OBJECT 12 도메인분해 3가지 방법(코드스핏츠)
object 책을 강의한 코드스핏츠 유튜브 요약
📜 제목으로 보기
- 참고 유튜브 : https://www.youtube.com/watch?v=navJTjZlUGk
- 정리본: https://github.com/LenKIM/object-book
- 코드: https://github.com/eternity-oop/object
- 책(목차) : https://wikibook.co.kr/object/
ch12. 3가지 도메인 분해 방법
- 오브젝트 책 7장 (다음엔 9장~10장)
- 코드스피츠 84에서 나머지를 나갈 수 있다.
- 조영호님의 오브젝트 책 쓰면서 고생한 것은 통신사 요금 부분
분해의 개념
- 모으거나 합체, 조립에 대한 영어단어는 많다.
-
assembly,composition, … 책에서 프로그래밍을 조립하는 것은composition이라고 많이 부른다.- 컴포지션: 하나하나 의미가 있는 부속들 -> 모아서 하나의 결과물로 만드는 것
- 어쎔블: 의미없는 부속들 -> 정확히 모아야 의미있는 1개의 결과물이 됨.
- 완성된 소프트웨어는 어쎔블?? 컴포지션??
- 어쎔블 상태로 만들어졌다? -> 빼거나 더하면 망가진다. like 레고
- 컴포지션 상태로 만들어졌다? -> 하나 고장나면 다른 것으로 끼워넣으면 된다.
- 소프트웨어가
컴포지션화 되었다 ->모듈화/격리가 잘 되어있다.는 뜻
-
- 분해 -> 책에서는 디컴포지션 -> 소프트웨어 만들 때, 컴포지션화 한 사람들에게만 쓸 수 있음.
- 소프트웨어에서의 디 컴포지션 ->
XXX(도메인)를 모듈화/격리 -> 결국 컴포지션된 소프트웨어로 만들기 - 현실 세계의 복잡한 상황인 도메인 -> 디 컴포지션 (각개격파) 하여 컴포지트를 만듬 -> 컴포지션 -> 소프트웨어
-
우리의 목표:
도메인을 어떻게 디 컴포지션 할 것인가for 컴포지션화된 소프트웨어를 만들기 위해
- 소프트웨어에서의 디 컴포지션 ->
-
대부분의 도메인은, 사람의 하는 일이라, 감성적+충동적+비이성적으로 일어나서, 도메인이 엉망진창으로 결합되어있다
- if가 30개씩 나와있다. 왜? 시대 순으로 만들어졌기 때문
- android core API 뒤에는 숫자가 붙어있다 -> 0 1.. 시대순으로 아닌 것 같은 것을 버릴 수 없으니 엉망진창으로 결합하고 숫자를 붙여놨다.
- java에서는 decrecate된 것이 많다. 엉망진창으로 되어있어서
- 사람이 만드는 도메인은 시간 순으로 만들어지기 때문에, 절대로 예쁘게 컴포지션 되어있지 않다. 비 논리적으로 결합되어있다.
- if가 30개씩 나와있다. 왜? 시대 순으로 만들어졌기 때문
-
우리는 어떻게 비논리적인 도메인의 디컴포지션을 -> 논리적으로 컴포지션(분해) 할 수 있을까
- 분해를 꼭 해야할까? ->
모델링하려면분해후 일부만 추출해야 할 수있다. - 분해를 안하면,
복잡성 폭팔(책에서는인지과부하)가 되어 사람은 이해(감당)할 수 없다고 한다.- 일반적으로는 if가 2단계(중첩if 3단계-if안에 A and B and C도)의 를 넘어서면 무조건
복잡성 폭팔이 생긴다. -
for안에 if도 감당 X -> for 자체가 if기 때문에
- 감당할 수 있으려면, 기계가 되어, 진입표 -> 상황별 모든 상태의 조합수를 표를 그려서 코딩으로 옮기는 방법 밖에…
- 일반적으로는 if가 2단계(중첩if 3단계-if안에 A and B and C도)의 를 넘어서면 무조건
-
if문 경우의 수만큼 쪼개서 다르게 만드는 것이
분해의 시작- 그렇지 않으면 복잡성이 폭팔한다.
- 분해를 꼭 해야할까? ->
Functional decomposition

-
기능(시작과 끝이 있는 flow)적으로 분해한다.
- (수학적)함수적으로 분해한다라고도 해석해도 된다.
