클린아키텍쳐 01 환경설정과 infra, domain, data_layer
python clean architecture
📜 제목으로 보기
- 클린 아키텍쳐
- 1 데이터베이스 및 인프라 계층
- 01 환경 세팅(pylink, flake8, pre-commit)
- 02 src, infra 폴더 세팅
- 03 config설정
- 04 entities 설정 및 생성
- 05 python console에서 config + entities 2개 모듈로 DB연결 및 table생성
- 06 (DB연결 후) engine만(DB생성가능) 소유하던 DBConnectHandler를 CRUD를 위한 session소유 context manager화
- 07 repo 설정 및 fake.py(Repo) 생성하기
- 08 설정완료된 프로젝트를 push후 작업할 br을 딴 뒤, local원본레포삭제(.db챙기기) 후 특정브랜치만 clone하여 개별작업하기
- 2 Repository와 PyTest
- 01 User Repository 작성
- 02 _test.py에서 CREATE(insert) 메서드 테스트
- 01 원본메서드 내부에서 확인할 생성 데이터를 namedTuple(불변클래스)의 객체로 생성해서, 반환한다
- 02 test메서드에서는 return물을 받아 print한다
- 03 pytest에서는 -v + -s옵션을 가한다
- 04 namedTuple의 typename을 entity와 동일하게 준 것의 장점을 살려, insert메서드의 return type 명시 및 docstring도 수정해준다.
- 05 handler의 engine -> execute sql query를 이용해서, 생성된 데이터를 print없이 DB데이터로 필드끼리 assert로 비교한다
- 생성 -> sql로 로드 -> 비교 전 db속 데이터는 sql로 삭제까지 해준다.
- 03 pre-commit 설정에 pytest 추가하기
- 04 upstream(내꺼라면 remote)에 push해서 해당 작업br를 확인한다.
- 3 Domain layer 및 models, use_cases 개발
- 01 src> domain > models, use_cases 모듈 생성
- 02 repository에 있던 namedTuple(“Users”)를 domain > models>users.py로 옮기고, Users entity는 UsersModel로 취급하기
- 03 select_user(SELECT)메서드를 객체가 부르는 static메서드인 @classmethod로 정의
- 04 select메서드에 대한 test메서드 작성
- 05 PR후 동일br에서 다른 작업이 끝났을 때
- 06 github에서 만든 타 작업br을 가져오되, 최신master를 rebase하고 사용하기
- 07 clone한 폴더 new setting(최초)
- 08 pet repository 개발
- 4 insert, select 메서드들의 Interface 제작
- 참고
- 1 데이터베이스 및 인프라 계층
클린 아키텍쳐
1 데이터베이스 및 인프라 계층
01 환경 세팅(pylink, flake8, pre-commit)
-
backend-python폴더 생성 >wt -d .로 터미널 열기 >code .vscode열어놓기 -
터미널 폴더경로에서 git, 가상환경 세팅
-
깃 초기화:
git init -
가상환경 직접 생성:
pip install virtualenv-
python -m virtualenv [-p python310] venv- 리눅스:
virtualenv -p python3[10] venv
- 리눅스:
-
가상환경 터미널 실행
-
.\venv\Scripts\activateor. .\venv\Scripts\activate- 리눅스:
. venv/bin/activate
- 리눅스:
-
-
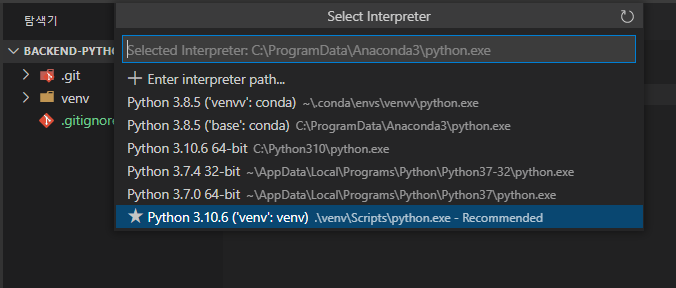
vscode에서 생성된 가상환경 select되었는지 확인
-
F1 > python interpreter > 확인
-
-
-
pylint 패키지 설치후 .pylintrc세팅
-
. .\venv\Scripts\activate -
pylint 패키지 설치후
.pylintrc파일 생성-
pip3 install pylint -
pylint --generate-rcfile > .pylintrc -
pylintrc 파일 수정
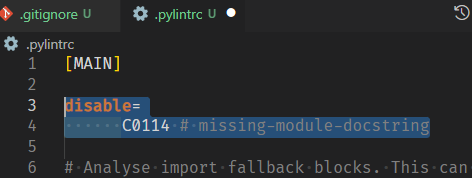
-
docstring 없어도 무시하게 설정해준다.
