OBJECT 13 개발자의세계 with ADT(코드스핏츠)
object 책을 강의한 코드스핏츠 유튜브 요약
📜 제목으로 보기
- 참고 유튜브 : https://www.youtube.com/watch?v=navJTjZlUGk
- 정리본: https://github.com/LenKIM/object-book
- 코드: https://github.com/eternity-oop/object
- 책(목차) : https://wikibook.co.kr/object/
ch13. 개발자의 세계3 ADT버전

-
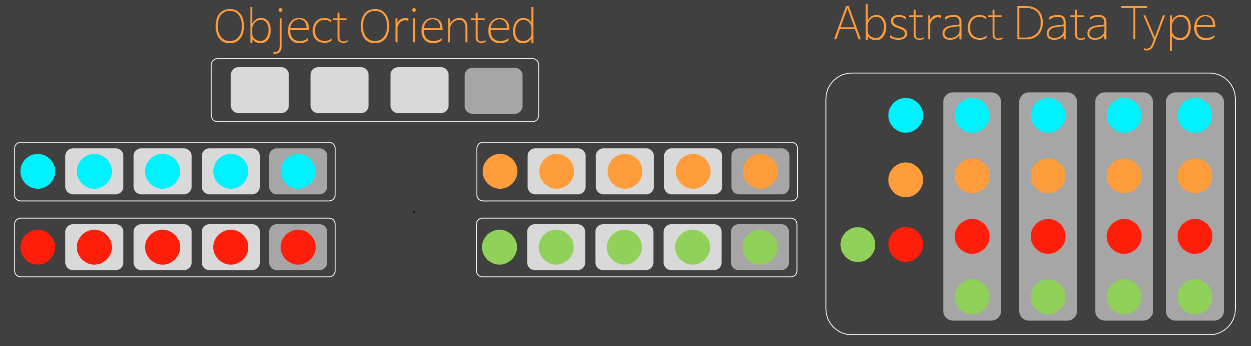
이미 OOP로 만들어 놓은 상태에서 -> ADT로 바꿔서 그 차이를 이해하는 시간이다.
- 왜냐면 우리는 습관적으로 ADT를 만들고 있기 때문
- 왜냐면 우리는 습관적으로 ADT를 만들고 있기 때문
-
하지만, ADT는 현실에서 쓸 수 없다.
-
형(상태, 변수, 분기)가 확장되는 것은 프로젝트 진행상 당연한 것이기 때문
- 상태가 추가하든, 메소드가 추가되든 ADT는 취약하다.
-
형(상태, 변수, 분기)가 확장되는 것은 프로젝트 진행상 당연한 것이기 때문
저번시간까지 모델
-
OOP를 통해, (추상화 -> ) 형이 뿌러나는 형태로 전개된다.
- 왜? 내부if로 먹던 것을 -> 외부에 형으로 치환했으니 with 추상화, 전략패턴

- OOP에서는 형(해당 데이터)을 기준으로 -> 연산을 확장해나간다.