- 기능 = 액션 = behavior = 행위 = 어떤 알고리즘 수행 명령단위로 수행할 수 있다. = a -> b까지 실행 후 c-> d까지 수행할 수 있다. =
수행 업무는시작과 끝이 있는 하나의 flow로 바라볼 수 있기 때문에쪼갤 수 있다고 생각했다.- 우리는 도메인을 로 나눌 수 있을까?
시작과>
- 핸드폰 개통해야한다 -> 우리는 flow를 떠올린다. -> 매장 가기 -> 상담 -> 가입신청서 -> 절차 -> 핸드폰 개통의
flow: 중간에 빠꾸 맞으면 돌아가는 과정도 있음.
- 핸드폰 개통해야한다 -> 우리는 flow를 떠올린다. -> 매장 가기 -> 상담 -> 가입신청서 -> 절차 -> 핸드폰 개통의
- 데이팅앱: 복잡한 연애절차를 우리 앱을 통해 flow로 해결할 수 있다 라고 생각한다.
- 메뉴결정앱: 복잡한 점심메뉴 고르기 -> 단계별로 flow로 결정함.
- 우리는 도메인을 로 나눌 수 있을까?
시작과>
- flow를 흐름도를 그리지 않아도 flow다 ex> todo list(적고 해결한 순대로 체크)
- 쪼갤 수 있는게 중요함.
- 할일을 쪼갤 땐, 어떻게 쪼갰나? functional하게 = 시작과 끝이 있는 flow형식으로 쪼갰을 것이다.
- 문제점: 인간이 학습하기 때문에 변화가 일어난다 -> flow는 변화에 취약하다.
-
Flow Chart 기법

- 우리는 어떤 행위를 처리할 때, flow로 처리한다.

- flow는 가만히 있을리 없다, 주황색 상태를 같이 처리한다. flow란 상태를 처리하기 위핸 flow다

-
다음flow에서도 해당 상태를 처리하려고 할 것이다.
- 첫번째 flow가 상태의 initialize였다면, 두번재flow는 네트워크 동기화 등

-
여기서, 주황색 상태를 처리하려면, 애초에 (하늘색)다른 상태도 있어야함을 깨닮는다.
-
처리해야할(주황색), 필요한 상태(하늘색)의 데이터들은 flow바깥의 전역변수들이다.
-
책으로 비유하면, 주황색=직원에 대한 데이터만 있으면 될 줄 알았더니, 직원들의 세금을 계산하다보니, 하늘색=시간제근무제를 분리할 수 있는 데이터가 추가로 필요하다.
-
추가로 필요한 데이터는 여기 뿐만 아니라 처음부터 존재해야함(전역변수는 첨부터)을 깨닮는다.
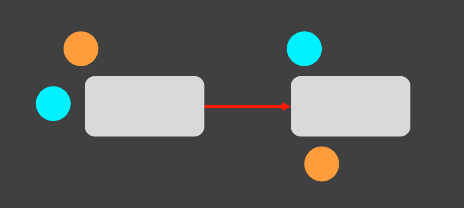
-
이 때,
처음flow는 주황색만 있다고 가정하고 짠 flow기 때문에, 전역데이터 하늘색이 등장한 순간오염된 flow다. -> 해당 로직은 새로 만들어야한다.
-
이 때,
-
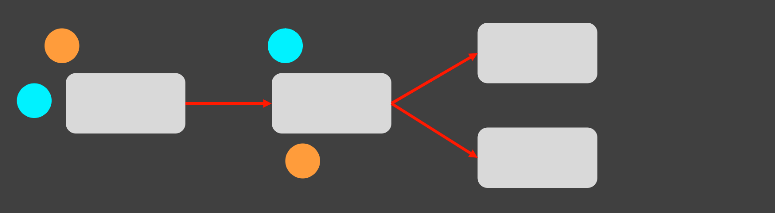
-
flow를 새로 만들다보니, 해당 flow에서는
분기 flow가 생겼다 -
살펴보니,
초록색에 따라서 주황색만 처리하거나 하늘색만 처리해야하는 분기라는 것을 알게 되었다.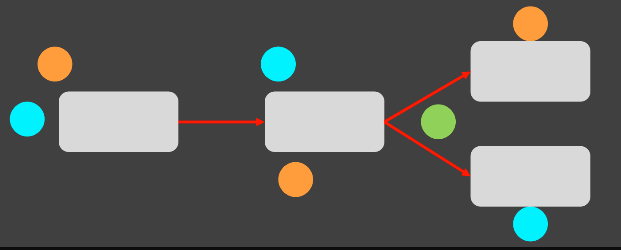
-
특정조건 초록색은분기처리에만사용되고,다른데서는 사용 안되기 때문에 ->절차적 변수(상태) 격리기법인변수의 유효범위(scopre)를 정할 수 있다.-
지역변수로 선언하거나 or인자를 함수로격리 or중괄호를 통한 block scope를 주는 방식으로 변수(상태)를 격리 byscope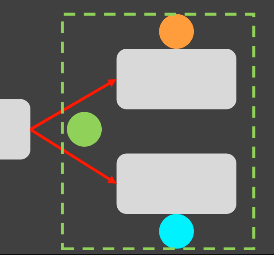
-
-
절차적인 flow에서
변수(상태) 격리 방법은 scope밖에 없다는 뜻이 된다.
