OBJECT 01 읽기전 필요소양(코드스핏츠)
object 책을 강의한 코드스핏츠 유튜브 요약
📜 제목으로 보기
- 참고 유튜브 : https://www.youtube.com/watch?v=sWyZUzQW3IM&list=PLBNdLLaRx_rI-UsVIGeWX_iv-e8cxpLxS&index=1
- 정리본: https://github.com/LenKIM/object-book
- 코드: https://github.com/eternity-oop/object
- 책(목차) : https://wikibook.co.kr/object/
ch1. 책 읽기 전 기본 소양
- 코딩을 하는 이유(motivate) : 돈
- 왜 이렇게 짰어? :돈이 덜 드니까
- 왜 그렇게 생각? -> 생각의 기저에 있는 philosophy(철학)을 살펴봐야함
- 근대부터의 과학철학 : 토마스쿤 - 과학혁명 -> 과학사 철학구조에 큰 영향을 끼침 -> 어떻게 서구문명과 프로그래밍에 영향을 끼칠까
-
철학구조를 이해한다고 해서 -> 우리가 실질적으로 머리속에서 무엇을 하는데에, 직접적인 영향을 끼치진 않는다. 철학은 base일 뿐이고, 그 윗단계의 frame이 필요함
-
켄트 백의 구현 패턴이라는 책을 보면, 생각하는 코드의 틀로서3가지를 제시함가치(value)원칙(principle)-
패턴(pattern): 가치와 원칙을 base로 해서 반복되는 유형이 나오는 것일 뿐이므로 1,2가 더 윗단계

- 캔트백은 죽은 사람도 아니고 지금도, 알고리즘 시험쳐서 페이스북에 입사해서 일하고 있다고 함..
- 짤없다.. 알고리즘 공부는 계속해야한다.
-
켄트 백 3가지와 다르게, 패턴을 빼고 이 책에서는
Xoriented라는 사고유형의 틀(패러다임과 유사, 객체지향적 or 함수형)을 제시한다.- 이 3가지 틀을 바탕으로
프로그램 왜 이렇게 짰니?라고 설명을 시도해보려고

- 토마스 쿤(과학혁명의 구조): 철학사적 관점. 과학은 상대적. 그 동네의 믿음일 뿐 진리는 아무도 모름. 현재 우리가 추구하는 과학은 종교와 다르지 않다. 분자가 최소단위라고 생각했다가 원자가 발견된 이후로는 패러다임이 바뀜. 상대주의 기본적 기틀
- 러커토시 임레(합리주의): 과학은 여론조사같은 것이 아니야. 합리성이 있어.
- 파울 파이어아벤트: 난장판
- 이 3가지 틀을 바탕으로
-
상대주의와 합리주의는 공존한다.
- 클래스 -> 상대적으로 부모의 자식클래스일 수도 있고, 자식클래스의 부모일 수 도 있다. ~보다 크다 작다 (상대주의 적용)
- bmi기준으로는 무조건 뚱뚱해. 평균, 중앙값 등 적용(합리주의 적용)
상대성을 갖기 위해서는 어떤 기준 =어떤 합리성이 적용되었는지 계속 생각해야한다.
-
value: 개발자세계에서 추구해야할 가치(돈)는 3가지
-
캔트백의 가치(value) : 사람들이 보편적으로 환산할 수 있는 돈이 있는 것처럼
-
개발자 세계에서는
코드를 이렇게 짠 이유는?환산할 수 있는 가치인communication, simplicity, flexibility- 커뮤니케이션 안되면 비용이 발생한다.
- 간단하게 짤 수록 비용이 발생한다.
- 유연(여기저기 사용가능)하게 짤 수록 비용이 적게 발생한다.
- 사실 유연하다 = 여기저기 사용가능하다 = 간단한 코드만 가능하다.
- ex> 실제 짠 메소드 vs Math.sin() : 간단한 Math.sin()이 훨씬 많이 재활용된다.
- 유연성(flexibility)을 얻으려면 간단(simplicity)하게 짜야하고, 유연하고 간단하게 짰다면 커뮤니케이션(communication)도 잘될 것이다.

-
개발자 세계에서는
principle: 다같이지킴으로써 -> 예외상황을 즉각 캐치할 수 있어 최소비용으로 처리
- 예를 들어, 문제 있는 사람만 일어나주세요 -> 일어난 사람만 바로 캐취해서 즉각처리 가능
- 맘대로 일어나거나 앉거나 -> 문제 있는 사람을 바로 캐취 X -> 비용 많이 듦.
- 원칙은 value(가치)와 다르게 가치를 발생시킴.
- 팀, 회사, 국가 등 각 카테고리, 각 그룹이 요구하는 원칙들을 지켜야하므로, 레이어형태로 발생한다.
- 캔트백이 제시하는 원칙 4가지는???