-
자식/구상체마다 상속/구현해서 연산을 다르게 구현해나간다는 뜻
- 이 연산은 이놈에서는 이런 뜻 / 저놈에서는 저런 뜻
-
자식/구상체마다 상속/구현해서 연산을 다르게 구현해나간다는 뜻
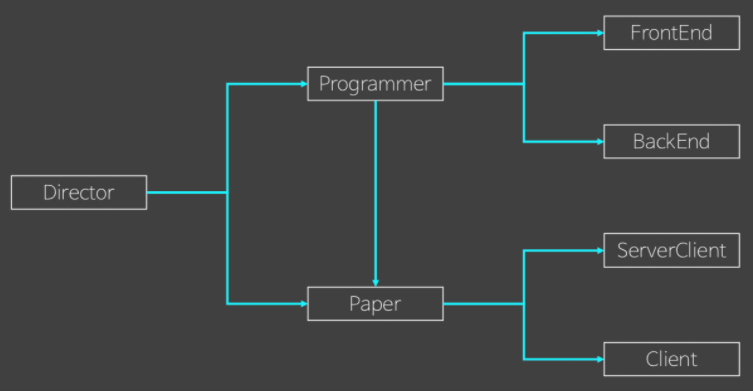
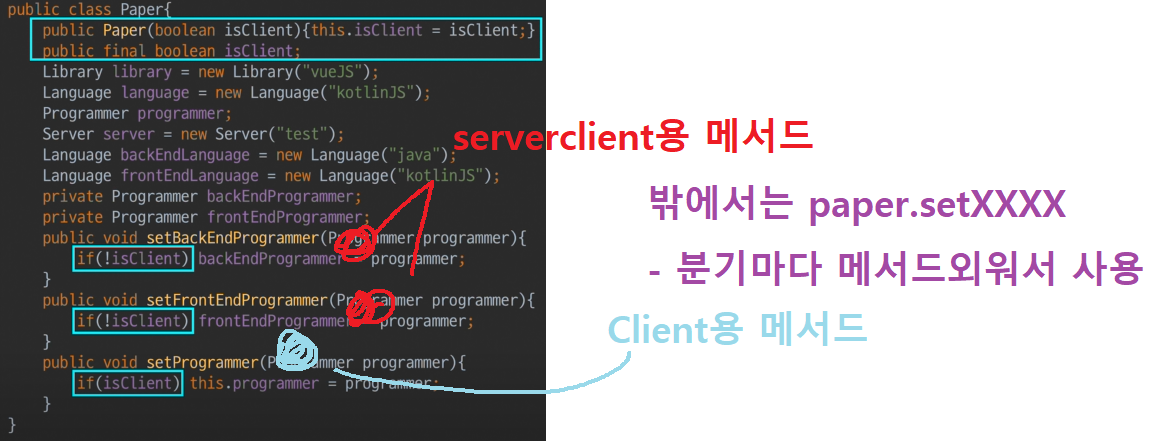
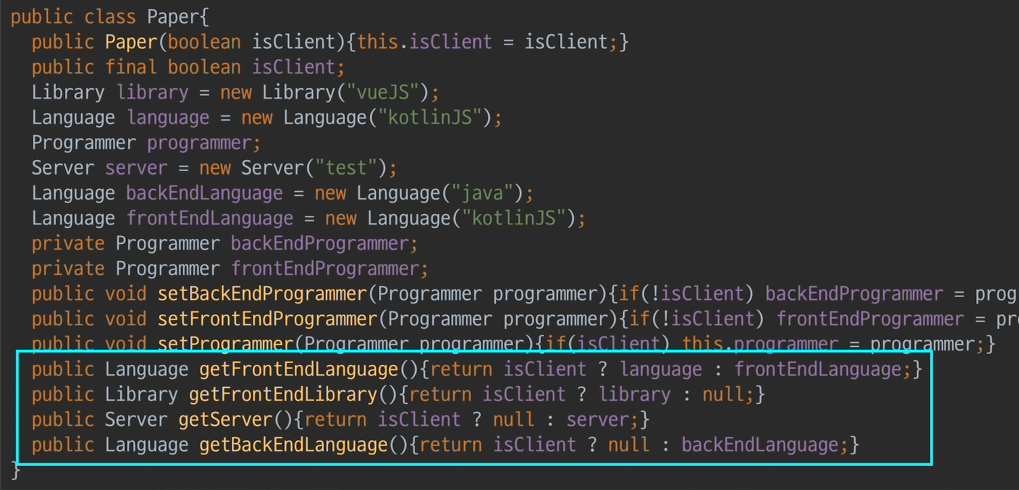
Paper 통합


- 저번시간까지, Paper 인터페이스는 아무것도 없지만,
- Paper를 확장해서(상속, 구현) -> 여러 속성과 메소드를 가지는 Client/ServerClient를 뿌러나면서 형을 만들었다.
-
이것을
ADT로 합치면 어떨까?"이건 뻔하게 플젝 종류가 2개 밖에 없으니, 굳이 형으로 나눌 필요가 있나?""내가! 공통점을 Paper 1개로 다 처리되게 묶을 수 있어. 뿌러나도록 하지말고 고도로 추상화된 Paper 1개로 끝내자."