-
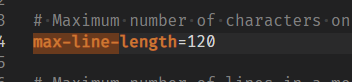
max-line-length를 100 -> 120으로 수정해준다.
-
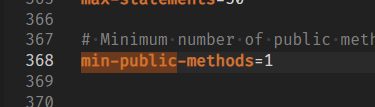
min-public-methods 수를 2->1로 수정해준다.
-
-
-
-
flake8, black 패키지 설치후
.flake8세팅-
pip3 install black -
pip3 install flake8 -
pylint와 달리
.flake8파일을 vscode에서 생성해준다.- 파일별 ignores를 F401을 걸어줘야한다.
[flake8] ignore = E722, W503 max-line-length = 120 per-file-ignores = __init__.py: F401
-
-
pre-comit 패키지 설치 후
.pre-commit-config.yaml세팅 ->pre-commit install-
pip3 install pre-commit -
pylint와 달리 .
pre-commit-config.yaml파일을 직접 vscode에서 생성해준다.- stages가 다 [commit]이다.
- black -> python language version을 수정해준다.
-
requirements만 repo가 local로서 직접 작동할 내역을 entry에 입력해줘야한다.
- 아래는 기본적으로 linux에서 bash -c로 실행되는 코드다
repos: - repo: https://github.com/ambv/black rev: stable hooks: - id: black language_version: python3.10 stages: [commit] - repo: https://gitlab.com/pycqa/flake8 rev: 3.7.9 hooks: - id: flake8 stages: [commit] - repo: local hooks: - id: requirements name: requirements entry: bash -c 'venv/bin/pip3 freeze > requirements.txt; git add requirements.txt' language: system pass_filenames: false stages: [commit]- 추후 아래부분을 pytest관련 설정을 추가할 것이다.
- repo: local hooks: - id: pytest name: pytest language: system entry: pytest -v -s always_run: true pass_filenames: false stages: [commit] -
pre-commit install로.git/hooks/pre-commit생성해주기
-
-
test.py로 설치 확인하기
-
pylint익스텐션 설치 -
test.py 생성후 에러 확인
def start(): print("Ola Muno") -
doctstring없이 pylint에러 띄우기