-
Local consequences: 변수 Localize해서 생명주기를 짧게 가져가는 원칙(머리가 나쁘다. 언제 생성되고 죽는지 다 기억못한다. 짧게 가져가라) -
Minimize repetition: 중복을 최소화해라(중복은 제거하는게 아니라 발견하는 것) (수준이 올라가면 반복이 새롭게 보이게 된다.) Symmetry: 짝을 맞춰라. getter 만들면 -> setter만들기. 되도록이면 짝을 맞춰서 만들어내라-
Convention: 컨벤션을 지켜라.- 원칙 4개를 지키게 되면 많으 비용을 아낄 수 있게 된다.
- 안지키면 버그로 확정짓자.
-
Xoriented
- OOP(객체지향 프로그래밍론)을 깔게 되면, SOLID원칙이나 DRY 등 다양한 기법들을 다루게 된다.
- 반응형, 함수형 등…은 불변성을 강조한다 cf) 객체지향은 불변성을 강조하지 않음.

pattern: 3개 원칙을 쓰다보면 반복되서 나타는 유형이 있다 -> 베스트를 만들어놓고 -> 비용없이 즉각 적용시키자.
-
미국에서는 매년 생산성을 측정하는데, 코드작성은 20%, 디버깅 50%
- IT는 100% 인건비 사업이다.
- 사람의 시간 = 돈
-
IT환경에서 돈을 적게 쓴다 = 시간을 적게 쓴다 같은 말.
-
디버깅, 기능 추가 등의 시간을 50%이상 투자한다.
-
받아온PM팀 욕하면서, 밤세게 됨 -> 사실은.. 본인의 코드가 유연(간단)하지도 X , 견고하지도 X, 격리되지 X
-
-
요즘은 애자일시대 -> 코드가 유연하게 받아질 수 있도록 설계를 탄탄하게 -> 코드의 품질을 높여야 살길이다.
- 보여질 때마다 요구사항이 달라짐.
- 어떻게? 변화에 따른 로직 격리에 성공해야함.
역할 모델
-
객체지향 프로그래밍론에서
변화에 따른 격리에 성공하는 방법은 1가지 방법만 제시한다.-
역할 모델만 제시한다.- 역할 모델외에 기업단위의 규모을 격리시킬 수 있는 수단을 생각해내지 못했다.
-
역할 모델을 통해 로직의 격리에 성공해야한다.
- 빠르면 3년 ~ 길면 5년
-
역할 모델 이해 -> 프로그래밍 격리 방법을 알아야 OOP세계에 입장권을 끊은 순간이다.
- 책을 읽고 -> 역할 모델로 entity나누기 -> 객체 설계 -> 이제 입장..
-
Abstraction: 역할 모델을 위한 추상화 이해
- 추상화 대표기법1: 일반화: 수학에서 온 것. 다양한 현상을 1개로 설명할 수 있게 하는 것.
- 2, 8, 16의 공통점 -> 함수로 묶는 것 ex> modeling, function, algorithm
- 추상화 대표기법2: 연관화: 내가 다 못하니까 다른애한테 맡겨야지. 나의 일부는 쟤꺼야.
- 복잡한 것은 띄어내서 쟤한테 준다. 위임이 가능하다. ex> reference, dependence
- 통으로 보면 복잡한 놈을, 뗴어낼 것은 떼어내서 위임시켜 보면, 간단하다.
- 추상화 대표기법3: 집단화: 체계적인 분류 ex> 카테고리제이션, 그루핑
- ex> group, category
- IT에서의 추상화
-
데이터추상화(Data Ab):- 메소드, 함수가 없음. = 동작, 행위가 없음.
- 크게 3가지로 나뉨.(외우자.)

-
modeling: 특정 목표에 따라 기억해야할 것만 추리는 것( 학생 vs 학적부관리를 위해 기억해야하는 학번+이름만 기억) -
categorization: 카테고리를 잘 만들어서 카테고리에 맞게 작동하도록 하는 것. 아빠이자~ 사장이자~ -
grouping: 그냥(의미, 공통점 없더라도 4기를 묶어두는 것) 모아두는 것
-
-
프로시져추상화(Procedural Ab): 절차적? (X) 순차적으로 1개씩 하는 것? (X) 고유명사로서함수에게 데이터를 넘겨 처리를 맡기는 것 = 데이터 처리방법을 함수에게 위임하는 것 = 함수만을 이용해서 데이터를 처리하는 것- 편하게 함수라고 생각하자.