-
최소 구상체로 추상화부터 -> 점점 뿌러나가는 방식의 OOP가 아니라 내부if로 먹어버린 1개 형의
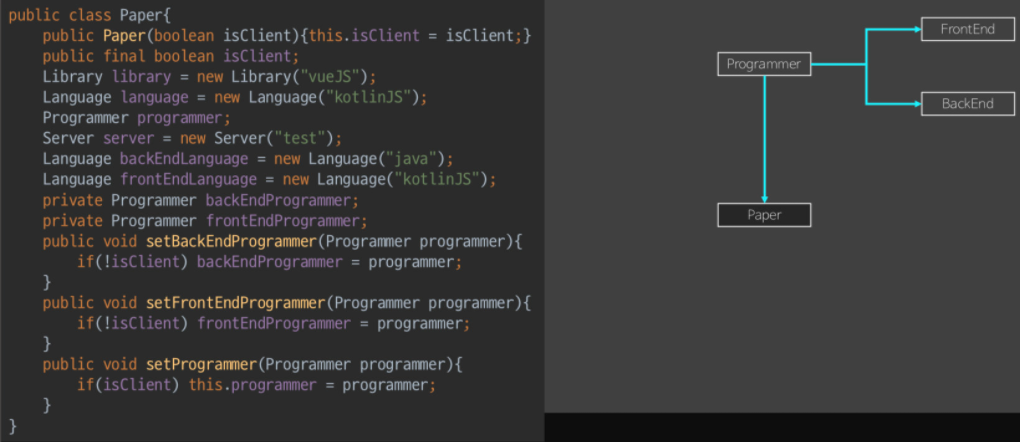
ADT으로 구현한Paper는 뒤에 아무것도 없어졌다.-
Paper가 극단적으로 보이는 이유는, 인터페이스가 메서드(Operation)가 하나도 없었기 때문이다.
따라서, Clinet/ServerClient 전체 속성+메소드들을 copy해와서 붙혀넣었다.
- 만약 Paper에 메소드가 있었다? -> 공통메서드이다 -> 2 구상체는 똑같은 메소드를 구현했을 것이다 -> 합치면 겹쳐서,
로직을 통합(힘든 과정임)하는 정도로 됬을 것이다. - 공통기능이 Paper에 별로 없다? -> 복붙만하면되고, 2구상체의 공통
로직을 통합(빡셈)하는 과정이 없어서 쉽다.
- 만약 Paper에 메소드가 있었다? -> 공통메서드이다 -> 2 구상체는 똑같은 메소드를 구현했을 것이다 -> 합치면 겹쳐서,
-
ADT는 내부if와 함께 통째로 은닉화한다고 했으니 ->
2가지 분기 -> 1가지만 가지고 client이다/client아니다(=serverclient다)의 boolean으로 결과값만 반환으로 나타내보자.- 2case밖에 없으니 -> flag로서 if분기를 만든다.
-
ADT의 문제점 ->
통째로 집어넣으니, 특정분기가 아닌데도, 데이터들을 담을 속성을 모두 가지고 있다.- 정규직 근무자임에도 불구하고
- 시간제 근무자가 아니다 boolean
flag변수 - 시간제 근무자가 가지는
해당분기용이 아닌 변수들다 가지고 있어야함.
- 시간제 근무자가 아니다 boolean
- 정규직 근무자임에도 불구하고
-
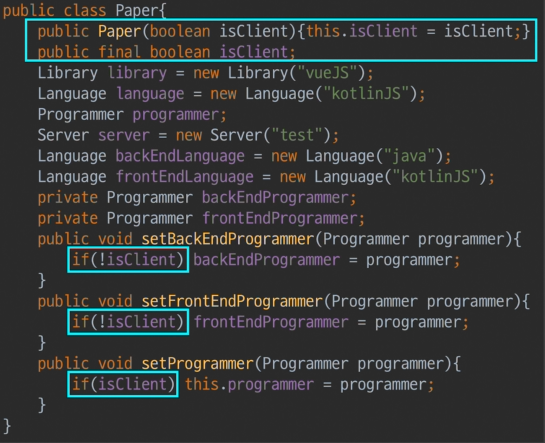
-
문제는 분기를 담고 있는
flag변수의 여파가 끝나질 않는다는 것- 오버라이딩메소드가 없어서 -> 메소드내 코드 통합(빡셈)은 없었지만
-
모든 코드는 모든 상태를 커버하도록 바꿔야한다.
