l': 1}
dict_.values()
# dict_.keys(), dict_.items()
max(answer.values())
# -> values로 max값 바로 찾을 수 있다.
# -> max값을 알 때, for문을 돌면서, key값들을 누적할 수 있다?
# -> max값이 여러개일 수 있으니, 미리구한 최대값 == count 하면서 돌아야한다.
my_list = input()
max_count = max(collections.Counter(my_list).values())
[ word for word, count in collections.Counter(my_list).items() if count == max_count]
for 문과 if문을 한번에 - List comprehension의 if 문
문제 설명
정수를 담은 리스트 mylist를 입력받아, 이 리스트의 원소 중 짝수인 값만을 제곱해 담은 새 리스트를 리턴하는 solution함수를 완성해주세요. 예를 들어, [3, 2, 6, 7]이 주어진 경우
3은 홀수이므로 무시합니다.
2는 짝수이므로 제곱합니다.
6은 짝수이므로 제곱합니다.
7은 홀수이므로 무시합니다.
따라서 2의 제곱과 6의 제곱을 담은 리스트인 [4, 36]을 리턴해야합니다.
제한 조건
mylist는 길이가 100이하인 배열입니다.
mylist의 원소는 1이상 100 이하인 정수입니다.mylist = [3, 2, 6, 7]
answer = [number**2 for number in mylist if number % 2 == 0]
answer
mylist = [3, 2, 6, 7]
answer = []
for number in mylist:
if number % 2 == 0:
answer.append(number**2) # 들여쓰기를 두 번 함
# 파이썬의 list comprehension을 사용하면 한 줄 안에 for 문과 if 문을 한 번에 처리할 수 있습니다.
mylist = [3, 2, 6, 7]
answer = [number**2 for number in mylist if number % 2 == 0]
문제 설명
본 문제에서는 자연수 5개가 주어집니다.
숫자를 차례로 곱해 나온 수가 제곱수가 되면 found를 출력하고
모든 수를 곱해도 제곱수가 나오지 않았다면 not found를 출력하는
코드를 작성해주세요.
예시 1
입력
2
4
2
5
1
출력
found
설명
수를 곱해나가면 2, 8, 16, 80, 80 이 나옵니다. 16은 4를 제곱해 나온 수이므로 이 수는 제곱수입니다. 따라서 found를 출력합니다.
예시 2
입력
5
1
2
3
1
출력
not found
설명
수를 곱해나가면 5, 5, 10, 30, 30 이 나옵니다. 이중 어떤 수도 제곱 수가 아니므로 not found를 출력합니다.data = [ int(input()) for _ in range(5)]
import math
product = 1
check=False
for n in data:
product*=n
if math.sqrt(product) == int(math.sqrt(product)) :
print('found')
check=True
break
if check == False:
print('not found')
# https://harryp.tistory.com/317 [Park's Life]
import math
data = [ int(input()) for _ in range(5)]
product = 1
# check=False # 1. for내부에 if로 끊김을 나타내는 flag변수를 안쓴다.
for n in data:
product*=n
if math.sqrt(product) == int(math.sqrt(product)) :
print('found')
#check=True
break
# if check == False:
# 2. for가 안끊기고 다 돌았다면, else문 실행시킨다.
else:
print('not found')
느낀점( flag변수 대신 for-else문 -> for if 찾았으면 flag break 대신 for if 찾았으면처리 else못찾았다처리 + 제곱수 + 소수점.0의 int확인)
-
for_if 조건: break-> 만약다 돌았는데도 if brea에 안걸린 not found== for 다돈 경우else조건X시 처리- 원래는.. for문 내부에서 if 걸렸다? -> break하고 for문 뒤에는 실행 X 를 for문 밖 flag=True/False 변수에 전달해줬다.
- 이제는 for문 if 걸려서 flag = True + break -> if flag: 처리는 하지 말자.
- for문 if 걸려서 break -> 만약 안걸리고 다돌면 처리를 else문에서
-
제곱수의 판단 : math.sqrt()를 씌웠을 때 int여야한다.- 하지만 sqrt()씌우는 순간 int라도 2.0 3.0 이 되어버린다.
-
정수.0의 int 판단방법- int()변환값 == 현재값 ( 전환된 값의 비교로 판단 )
- cf) 정수 판단 방법
- isinstance( , int)
- type( v ) == int
# 비 파이썬은 덮어쓰기 당할 변수값을 temp에 넣어놓고 덮어쓰기 -> 다른쪽 덮어쓰기
a = 3
b = 'abc'
temp = a
a = b
b = temp
파이썬에서는 다음과 같이 한 줄로 두 값을 바꿔치기할 수 있음.
a = 3
b = 'abc'
a, b = b, a# - while문에 if 탈출(break or def-return)이 없다? -> 다돌고 <조건문 직후 상태>로 빠져나와서 최종 처리한다는 뜻
# ex> while low < high -> low >= high순간에 빠져나옴. 주로 직후인 low==high에서 빠져나와 마지막 처리
def bisect(a, x, lo=0, hi=None):
if lo < 0:
raise ValueError('lo must be non-negative')
if hi is None:
hi = len(a)
while lo < hi:
mid = (lo + hi) // 2
if a[mid] < x:
lo = mid + 1
else:
hi = mid
return lo
mylist = [1, 2, 3, 7, 9, 11, 33]
print(bisect(mylist, 5)) # ??? 없는 것도 나온다?