-
generalization: 일반화된 방법을 사용하면 할수록 함수를 적게 만들 수 있다.- 책: 공통된 역할을 찾아, 하나의 인터페이스로 정의한다.
- 문제점: 우리의 머리가 나쁘다. -> 머리가 좋은 사람이 할 수 있다.
-
capsulization: 객체지향에서 나오는 캡슐화.- 은닉화와는 다르게, 보다 더 추상적인 것을 표현하는 것이다.
- 캡슐화의 여러가지 정의가 있어서
ATM기라 생각하자-
출금 메소드- 사용자는 통장+돈 만 넣으면 되지만, 그 안에 인증+은행권연결+보안+트랜잭션+타은행연결 상호인증… 많은 기능이 내부에 있다.
하지만, 내부의 복잡한 기능은 감추고, 사용자에게는 간단한 인터페이스 출금이라는 것만 노출함. - 캡슐화를 하지 않으면, 바깥에 복잡성이 노출된다. -> 여러가지 문제 중 가장 큰 문제는 (복잡성노출시 안에를 고치기 힘들다?X) 복잡성을 노출 하면, 머리가 나쁜 사용자들은 사용을 못한다.
- 우리가 만든 모듈을 누구나 쓰게하고 싶다면 캡슐라이제이션해야한다.
-
출금 메소드- 사용자는 통장+돈 만 넣으면 되지만, 그 안에 인증+은행권연결+보안+트랜잭션+타은행연결 상호인증… 많은 기능이 내부에 있다.
-
- 편하게 함수라고 생각하자.
-
객체지향적추상화(OOP Ab): UML에서 class간의 연결관계 표현방법- Generalization: 일반화 - 인터페이스 or 추상클래스를 만듦
- Realization: 구상화 - 인터페이스 or 추상클래스에서부터 파생된 클래스
- Dependency: 함수의 인자를 받거나 부분적으로 참조해야할 때
- Association: 단짝, 나의 영혼에 각인된 친구, 필드에 정의된 dependency
- Directed Association
- Aggregation
- Composition
-
-
객체지향 프로그래밍이 어려운 이유
-
역할 모델을 사용하기 때문- 역할 모델을 사용하기 위해서는
모든 추상화 기법을 동원함.- 그 중에
일반화를 가장 대표적으로 씀(가장 머리가 많이 필요)
- 그 중에
- 역할 모델을 사용하기 위해서는
- 수련하는데 시간이 오래걸려서 실패를 많이 한다.
-
Timing: 프로그램이 실행되는 시간
-
프로그램이 실행되는 순간이 언제냐
- 여기에도 똑같이 추상화 기법이 적용이 된다
- 몇시몇분(X) 어떤 시간대
- 여기에도 똑같이 추상화 기법이 적용이 된다
-
Program & Timing
- 프로그램: 메모리에 적재되서 실행될 때부터를 program이라고 함.
-
프로그램은 언제 어떤시기에 생명주기를 갖고 실행되는지 =
Timing을 보자.
-
프로그램은 언제 어떤시기에 생명주기를 갖고 실행되는지 =

-
language code: 언어로 코드 작성- 컴파일 이전에, 코드품질을 위해
lint라는 것을 이용한다 - 프로그램 작성시
lint time을 이야기한다.- 그거 왜 lint time에 못골라냈어. lint를 바꿔봐.
- 컴파일 이전에, 코드품질을 위해
-
machine language: 컴파일을 통해 머신 랭기지로 바꿔짐compile time
-
file: 파일로 바꿔서 영구보존 시도 -
load: 메모리에 적재 -
run: 실행- 이후 LOAD -> RUN 만 반복하여 실행됨
run time
-
terminate: 종료
- 프로그램: 메모리에 적재되서 실행될 때부터를 program이라고 함.
-
3가지 에러가 있음.
- context error도 있는데, 못잡아낸다.
- run time error도 앵간하면 못잡아낸다.
- 에러를 맞으려면 lint time or compile time에 맞고 싶어한다.
- 스크립트 랭기지는 runtime에서 밖에 못 잡아낸다.
-
script program의 생명주기
-
바로 file이 되고 load된 이후에 machine language로 바뀐다.

- 이 동네는 syntax error빼고는.. run time에러에서나 잡아낼 수 있다.
-
runtime
-
Runtime
-
load -> run되는 부분만 생각해보자.
-
file로 짠 코드를 [실행]을 눌러 메모리에 적재가 된다.