- 모든 메소드는 client든 serverclient든 누가오든지간에 다 커버가능한 상태로 변경
-
은닉화된 내부if분기에서
분기마다 서로 다르게 사용되는 메서드들은 (외부에 노출되지 않으니) 외울 수 밖에 없다.- client일 때 -> setProgrammer사용 (해야 된다고 외워야한다)
- serverclient일 때-> setBack/setFrontProgrammer사용 (해야 된다고 외워야한다)
각각의 분기마다 사용메서드를 외워야한다. 통째로 집어넣고 은닉화해서. ** **추상화하면 다 공통이라.. 외울필요 없는데- 뉴비 context들을 어떻게 인식? 처음에는 모른다. 팀내에서
지식노하우라 부르면서 외워야함- 지식과 노하우는 다르다.
-
ADT 내부 메소드들은 추상화되어있다 = 형을 인식안해도 된다. -> BUT 실제로 사용되는 메소드들은 내부if분기마다 달라진다.
Programmer 통합
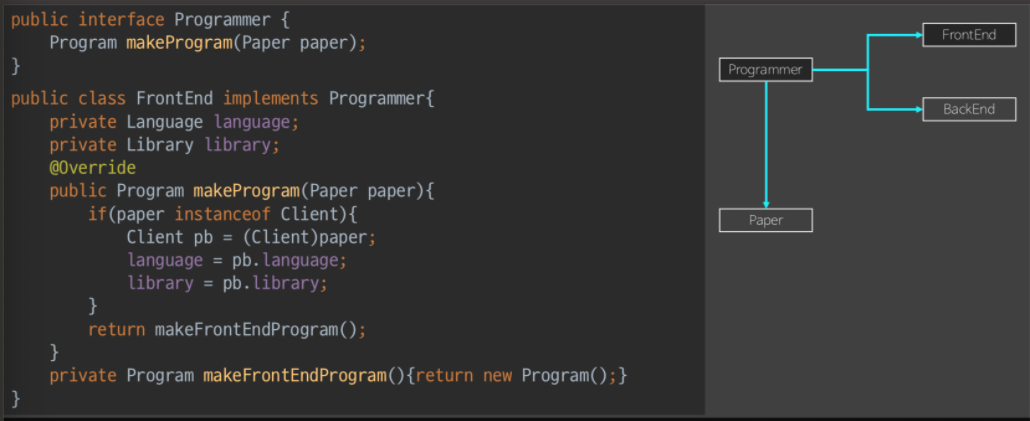
- paper와 달리, 인터페이스에서 메소드(Operation)을 가짐
- 프론트
- language와 library를 가짐
- 메소드 오버라이딩함.
- paper를 (자식들 다 받아주는) 인스턴스로서 인식했었는데,
- 지금은 paper가 ADT로서 하나의 추상형으로 통합되었므로 못쓴다.
- paper를 (자식들 다 받아주는) 인스턴스로서 인식했었는데,
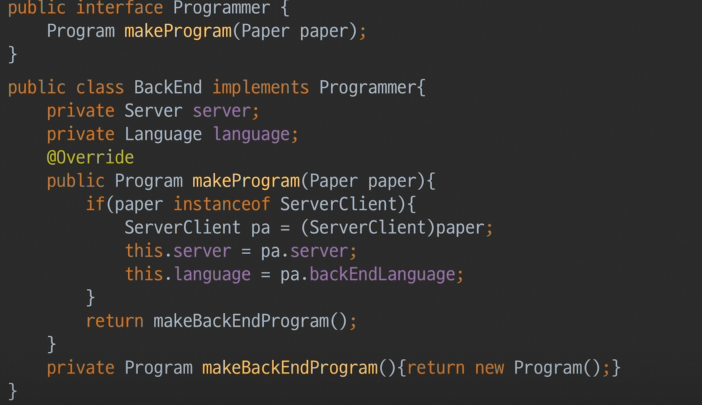
- 백엔드
- 마찬가지로 오버라이딩 메소드 및 paper인스턴스 못쓴다.