-
-
scope에 의한,
격리된 변수(상태)를 추가하는 경우에는 기존 flow들을 수정할 필요 없게 된다. -
flow 시스템에서 우리가 변수(상태)로 인한 회귀테스트를 피하는 유일한 방법은
scope밖에 없게 된다.- 되도록이면 scope를 짧게, 라이프싸이클을 빨리 끝내도록 코드 작성하는 조언을 많이 들었을 것이다. 왜? 유일한 수단이다.
- 우리가 초록색(변수, 상태)를 도입했을 때, 이전 코드들을 건들이지 않아도 되는 유일한 수단, 쓸 수 있는 방법이 하나밖인
scope지정이다.
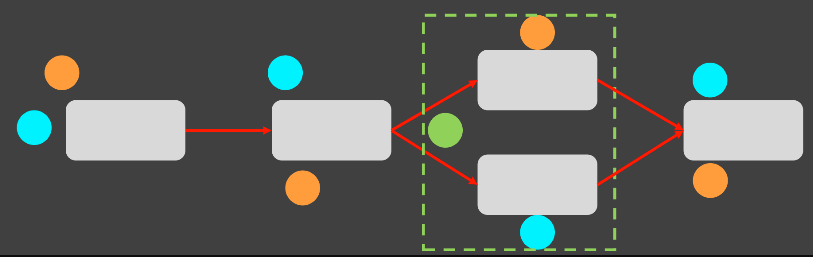
- 최종적으로 마무리 flow를 한다.
하지만 맨 마지막에 빨간색(변수, 상태)가 필요하다는 것을 깨닳는다. 사람이란 그런 것. 시간순으로 학습해서 발견
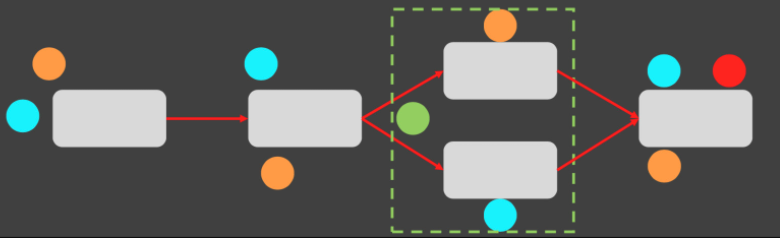
- 빨간색이 필요하다면, 첨부터 가지고 있어야할 것이다.
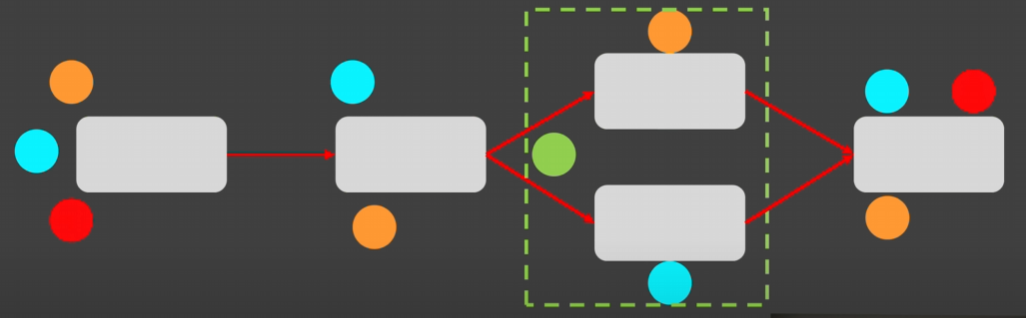
- 모든 flow가 오염되고 맨날 밤을 센다.