-
load
- 명령set와 값set로 로딩이 된다.
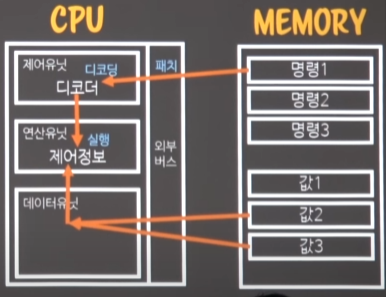
- cpu는 간략하게 그리면,
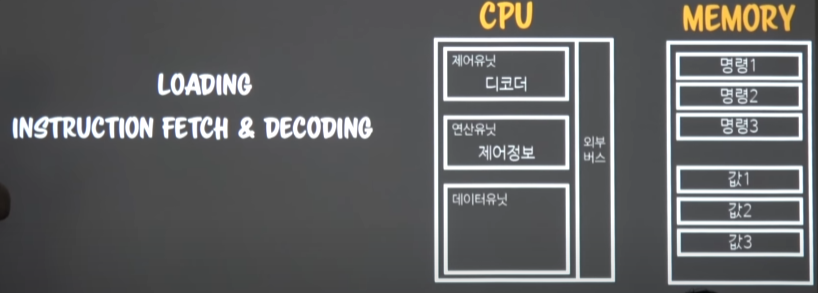
- 외부버스를 통해 -> 3가지 유닛으로 간다.
- 제어유닛: 디코더를 이용해서 명령들 해석 및 격리
- 데이터유닛: 메모리계수기로서, 메모리의 위치를 찾아서 넣거나 빼거나..
- 연산유닛: 제어정보 = 말그대로 연산
- load이후에는 instruction fetch 와 decoding(명령을 가져와서 -> 디코딩)한다.
-
메모리에 있는 명령과 cpu의 명령과는 직접적으로 일치하진 않기 때문에
디코딩을 통해 cpu가 이해할 수 있는 명령어로 디코딩한다.
-
외부버스를 통해 fetch한 명령이 cpu로 들어오고, 디코딩이 일어난다
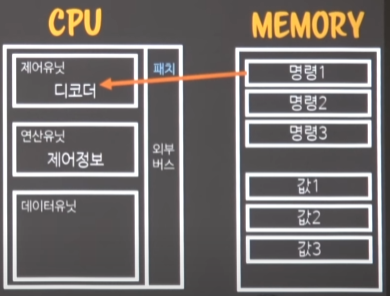
-
그리고나서 디코딩이 끝난 명령을 -> 연산유닛으로 보내어 명령을 실행시킨다.
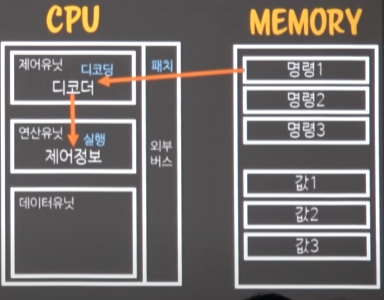
-
명령을 실행할 때, 필요한 값들을 메모리 -> CPU의 데이터유닛으로 가져온다.
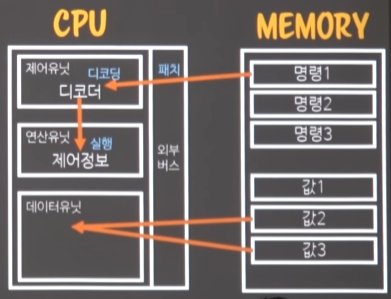
-
가져온 값을 연산유닛에게 건네주면,
연산유닛이 명령 + 데이터를 이용해서, 결과데이터를 다시 데이터유닛에게 건네준다. 이게 바로 execution(실행)이다.
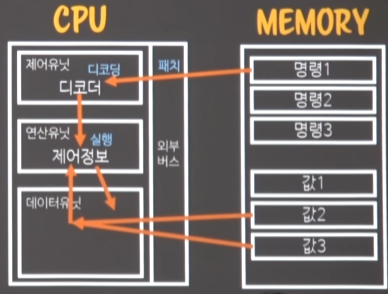
-
데이터유닛은, 결과데이터를 다시 메모리로 돌려준다.
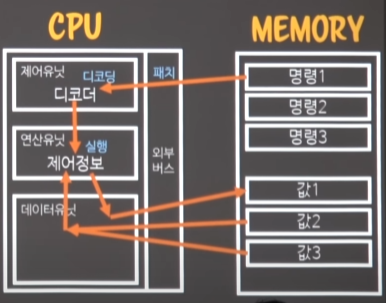
-
- 이후로는 다음명령(명령2)을 가져와 실행시키고 결과데이터를 건네주는
loading을 제외한 instruction fetch & decoding -> execution이 반복 된다.
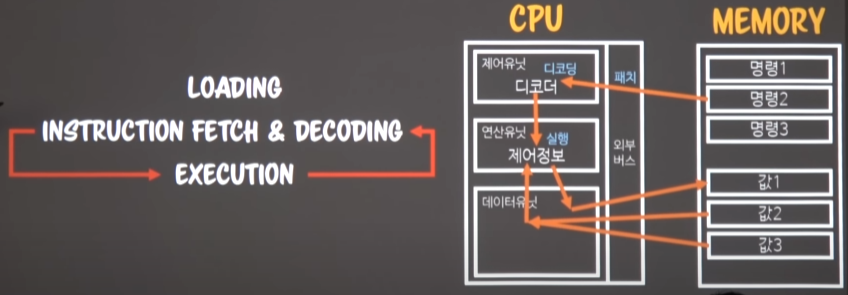
-
-
이처럼 메모리에 적재(loading)된 순서대로 명령이 실행된다면 동기화(sync)라고 부른다. 여기까지 메모리에 적재(loading)된 명령의 실행(fetch & decoding -> execution)을
runtime이라 부른다.- 명령이 다 실행되면 terminate가 일어난다.
-
Runtime이란
loading->instruction fetch & decoding->execution이 다 일까?-