- 그외 것들도 못쓴다.
-
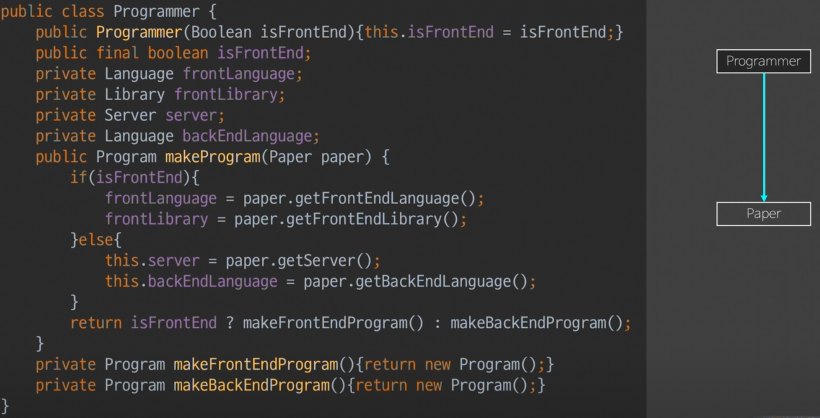
프+백 -> Programmer로 로직 통합(빡세다고했음)을 살펴보자.
- 프론트인지 아닌지로 상태가 flag로 나눠졌다.
- 뿌러났던 class형 2개가 —> flag변수가 들어와 2가지 상태를 나타낸다.
- language는 둘다 가지고 있던 것
- 인터페이스의 공통기능 메서드operation이 아닌 코드를 통합할땐, 첫번째로
이름 충돌이 일어난다. - ADT 통합시, 이름 정하는 규칙이 문제를 발생시킨다.
- 인터페이스의 공통기능 메서드operation이 아닌 코드를 통합할땐, 첫번째로
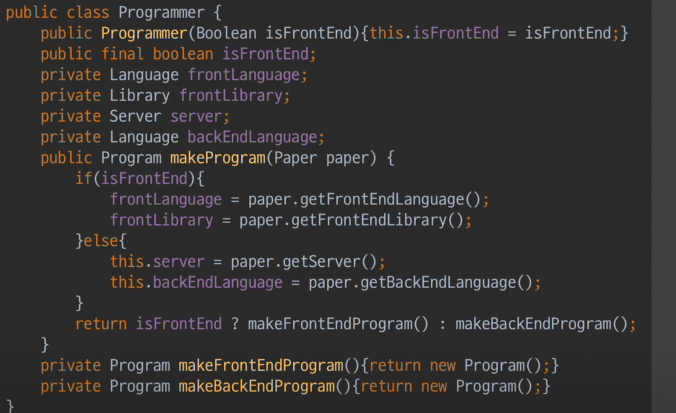
- 통합하는 순간부터
이름 충돌난 변수를 —> 분기별로 표시를 하는나쁜이름(긴)의 변수를 써야한다- frontLanguage, backLanguage
- 추상화도 layer(단계)가 있다.
변수간 서로 단계에 맞게 추상화를 해줘야한다.- library는 front만 가지고 있음에도, language와 추상화단계를 맞춰주기 위해
library -> frontlibrary로 변수명을 변경하였다.
- library는 front만 가지고 있음에도, language와 추상화단계를 맞춰주기 위해
- server는 backend만 가지고 있지만, 추상화단계를 맞춰줘야한다? backendServer? -> (가만히 두어도 추상화단계가 맞아서?? )중립적인 이름이라서 그대로 남겨두었다. 망설인 것이다. (frontServer라는 것이 존재했더라면 변경해줬을 것이다.)
- 위에서 보는 것처럼, ADT의 통합시
사람이 손으로 이름충돌을 다 계산해서 변수명 재설정해줘야하는데, 문제는상태 추가가 시간순으로 일어나므로 -> 매번 통합해줘야한다 ->평소에도 이름을 나쁜이름으로 방어적으로 짓고 있게 된다- 농담이 아니라 SI회사들 중에 변수명을 20자이내로 못짓게 하는 회사들이 진짜 많다고 한다. 형 추가하여 뿔려나가는게 아니라 고도추상화로 ADT 한곳에 때려박다가, 새롭게 추가된 것은 변수충돌을 일으키므로..