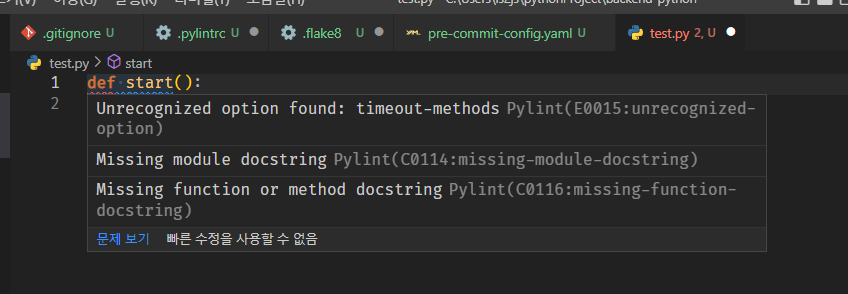
-
git status -> git add . -> git commit -m ‘‘를 통해 pre-commit 작동 확인해보기
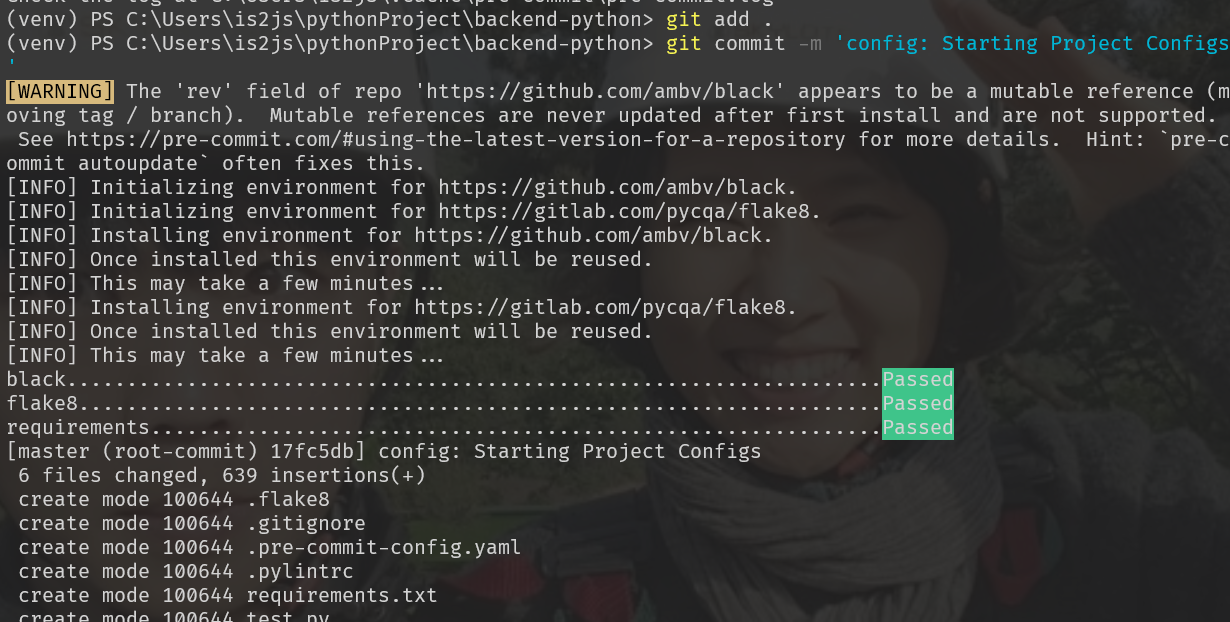
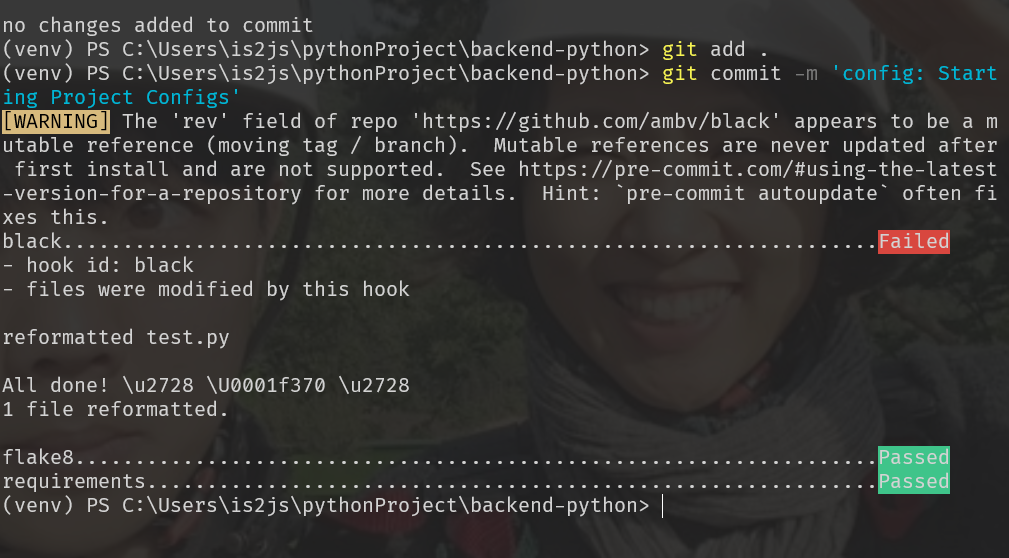
-
test.py 삭제하고
git log --oneline로 확인
-
-
vscode에서
.gitignore생성 후-
pycache 무시하기
-
venv폴더 무시하기
**/__pycache__ venv
-
pre-commit에서 window, linux 모두 작동하는 requirements hook만들기
-
각각의
entry명령어를 입력해주면, 1개의 운영체제에서 밖에 사용안된다.-
linux의 bash -c 로 작동시키기
- repo: local hooks: - id: requirements name: requirements entry: bash -c 'venv/bin/pip3 freeze > requirements.txt; git add requirements.txt' # entry: powershell -command '.\venv\Scripts\pip3 freeze > .\requirements.txt; git add requirements.txt' #entry: ./.pre-commit-scripts/requirements.py language: system pass_filenames: false stages: [commit] -
windows의 powershell -comand로 작동시키기
- repo: local hooks: - id: requirements name: requirements # entry: bash -c 'venv/bin/pip3 freeze > requirements.txt; git add requirements.txt' entry: powershell -command '.\venv\Scripts\pip3 freeze > .\requirements.txt; git add requirements.txt' # entry: ./.pre-commit-scripts/requirements.py language: system pass_filenames: false stages: [commit]
-
-
python script를 만들어, 운영체제마다(sys.platform) 커맨드 명령어 실행(subprocess.call)시키기
- 이 때, 명령어를 ` > requirements.txt`까지 다 입력하면, 윈도우에서 경로를 못찾는 문제가 발생한다
- with open() 을 사용해서
requirements.txt를w모드로 열어놓고 덮어쓴다
- with open() 을 사용해서
-
root에
.pre-commit-scripts폴더를 만들고requirements.py를 작성한다.