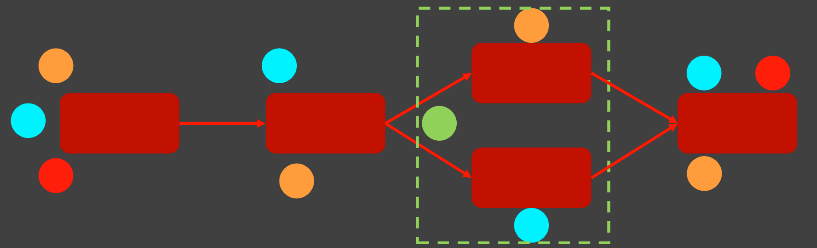
- 사람이기 때문에 어쩔 수가 없다. 맨 늦게 깨닮는다.
- 회귀테스트를 다 만들어놓고 하기 때문에 팀의 분위기가 안좋아진다.
- 처음부터 파란색, 빨간색을 알았다면… 불타지 않았을 것
-
처음부터 알려면, 내가
마틴 파울러이나퀜트 백이 되는 수밖에 없는데…- 그런데 이런 사람이 있으면, 어떻게든 돌아가는 프로그램을 만들어버리니.. 독이 될 수가 있다.
-
마틴옹이나 퀜트백이 아니라면,
flow로 디컴포지션하여 프로그램을 짜면 안된다.잘못된 것라고 확정적으로 말할 수 있다.- 우리는 이렇게 짤 수 없다.
- 무조건 상태(변수)가 새롭게 나타난다.
- 무조건 오염되어 회귀테스트가 생긴다
- 나머지 개발론이 안먹히는 사람이다. 혼자서 다 만든다.
- 코드양이 적어서 혼자서 만들긴 다 만든다.
- 복잡한 도메인에서는 불가한 방법
- 고인물인 게임이나 쇼핑물에선 가능하다.
- 이직시 고려해야한다.
- 10년간 회계시스템, 오피스를 짠 회사 -> 도메인 파악이 너무 확실함.
- 어떤 새로운 구조도 도입안할려고 함
- 이렇게 짜는게 가장 짧고 회사에 돈을 많이 벌게 해주니까
ADT(Abstract Data Type)
-
추상 데이터 타입부터는 데이터를 기준으로 세상을 바라보기 시작한다.- flow(절차적, 기능적 디컴포지션)은 절차(뭐할지를 보고) -> 절차에 필요한 데이터를 깨닮으면서 디컴포지션 -> 마지막에 아차..하고 떠오르게 되어 -> 회귀테스트 반복
- 절차지향 -> 행위를 통해 데이터 추출 -> 나중에 깨닮은 과정이 많아 -> 앞의 과정의 무시된다.
- flow(절차적, 기능적 디컴포지션)은 절차(뭐할지를 보고) -> 절차에 필요한 데이터를 깨닮으면서 디컴포지션 -> 마지막에 아차..하고 떠오르게 되어 -> 회귀테스트 반복
- LSP 치환원칙 언급 전까지, 객체지향이 제대로 발전하지 못한 시대였다.
- 지금 우리가 보기에는 잘못된 방식이지만, 당시에는 혁명적인 데이터기반 알고리즘 구현 논문이었다.
-
ADT

- 뭐할지(절차)부터 보고난 뒤 데이터가 아니라
데이터부터 먼저바라보자고 한다.- 시간제근무가 아니라 급여를 가지고 있는 직원들(데이터)를 먼저 바라본다면, -> 그 뒤에 내가 해야할일들이 생겨난다.

- 데이터 -> 해야할일(샐러리, 택스 계산하기 등)들을 보고서 데이터에 맞춰서 함수를 만들어내면, 우리가 관찰이 가능하다.

-
각 데이터에 따라 할일들이 만들어진다.
- 구조체(자료구조) -> 그에 대한 함수들
- 여기서는 각 데이터마다의 함수 시리즈 —> 방향이 중요한게 아니라
어느날 발견하게 되는 <각 데이터마다 비슷한 기능을 하는 함수>가 중요하다.
- 즉, 각 데이터—> 함수시리즈들을 놓고보니
하려는 일은 비슷한 데이터만 다른(↓ 방향)것의공통점을 발견할 수 있다.- 정규직, 시간제, 다른 형태고용자 ↓ 데이터들 모두
세금을 계산하는 것은 비슷하다
- 정규직, 시간제, 다른 형태고용자 ↓ 데이터들 모두
- 하지만,
데이터들은 다른 것들이기 때문에, 약간의 차이는 있을 뿐이다. -
따라서,
데이터모양의 차이점만 있고, 개별 flow가 아니라해야할 일(flow)의 공통점인식해야한다.- 데이터의 차이점 -> if로 데이터를 나눌 뿐이지
flow는 추상화 단계에서 인식가능하다 - 예를 들어, if문만 있으면, 어떤 데이터(직원)을 넣어도 세금을 계산해주는 함수를 만들 수 있다. 내부에 if문만 넣어서 하늘색/주황색/빨간색으로 나눠주기만 하면 된다.