- 현재 ADT로 하나로 통합된 Programmer는 boolean flag를 통해 프or백인지 알 수 있게 된다.내부if로>
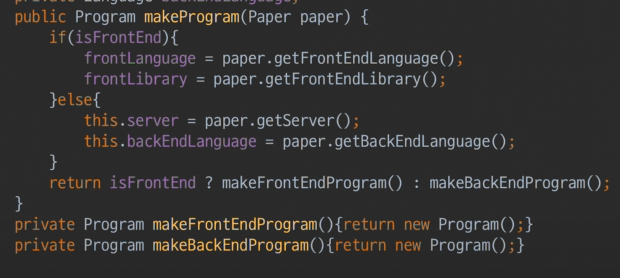
- makeProgram은 이제 코드수준(쉬운편)의 결합을 해야한다.
- 상태에 따라 프론트코드 or 프론트엔드 아닌거(백엔드)코드만 가져오면 된다.
- if를 통해 하나의 함수로 모여들게 됨 -> 지식의 통합 -> class마다 분산되어있던 지식 2개가 -> 1개 노하우로 통합되어, ADT주장하는 사람들이 지식통합으로 착각하는 경우가 많다.
- paper를 받아와서 프론트의 language+library를 정하거나 or 백엔드의 server+language를 정해야하는데,
ADT기 때문에 paper에서뿌러나는 형의 다형성을 쓸 수 없음->같은 context를 가질 수 밖에 없음상태이다.- 프로그래머가 이미 ADT다. paper도 ADT다. ADT의 2번째 문제점은
형을 결합할 수 없다.는 것이다. OOP에서는 나=다형성 쓴다 -> 받아온 paper도 다형성을 쓰려고 한다. - 하지만, ADT는 상태를 내부에 감춤 -> 바깥에서 볼 수 없으니
내 상태를 이용한 분기만 사용가능하다 -> 들어오는 paper가 뭐든 간에, 내 상태=프론트엔드 이므로 -> 프론트엔드 분기로서paper에게 그에 맞춰서 기능을 제공해주도록기능 추가 의도하게 된다. -
즉, ADT에서는 외부의 paper에 대해
if paper == client 인지알 수 없다. 내부에서 감추고 paper스스로만 알고 있기 때문에-
외부에서 paper만 받아서는 client인지/severclient인지 확인 불가능-> 니가 누군지는 모르겠지만, 추상화된 paper니까.. 나에게 맞춰서 front내용(frontlanguage + frontlibrary)을 전달해줘 -
OOP는 다형성을 쓸 수 있다. = paper를 받으면 누군지 알고 있다.
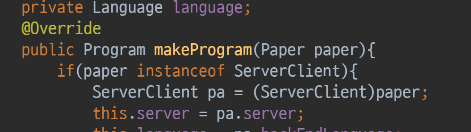
-
- 프로그래머가 이미 ADT다. paper도 ADT다. ADT의 2번째 문제점은
- 프로그래머의 내부if분기 -> 상태(프or백)에 따라 사용되는 paper의 메서드가 나눠져버린다.
- ADT그림을 보면, 분기에 따라 한 메서드가 다르게 구현되도록 통합적이 메서드 구조가 되었다고 했는데
- 여기서보니.. paper는 client일때랑 serverclient일때랑 서로 다른 메세드를 부르게 된다.
- 그럼에도 불구하고 paper는 구분이 외부에서 안되니… 통합처럼 부를 수 밖에 없다.
- ADT에 의해 만들어진 paper의 메서드들 -> 내부적으로 더 심각한 문제에 당면하게 됨..
- if가 중첩될수록 ADT에서는 중첩을 더 만들어낸다.
- 프론트인지 아닌지로 상태가 flag로 나눠졌다.