Essential definition loading- 프로그램마다 다 가지는 최초 로딩 과정으로서, 메모리에 적재되는 순간 최초에 하는 행동은
이 프로그램 구동을 위한 기초적인 정의부터 로딩ex> 기저에 있는 print함수, console 등의 필수 정의들을 로딩.하도록 컴파일러안에 짜여져 있다.
- 프로그램마다 다 가지는 최초 로딩 과정으로서, 메모리에 적재되는 순간 최초에 하는 행동은
-
그 다음으로
VTABLE MAPPING을 한다.- 코딩: 우리는 text만 짰음
- 컴파일러: file을 만드는 애 일 뿐이다.
- 우리가 쓴 변수와 메모리공간은???
- 이미 compile time에 변수마다 가상의 메모리가 있다고 가정하고, 컴파일 한다
- 이미 변수-가상의 메모리가 컴파일된 상태에 맞춰서
vtable mapping을 표로 만들어, 진짜 메모리와 매핑을 시켜, 진짜 메모리주소로 바뀐다.
- vtable mapping으로 진짜 메모리를 얻은 상태이므로 실행가능해 진다.
-
이제서야
RUN이 일어난다.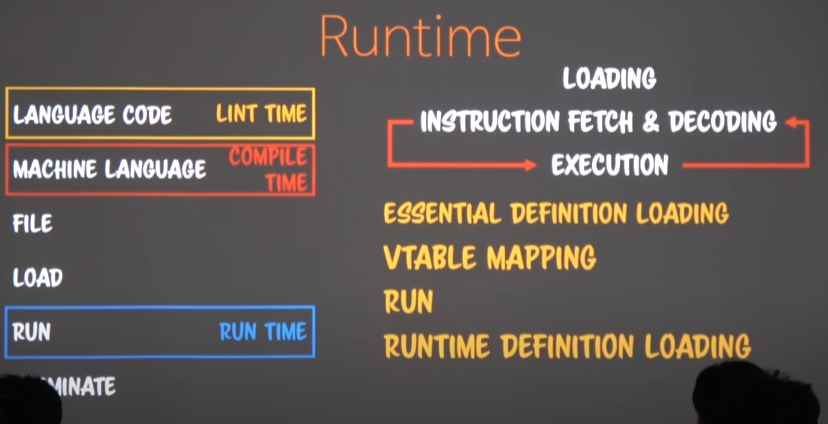
- 하지만 실행이후에 모든 랭기지는 끝나지 않는다.
-
RUNTIME DEFIFITION LOADING을 통해 실행이후에도, class 및 함수 정의 등 많은 정의를 로딩한다.- 최초 프로그램 실행시만 class등이 로딩되는 것이 아니다.
- java만 해도 실행도중 새로운 class들을 계속해서 로딩할 수 있다.
-
java가 대단한점 : 업계최초로 runtime loading을 적용한 것
- jar파일이 1~2기가 되는데, 실행시 왜 안뻗을까?
- 필요한 파일들은, 필요시 최초로 file에서부터 loading을 시작해서 ~!
- c나 c++은 프로그램 시작시, 우리가 정의한 모든 class가 시작된다.
- java는 사용자가 만든 것은 하나도 로딩X 필요시에 파일로부터 로딩
- jar파일이 1~2기가 되는데, 실행시 왜 안뻗을까?
-
RUN다시 로딩된, 새로운 class 등의 정의를 실행시킨다. -
같은 runtime임에도 불구하고, essential definition loading과 vtable mapping은 한번만 일어나지만, run -> runtime definition loading -> run 은 계속해서 일어난다.
-
-
Script Program
-
스크립트의 생명주기를 생각해보면, 컴파일되거나 최초로딩(essential definition loading과 vtable mapping)없이 실행된다.