- 데이터의 차이점 -> if로 데이터를 나눌 뿐이지

-
리스코프는 데이터 -> 함수시리즈를 나열하되,
들어오는 데이터가 다르면, 내부 if로 나눠주되, 중요한 것은 공통점으로 추상화이다. -
데이터에 따라 세금을 계산하는데, 세금계산만 공통점이므로
이러한 함수에는 필연적으로 내부if문이 들어간다.- **[세금을 계산]** ↓ 데이터에>
-
**[월급을 계산]** ↓
데이터에>
- 바깥에서는 [~을 계산] 공통점만 노출
- **내부에서는
**
-
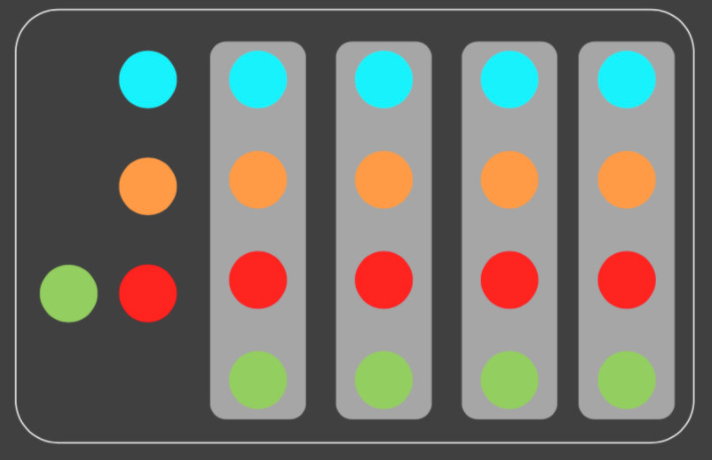
내부에서 if로 차이점을 가진 데이터들을 먹어서공통점 추상화가 가능해졌다.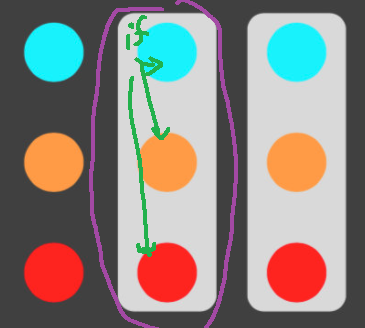
-
내부에서if문/swtich문을 이용해서서로 다른(차이점) 데이터를 먹으면뭐가 좋을까?
-
서로 다른 데이터들임에도 불구 하고
모든 기능들이 모을 수 있어 응집성(->유지보수)이 증가하게 된다-
코드 응집성의 증가로 관리가 편해진다.
- 각 직원(데이터마다) 세금계산 방법을 나눠서 함수를 만들면 유지보수가 어려움
- 단점: case(데이터)가 늘어나면 그만큼 추가해줘야한다
- 장점: 지식을 모아둘 수 있다.
- 지금도 선호하는 회사가 많다. 잘 구분도 안된다. ADT가 맞는지 확인도 쉽지가 않다.
-
코드 응집성의 증가로 관리가 편해진다.
- 이제부터는 **외부에는 ADT를 `하나의 형`으로 노출하고 싶다**
다른데이터라도>
- 하얀 네모를 통째로 하나의 형으로 부르고 싶다
- 네모의 메서드 중 1개 를 호출하면, 내부에 차이점을 먹은 형태기 때문에 외부에서는 이쁘게 나올 것이다.
각 변수(상태)들을 모두 수용가능하며,외부에는 결과값만 던져주는 이쁜 형태이다.
-
각 데이터별 특성을 안에 다 감춘 형태-
고도 추상화가 된다.외부에서는 아무런 지식없이Employee만 인식하여 좋은 얘기 같아보인다. - 팀내에
ADT를 쓰는 사람들은 이렇게 설득한다.
-
-
서로 다른 데이터들임에도 불구 하고
-
장점: 안에 등장 가능한 상태(변수) 모두를 내부if로 먹고 있어서 메소드 추가가 외부노출없이 안에서 가능 (case를 모두 알고 있음?!)