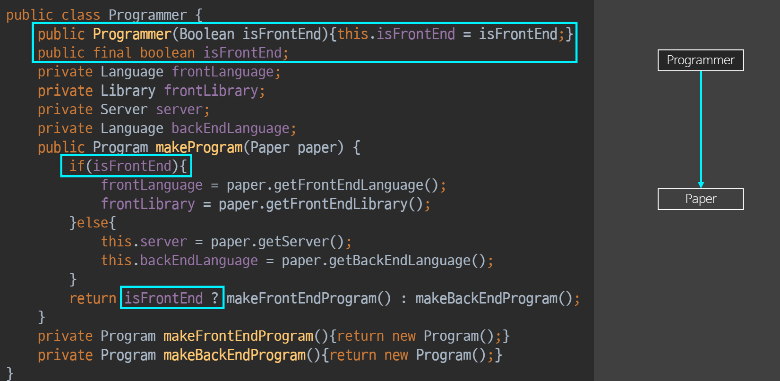
-
flag변수를 도입 -> ADT가 되어 내부 상태를 관리한다는 것은- 내부에서 if를 더 만들어낸다.
- 또한,
외부에서 상태를 판단못하는 다른 ADT paper에 대해서 내부 if에 의해메서드 확장도 만들어낸다.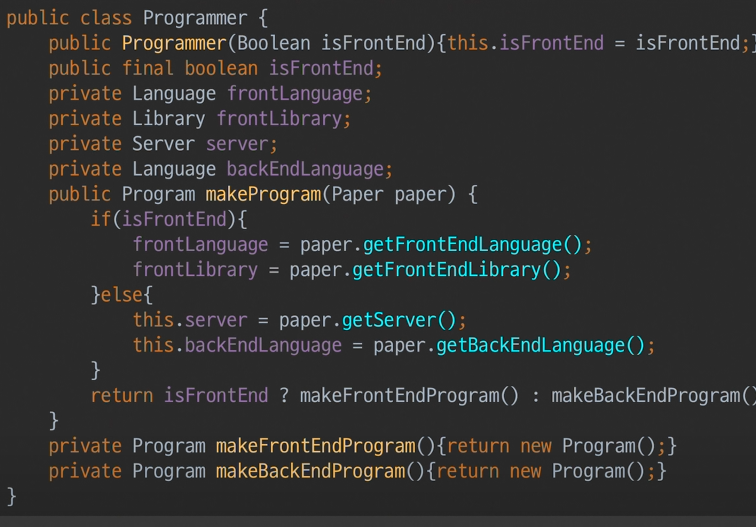
-
이 때, ADT를 만든 사람은
"걱정마. ADT는 기능확장은 잘돼"라고 이야기를 한다.
- 위와 같이 만들어준다. ADT는 정해진 3개 상태에 있어서, 상태확장이 아니라 기능확장은 껌이라고 하면서 위와 같은 코드를 만들어준다.
-
다시, client인지/아닌지에 따라서 -> frontlanguage를 주는 방법이 달라지고, library는
null을 반환하기도 ->context가 달라짐.- 그림상으로 다 ADT는 내부if 분기별 다 커버하는 함수(세로방향)를 만들어낸다고 했는데,
null반환하는 순간 커 버 못하는 것이 되어버린다. 전용함수
- 그림상으로 다 ADT는 내부if 분기별 다 커버하는 함수(세로방향)를 만들어낸다고 했는데,
-
다시, client인지/아닌지에 따라서 -> frontlanguage를 주는 방법이 달라지고, library는
-
ADT는 자동으로
그림과 같은 함수를 만들 수 없게 될 수 밖은 구조이므로형(3개 상태)이 확정되고, 프로세서가 확정되어도 ADT는 쓰면 안된다!!
- 위와 같이 만들어준다. ADT는 정해진 3개 상태에 있어서, 상태확장이 아니라 기능확장은 껌이라고 하면서 위와 같은 코드를 만들어준다.
-
ADT판단 방법: 내부if분기에 따라 다른 context가 다르다.
-
ex> 한쪽 분기에서는 null을 return한다.
- ADT회피 방법: 차근차근 만들어가면서 연산부터 -> 구상체(형)을 뿔려나가는 식으로 …?