-
일단 실행해야, 내가 만든 class와 함수가 loading이 된다.
- 예를 들어, 브라우저 시작 -> run -> jquery를 로딩 -> jquery를 쓰는 코드 실행
- 같은 runtime이지만, jquery쓰는 코드(run time)에 대해 상대적으로 jquery 정의 코드(static time)를 정적타임으로 보여진다.

- jquery외에 다른 class 등을 사용할때도 상대주의적으로 나뉜다.

-
runtime은 정의되어있거나 확정적인 것이 아니라고 생각해야한다.
- runtime안에서도 runtime이 쪼개지며, 각 코드에 대해서 확정타임이 상대적으로 정해진다.
-
runtime은 정의되어있거나 확정적인 것이 아니라고 생각해야한다.
-
-
-
runtime 요약 : runtime은 확정적인 무엇이라고 가정하지 말아라
- 유연하며, 언어에 따라 애매할 수도 있음.
Pointer of Pointer: 메모리를 다루는데 있어서 반드시 기억해야할 것

- 특정 포인트를 직접 가르키지 않고
- 어떤 값을 얻기 위해선
- 포인트를 찾은 뒤 ->
- 다시 포인트를 찾아서 얻겠다.
- 왜 그럴까?
- 어떤 값을 얻기 위해선
-
가상의 메모리판이 있다.

-
A에라는 변수에 “TEST”라는 문자열을 넣었다고 가정하자.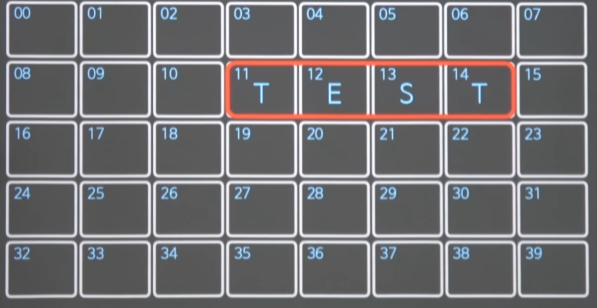
- 메모리에 그대로 박았으면, 11번~14번까지 문자열을 넣었다.
-
A의 주소
&A는 11번이라고 할 수 있다.- 변수에는 2가지 속성이 있다. 변수안에 값 & 메모리

- 11번에서 시작하지만, 4칸을 차지하는 것은 어떻게 안다? 변수의 길이로 안다.
-
java의 INT or BOOLEAN 같은
기본형들은시작메모리번호에서부터 메모리를 얼마나 차지하는지의 길이를 나타내는 것들이다.- 포인터는 첫번째 위치만 가리킬 뿐이다.
- 변수에는 2가지 속성이 있다. 변수안에 값 & 메모리
-
B라는 변수는 A의 주소를 가지고 있다고 가정해본다.
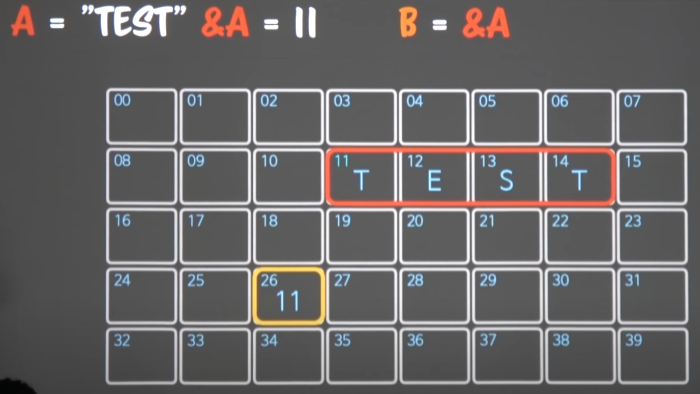
-
26번 메모리에 있는 11은 실제론 숫자x a의 주소값이다.
-
B의 주소가 기리키는 값
*B가 “TEST”라고 예기할 수 있다.
-
-
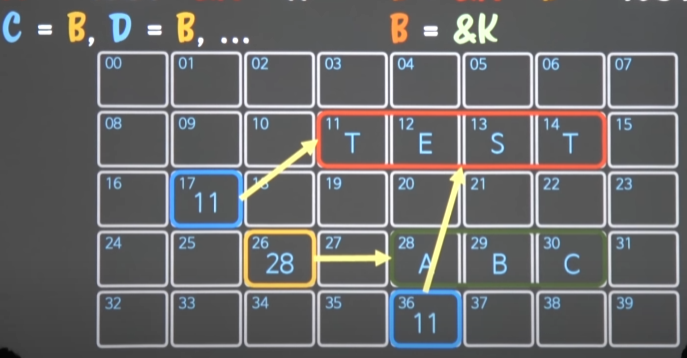
중요한 것은 C와 D가 B와 동일한 값(&A)를 갖도록 만든다면, 아래와 같이 만들어질 것이다.
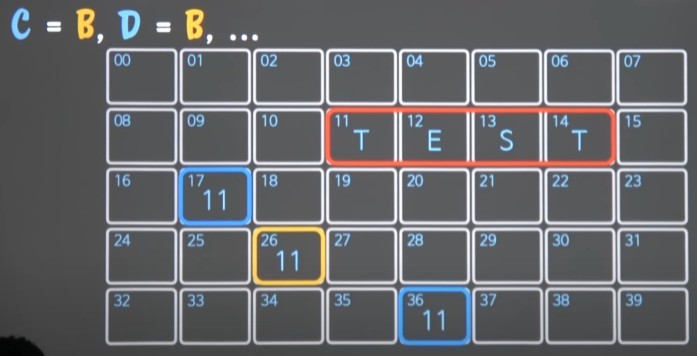
-
B에 들어있는 것은 값이 아니라 주소(A의)기 때문에 B, C, D 모두 원래의 A를 가리키게 된다.
- B가 A를 가리켰는데, C와 D도 A를 가리키게 되었다.
-
B에 들어있는 것은 값이 아니라 주소(A의)기 때문에 B, C, D 모두 원래의 A를 가리키게 된다.
-
근데 B가 배신때린다면?
-
B가 “ABC”의 값 + 메모리28번부터의 K를 가리키도록 K의 주소값을 가지게 된다면?