- 해결메서드를 4번재 gray로 추가했는데, 내부에 이미 모든 상태(변수)들을 알고 있기 때문에
딱 알고 있는 갯수(3개)의 분기만 해주면, 메소드 추가가 가능하다.- 확실하게 모든 분기를 알고 있으면, 메서드 추가가 쉽다.
- 해결메서드를 4번재 gray로 추가했는데, 내부에 이미 모든 상태(변수)들을 알고 있기 때문에
- 뭐할지(절차)부터 보고난 뒤 데이터가 아니라
ADT를 깨는 로직
- ADT를 깨기는 쉽지 않다.
- 바깥에서 보면 고도로 추상화되어있다.
- 내부 기능(메서드) 확장도 쉬워서 유연한 것처럼 보인다.
-
메서드 추가는 쉬웠지만,
데이터 추가는 큰 문제를 발생시킨다.
- ADT는 데이터(상태) 추가에 쥐약이다.
-
상태 하나 추가할 때마다, 모든 메서드가 if로 먹을 수 있게 분기하는 코드를 추가해야한다.- 작업량이 엄청 늘어난다.
- 클래스 내부 모든 메서드를 불태워야한다.
- ADT를 주장하는 팀원을 이기는 방법은 =
OOP를 선택하게 하려면- 우리회사는 Employee의 다양한 고용형태를 수용해야한다.
- 만약, 20년간 새로운 고용형태는 회사에 없었다고 말한다면 못이긴다.
- 책에서도 기능만 추가되고, 데이터는 변화가 없다면 ADT는 나쁘지 않는 선택이다.라고 얘기하고 있다.
- my) OOP에서 자식이 늘어나지 않는다고 가정하면…?
-
데이터 추가외에 공통이 아닌 메서드 d()의 문제도 못푼다. 즉,
특정 데이터(상태)의 전용메서드 추가가 어렵다.
-
리스코프 치환원칙에서 d()메서드는, 하늘/주황/빨간(상태)의 분기에서는 작동안해야한다. -> 초록색 외의 상태가 들어오면
임의의 예외값을 내어놓아야한다. -> 특이해지는 상황- if a if b … if d 의 context만 있다가
- if d (else) 예외값을 내어놓는 이질적인 context
- 바깥에서는 d or null이기 때문에, D객체로 볼수 있다고 봄. instanceof를 이용하여 디텍팅용으로 쓸 수 밖에 없다.
-
-
ADT가 성립하는 경우는 2가지를 만족해야한다.
- 상태(변수, 데이터)가 더이상 확장되지 않고
- 안에 소속된 메소드들이 모든 상태들에 대해 결과값을 가지는 메소드일 때만
- 그럼에도 불구하고 ADT를 쓰는 회사가 있다?
- 전체 구성원이 d()의 경우를 미리 알고 있어서, 그거는 원래 그래 라고 할 경우, 굉장히 힘들어진다.
-
ADT는 굉장히 제한적이라고 할 수있다.
-
안타깝게도, 우리가 객체지향을 짤 때,
대부분 ADT로 코딩을 한다.- 따라서 남이 유지보수할 때, ADT의 문제점에 봉착하게 된다.
- 우리는 이것을 legacy라고 부름.
- 남들은 legacy로 안보는게 문제
- 따라서 남이 유지보수할 때, ADT의 문제점에 봉착하게 된다.
- ADT를 알아야하는게 핵심이다. 알아야 ADT가 아닌 코드르 짤 수 있기 때문
- my) ADT: 내부 if로 모든 상태를 분기로 먹어서, 서로 다른 데이터의 공통기능들도 모은 것.
OOP

-
ADT와는 완전히 다른 접근방식의
추상화이다.-
상태없이 미리 <해야될 연산만 추상화>해놓고
-
추상화된
연산이 <상속>받는 무언가를 만드는 방식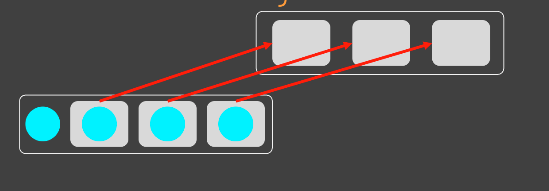
-
뒤늦게 상속하는 이유는 바로연산이 달라지는 <서로 다른 상태>에 따라 <형을 새롭게 만들어 나가기> 위해서
-
-
따라서 객체지향은
상태마다 형을 늘려가는 구조다.
- ADT는
내부if로 서로 다른 상태를 먹어서하얀색 박스 안에 때려박은형을 줄여가는 구조였다. - 객체지향을 사용하면, 상태에 따라 -> 형이 늘어난다.