# 실제 list index의 +1을 반환하는 것 같다.
# ** 해당 숫자 n을 어디에 insert해야하는지의 위치를 보여준다.**
# 1) 같은게 있으면? 그 index +1 자리에 넣어라
# 2) 같은게 없으면? 오름차순으로 넣어야할 자리는 여기다.
import bisect
mylist = [1, 2, 3, 7, 9, 11, 33]
print(bisect.bisect(mylist, 9)) # 같은게 4에 있으니 5번째 들어가야한다.
print(bisect.bisect(mylist, 33)) # 같은게 6에 있으니 7에 들어가야한다.
print(bisect.bisect(mylist, 5)) # 없는데 <<오름차순>> 4->value 3 뒤의 5자리에 들어가야한다.
# index 함수는 이진 탐색이 아닌 선형 탐색 함수입니다.
# (물론 주어진 input에 대해서 index 함수를 쓰면 정확한 output 값을 얻을 수 있긴 합니다.)
# 이진탐색의 시간복잡도는 O(logN) 이나,
# index 함수는 선형탐색을 하므로 시간복잡도가 O(N)이라 시간이 오래 걸립니다.
# bisect.bisect(mylist, n)의 n은 mylist에서 찾고자하는 값입니다.
# bisect.bisect(mylist, n)이 리턴하는 값, x는 mylist에서 n이 위치한 index의 오른쪽 값을 나타냅니다.
# insertion point를 리턴합니다. 즉, 3의 인덱스는 2이므로 이 다음에 있는 insertion point는 2+1 = 3이 되는 것이지요.
# 말씀하신대로 bisect는 key 가 없으면 key가 들어갈 위치를 반환합니다.
# - 내뱉은 point가 .. 직전에 같은값이 있어서 그 바로 뒤라면? i-1 반환
# - 내뱉은 point가.. 직전에 같은값은 없으나.. 순서라서 줬다면? 그냥 탐색 실패-> -1반환
import bisect
def b_s(ary,key):
i= bisect.bisect(ary,key)
return i-1 if ary[i-1]==key else -1
느낀점(bisect.bisect( list, value) ---> return or insert point, 바로앞에 있거나 못찾았지만 정렬상 그자리)
- 정렬된 list라면, 이진탐색을 bisect.bisect로 할 수 있다.
- return된 값이. 실제 있떤 값이면 i + 1 = return값이다. -> return값 - 1을 하자
- return된 값이. 없으나 정렬상 그자리에 들어가라고 return한 값이다 -> ??? 직전과 값이 같앗 뱉은 건지 확인해야한다.
- if number == list[return value - 1] ->returnvalue -1 else None..
``` 이번 강의에서는 인스턴스 출력 형식을 지정하는 방법을 배워봅시다.
예) 2차원 평면 위의 점을 나타내는 Coord 클래스의 인스턴스를 (x 값, y 값)으로 출력하기
class Coord(object):
def __init__(self, x, y):
self.x, self.y = x, y
point = Coord(1, 2)
print( '({}, {})'.format(point.x, point.y) )
# 또는
def print_coord(coord):
print( '({}, {})'.format(coord.x, coord.y) )
print_coord(point)
# __str__ 메소드를 사용해 class 내부에서 **출력 format**을 지정할 수 있습니다.
class Coord(object):
def __init__ (self, x, y):
self.x, self.y = x, y
def __str__ (self):
return '({}, {})'.format(self.x, self.y)
point = Coord(1, 2)
print(point)
point
코딩 테스트 문제 등을 풀다 보면, 최솟값을 저장하는 변수에 아주 큰 값을 할당해야 할 때가 있습니다. 이번 시간에는 이때에 사용하기 좋은 inf에 대해 알아봅시다.
이 기능을 모르시는 분은 본인이 생각하는 임의의 큰 수(99999등)를 할당합니다.
# 비파이썬에서, 최소값을 구할려구 미리 큰값을 넣어올 때,
min_val = 99999
min_val > 100000000 # ?
# 파이썬에서, 최소값을 구할려구 미리 큰값을 넣어올 때,
# 파이썬이 제공하는 inf 를 사용. inf는 어떤 숫자와 비교해도 무조건 크다고 판정
min_val = float('inf')
min_val > 10000000000
inf에는 음수 기호를 붙이는 것도 가능합니다.
max_val = float('-inf')
float('inf')
float('-inf')
이번 강의에서는 파일 입출력 코드를 간결하게 짜는 법을 알아봅시다.
'myfile.txt'라는 이름의 파일을 읽는 코드를 짜보세요
# 1. open -> 2. 반복문 while -> 3.line = readlins() + if not line: break + line처리 -> 4. close
f = open('myfile.txt', 'r')
while True:
line = f.readline()
if not line:
break
raw = line.split()
print(raw)
f.close()
# with - as 구문을 이용하면 코드를 더 간결하게 짤 수 있습니다. 코드를 아래와 같이 쓰면 다음과 같은 장점이 있습니다.
# 1. 파일을 close 하지 않아도 됩니다: with - as 블록이 종료되면 파일이 자동으로 close 됩니다.
# 2. readlines가 EOF까지만 읽으므로, while 문 안에서 EOF를 체크할 필요가 없습니다.
# my) python은 readlines()가 EOF를 알아서 인식하니 -> 반복문 in 자리에 넣으면 된다. -> EOF 체크 필요없음.
with open('myfile.txt') as file:
for line in file.readlines():
print(line.strip().split('\t'))