Director
기존 Director
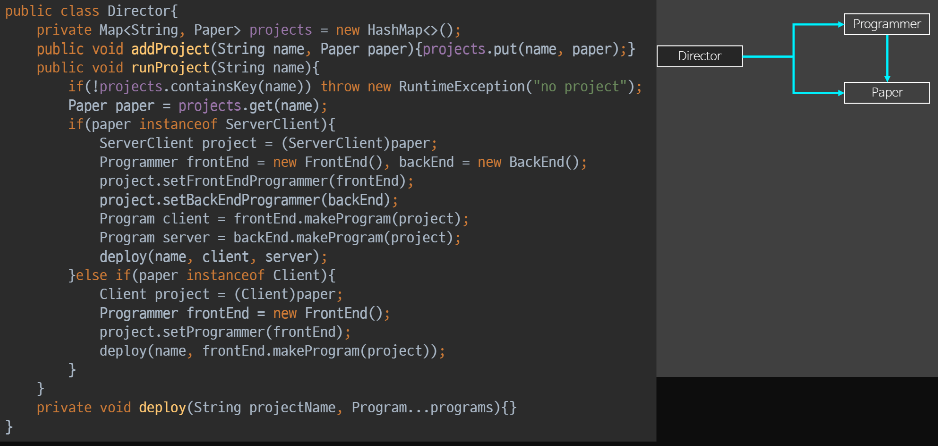
ADT버전 Director
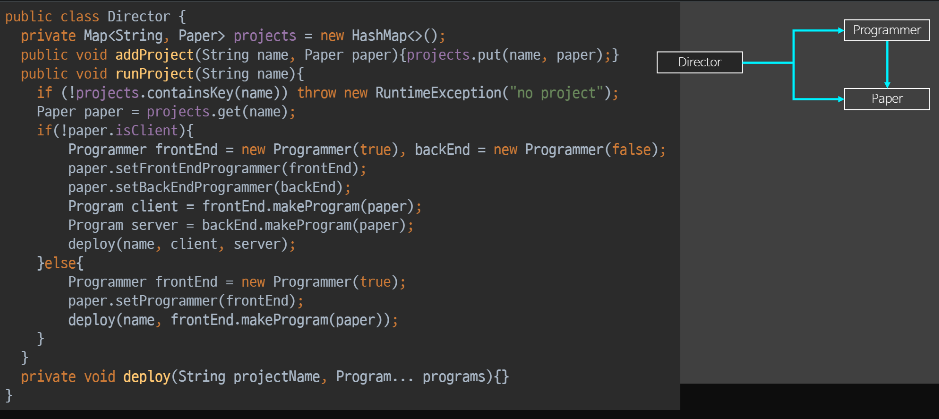
- 더 무서운 점은, Director코드가 많이 달라지지 않고, 이상해보이지 않는 다는 것이다.
- paper의 형에 따라서 여러 장치들을 걸고 있다.
- Director에서 접근하려면 누가 뭐래도 paper의 내장을 까는 수 밖에 없다.
- paper의 타입(c/s)모르고서는 director의 분기를 할 수 가 없다.
- ADT의 상태를 외부에다가 내장을 까지 않는 이상, 분기조차 안되게 된다.
- 프로그래머가 정의했던 setXXX를… 더이상 paper가 가져갈 수 없으므로
- paper는 get시리즈만 가능. set시리즈는 못가져간다. Director가 하는게 setXXX이므로
-
ADT는 기껏해야 내부상태를
은닉할 수 있는게 get밖에 안된다.- set자체는 디렉터가 해야하는 일이다. 디렉터의 존재의미니까 paper를 옮길 수 없다. -> paper의 내장(상태 = isClient를 외부 메서드로 제공)을 까서 분기를 시킬 수 밖에 없다
-
ADT의 결말: adt를 활용한 context(Direct의 context)에서 작동할 때, setter를 만들면, ADT의 내장이 다 까지게 된다.
- ADT의 폐단
- 캡슐화 및 은닉화 다 깨먹게 됨(ADT를 이용하는 형에서 setter를 쓸 때?)
- 분기별 context가 일치하지 않는 getter를 양산
- 결과적으로 본인의 상태를 추상화하는데 실패함.