- 게다가 상태에 따른 형을 통합하는 추상형이 먼저 정의되므로 +1로 엄청 늘어난다.
- ADT는
-
연산 정의 -> 상태에 따라 다른 연산을 가지는 형을 정의 -> 구상형들이 많아진다.
- 대표적인 것이 추상형이지만, 구상형이 주인공들이고 점점 늘려나가는 방식
- 인터페이스(추상형) 메소드를 호출하도록 코드를 짜면 ->
레인지 바인딩되어있는 구상형의 메소드가 호출된다. 레인지 바인딩을 이용해서형을 늘려가는 OOP
-
ADT vs OOP 한눈에 보는 방법
- 형이 줄었다? ADT
- 형이 늘었다? OOP
- 추상형 + 1 -> 구상형 으로 최소 ADT보다 1개의 형을 더 가짐
-
상태가 늘어날 때 OOP 압도적으로 유리하다.
- ADT는 상태(초록색) 증가 -> 내부 메소드 전체가 불탐(메소드마다 초록색 분기 처리 다 넣어줘야함.)
-
OOP의 상태(초록색) 증가 ->
- 해당 초록색의 형이 추가하고 -> 메소드를 정의하므로
타 상태의 타 형에 영향을 주지 않는다. - 메소드가 상태마다 함수안에 if분기를 만들었던 것에 비해, 상태마다 객체의 클래스형을 만들어버림.
- 해당 초록색의 형이 추가하고 -> 메소드를 정의하므로
-
저번시간부터 배운 것,
-
ADT에서는 [공통메서드]에서상태만큼 함수안에 if분기 -
OOP에서는상태만큼 class(형)을 만듬-> [별도의 메소드]-
if를 사용자client쪽으로 옮길려고
-
함수안에 if(ADT)를 없애는 방법은,사용자client쪽으로 밀어내면서,if분기수만큼 (형 -> )객체를 만드는 수 밖에 없다. -
그림상으로는 안보이지만,
if -> 클라쪽에서 객체 생성을 선택하는 것으로 밀려났다.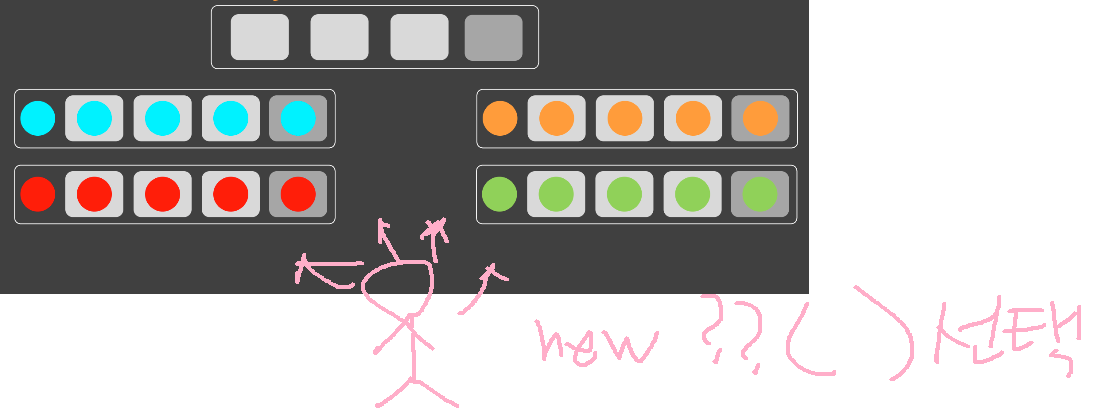
-
-
-
OOP는
복잡성 폭발을 제거하려 한다.-
if 2단계 -> 전략객체가 2층으로 필요함. cf) if 1단계 -> 전략객체가 1개 필요함.
- 전략패턴안에 있는 전략객체가 또다시 전략객체를 가져야함.
- 2개다 바깥에서 공급해야한다.
- Movie가 2단계 전략class를 쓰는 예이다.
- policy가 condition을 갖는 것으로
- 원래는 if 2단계였을 것이다.