- B는 배신때려서 K를 가리키고 있고(K의 주소값을 가진다 = K를 가리킨다)
C와 B는 여전히 A를 가리키고 있다.
-
뭐가 문제일까?
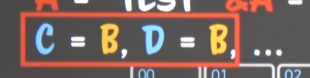
-
뭐가 문제일까?
-
이후 B는 바뀌었는데, C와 D는 자동으로 못갈아타고 A에 남아있다.
- 변화에 따라오질 못함. -> 문제가 심각함.
-
-
-
써있는 것은
C = B, D = B로서 B와 같은놈들이라고 쓰여져 있는데, 이후 B의 배신 및 C와D는 변화에 따라오지 못하고, B가 새롭게 가리키는 것(K)와는 다른 것 & B옛날 것(A)을 가리키고 있다.- B가 배신을 떄리는 순간 `코드를 보는 우리의 눈`이 잘못 안 체로 개발을 하게 된다. - **이게 바로 `참조의 전파`라고 한다** - 외부에 노출된 참조 = 직접참조의 문제다 - **이미 전파가 되어, 변화에 못따라가니까** 직접참조를 하면 안된다. - 문제는 사람이 만드는 것이다. C와D가 B와 같을 것이라고 코드를 보면서 믿고 있기 때문이다. - B가 배신때리는 순간 다 망가진다. - **객체 생성시점 == setter시점에 어떤 레퍼런스(참조)를 받아와 변수에 잡아넣고** **변수로서 프로그램을 돌리고 있는다. + 내가 받아온 레퍼런스(참조)는 안변하겠지(B의 배신이 없겠지)라고 생각한다.** -
직접참조로 인한 문제, B의 배신에도 C,D가 변화를 유지하는 유일한 방법은?
- 참조(&변수=주소값)값이 바뀔 가능성이 있는놈 자체를
-
변수 =에&K주소값을 넣는포인터, 직접참조 하지 않고 - 참조값을 넣을 변수(=
포인터)에 (map을 이용하여 value에다 넣는).을 통해서포인터의 포인터를 이용하는 방법이다.
-
-
포인터에
한번더 포인터비용을 지불함으로써, 런타임에서 레퍼런스를 바꿔도, 동일한 레퍼런스를 참조하게끔 만들 수 있다.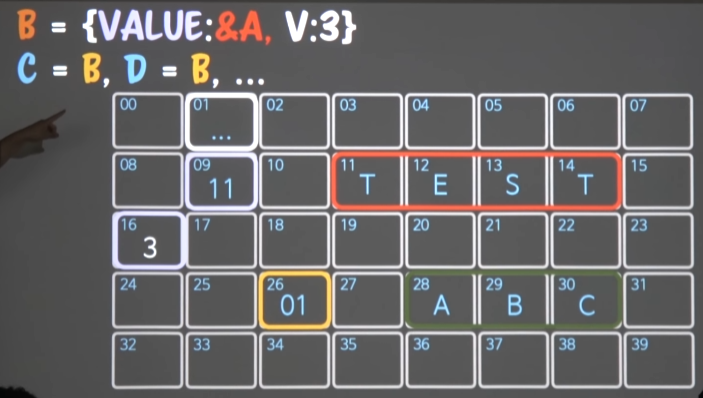
- 01번에 obj VALUE, V를 key로 갖는
map을 만든다. (map으로 만들어서 .을 사용)- 이 때,
VALUE라는 key가 A주소값을 가지는 = A를 가리키는 포인터가 된다. - 01번 map(포인터1) - 원래는 heap영역에 있어야하는데, 메모리에 그냥 임시로 그림
- 01번 map -> 09번 VALUE(포인터2) -> A(11번)
- 01번 map -> 16번 V -> 3
- 이 때,
- C와 D를 -> B를 가리키게 하고 싶다.
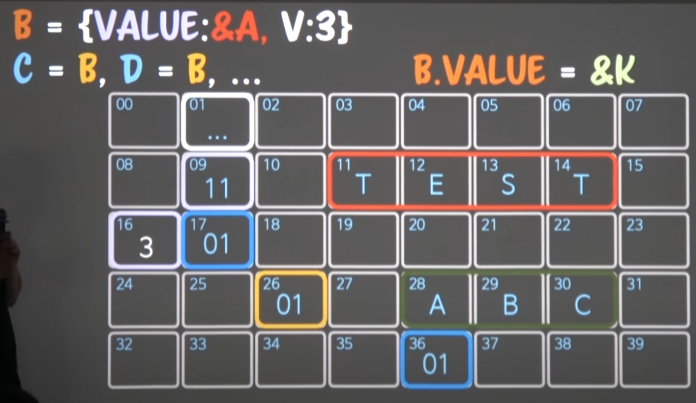
- 변수 B는 26번 -> 01번 map을 가리키고 있다.