- if policy if condition
- 마지막 클라코드:
- policy <- 생성된 condition을 꽂아줌
- movie <- policy를 꽂아줌
-
그냥
공식: 클라쪽으로 if를 옮기고, 그 분기(상태)만큼 형을 만들어서 객체생성으로 선택한다. -
아래 그림처럼, 함수안에 있던 원래 if는 4가지 상태에 따른 4가지 분기를 가질 것이다. -> 하지만
내부if분기수 만큼->추상형에 따른 구상형을 4가지 형을를 만들어놓고,바깥에서 객체 생성으로 선택하게 하여 if를 제거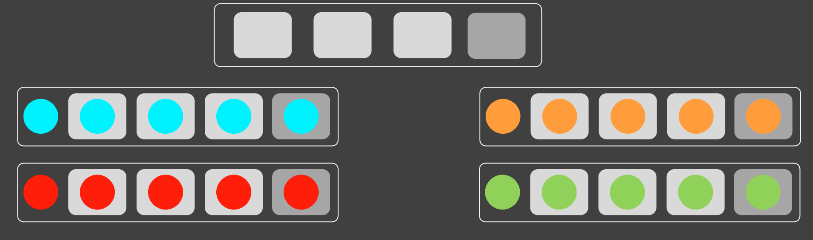
-
-
이렇게 OOP를 쓰면
상태 추가에 강하다.나머지 회귀테스트가 안일어난다- 앞으로 우리는 Employee 고용형태에 재택근무자, 자유시간제 등 class(형)을 추가함으로써 -> 내부if분기를 대신하여
상태 추가를 할 수 있다.
- 앞으로 우리는 Employee 고용형태에 재택근무자, 자유시간제 등 class(형)을 추가함으로써 -> 내부if분기를 대신하여
OOP의 문제점
-
상태 추가(-> 형 추가 생성)이 아닌
기능 추가를 하면다같이 불타버린다.
-
객체지향에서
기능 추가시 굉장한 비용이 든다.- 같은 말로
객체지향에서 성급한 추상화시 굉장한 비용이 든다. - my) 기능 추가는 추상체에서부터 시작하나보다.
- 같은 말로
-
다른말로는
아직 추상화가 제대로 되어 있지 않으면 함부러 상태를 늘리면 안된다.- 상태가 1개일 뿐이라면 추상체 기능 추가 1실험을 -> 구상체 1개에서만 하면 되지만.

- 많은 상태 = 형 = class가 있는 상황에서
기능 추가시... 모든 기능을 추가해줘야한다.
- 상태가 1개일 뿐이라면 추상체 기능 추가 1실험을 -> 구상체 1개에서만 하면 되지만.
-
객체지향에서
-
**
성급한 추상화 하지마라고 말했지만, 우리가 퀜트백이 아닌 이상한번에 다 추상화 못한다. -> 더 생각해보고 추상화해 라는 말이 아니다.생각해봤자 한번에 다 못한다. **-
대신,
기능 추가/삭제는 초반에 자주 일어나니 깨닮음이 발생하기 전까진, 상태를 추가하지말고 최소한의 상태(구상체)로만 테스트하자- 기능 추가시 , 확인을 해야하는
key case까지만 구상체를 늘려 테스트
- 기능 추가시 , 확인을 해야하는
추상화를 계속 반복해서, 정교하게 만들어가는 과정 중에, case를 확인할 수 있는 애들만 구상class를 만들자.확장은 나중에 하자.
-
대신,
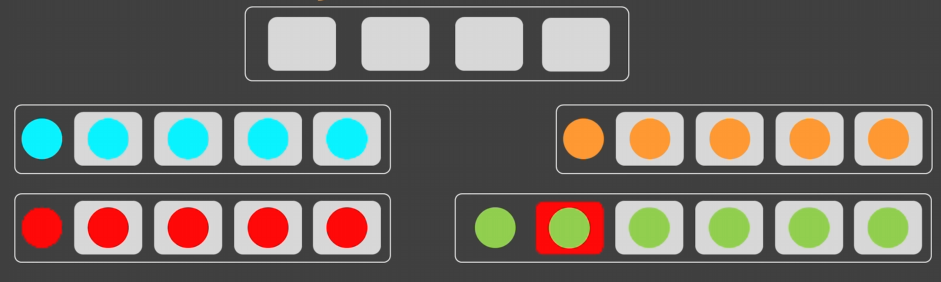
- 여기도 리스코프 치환원칙에서의 d()가 추가되는 문제는 똑같다.
- 외부에서 abc()만 가지고 있는 추상체(인터페이스)로 통신시 -> d()를 인식할 수 있는 방법이 없다.
-
하지만, 저번시간에 배운 것처럼
제네릭을 이용해d()를 외부에서 구현해서 인식한다.- 제네릭말고 다른 해결방법도 있다.
- 제네릭을 통해 구현을 클라이언트 쪽으로 미루는 방법