- 17번 C , 36번 D -> 01번 map을 가리키게 했다.
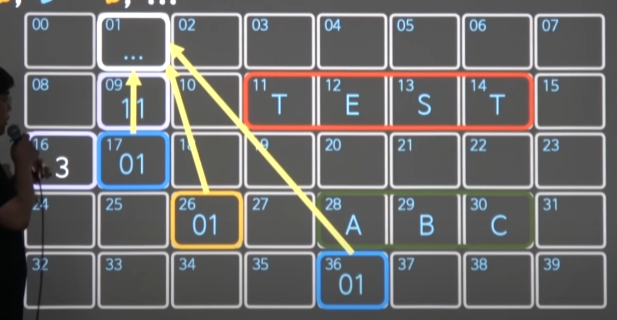
- B의 배신 대신 ->
B.VALUE로 배신을 때린다.- B가 아니라 B.VALUE에 &A대신 -> &K로 K포인터가 되도록 배신을 때리면
- B.VALUE -> 11번(&A)을 가리키던 것이
B.VALUE -> 28번(&K)로 바뀐다. -
C(17)와 D(36)는 B.VALUE의 배신에도
여전히 B가 보던 01번 map을 보고 있는 상황이라 B, C, D 모두 01번 map -> 업데이트 된 .VALUE -> 28번(K)를 보게 된다- 주소를 담은 변수(B)의 할당(직접참조)는 map의 껍데기만 할당해주고, 실제 참조가 바뀌는 부분은 map속 .VALUE로 가리키기해서, 매번 업데이트 되게 하자.
- 01번에 obj VALUE, V를 key로 갖는
- 참조(&변수=주소값)값이 바뀔 가능성이 있는놈 자체를
-
my) runtime시 레퍼런스(한 변수가 참조하는 주소)가 바뀌는 경우가 있고
- 그럴경우, 일반 변수로 받아보던 또다른 참조변수들은 업데이트가 안되니
- 바뀔 예정이 있는 애들은 map안에 변수가 포인터가 되도록하고
- 받아보던 또다른참조변수들은 map을 할당받고
- 바뀌는 것은 map안의 .변수가 reference를 할당받으면서 변경가능하게 하자
- 직접 메모리 참조시, 걔를 참조하는 애들은, 업데이트가 자동반영안되 문제가 된다.
-
참조하는 애들은 껍데기를 참조하도록하고, 변경가능한 놈은 내부에서 바뀌게 한다.
- 대신 참조하는 애들은 껍데기-> .점을 통해 -> 업데이트되는 내부에 접근하게 한다
- **이 원리(참조에 참조, 점을 통한 다시 한번 참조 찾기)는 객체지향에서**
런타임시>
- 직접참조X 위(바깥) 참조를 통해 아래(내부)로 내려오는 구조로서
- 인터페이스를 정의시, 추상클래스 메소드호출 -> 그 함수가 구상클래스 메소드를 호출할 수 있는 원리이며
- 링크드리스트의 원리
- 데코레이션 패턴의 원리
- 책에서는
동적 바인딩이라고 표현한다.- 우리는 직접참조는 지양하고, 참조에 참조를 이용해야, 런타임변경에 안전해진다.
- 그래서 객체지향에서는 값을 이용하지 않고, 모든 곳에 참조를 이용한다.
- 가리키는 것이 &A(11번) -> &K(28번)으로 바꿀수 있는 유연성을 얻기 위해서
- 직접 참조했을 땐, 전파시 문제가 생김(참조당하는 애들이 변경하면 업데이트가 안됨)
감싸는 포인터를 가리켜야함.->객체 안에 객체가 있어야함 -> 모든 것을 객체로 만들어야함.