#!/usr/bin/env python from subprocess import call # nosec from sys import platform def main(): file_name = "./requirements.txt" if platform == "win32": with open(file_name, "w") as file_: call(["./venv/Scripts/pip3", "freeze"], stdout=file_) else: with open(file_name, "w") as file_: call(["./venv/bin/pip3", "freeze"], stdout=file_) call(f"git add {file_name}") # nosec if __name__ == "__main__": exit(main()) -
.pre-commit-config.yaml의 hook entry에서 해당 py 스크립트 파일을 걸어준다.- repo: local hooks: - id: requirements name: requirements # entry: bash -c 'venv/bin/pip3 freeze > requirements.txt; git add requirements.txt' # entry: powershell -command '.\venv\Scripts\pip3 freeze > .\requirements.txt; git add requirements.txt' entry: ./.pre-commit-scripts/requirements.py language: system pass_filenames: false stages: [commit]
- 이 때, 명령어를 ` > requirements.txt`까지 다 입력하면, 윈도우에서 경로를 못찾는 문제가 발생한다
-
다른 방법으로 pip-tools를 설치하고, 내부에서 call 시 pip-complie을 이용하는 방법도 있다.
-
pip3 install pip-tools설치 -
python310이면, pip-tools버전(6.8.0)을 잘 맞춰야한다.
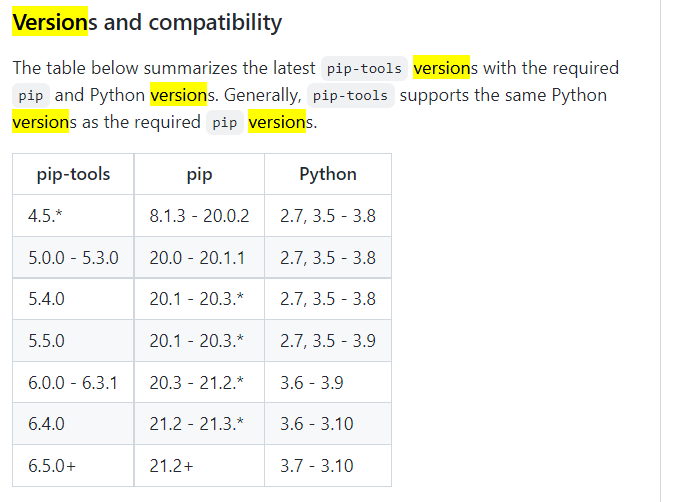
-
yaml
- repo: https://github.com/jazzband/pip-tools rev: 6.8.0 hooks: - id: pip-compile entry: ./.pre-commit-scripts/pip-compile.py -
pip-compile.py
#!/usr/bin/env python from subprocess import call # nosec from sys import platform def main(): if platform == "win32": cmd = (r"pip-compile.exe", "--output-file", "requirements.win.txt") else: cmd = ("pip-compile",) return call(cmd) # nosec if __name__ == "__main__": exit(main())
02 src, infra 폴더 세팅
-
src폴더 -> import용 모듈라이져를 위한init.py생성-
infra폴더 ->init.py생성-
config폴더 생성 >init.py생성
-
-
03 config설정
03-1 db_config + db_base 설정(sqlalchemy)
-
pip3 install sqlalchemy -
src > infra > config >
db_config.py-
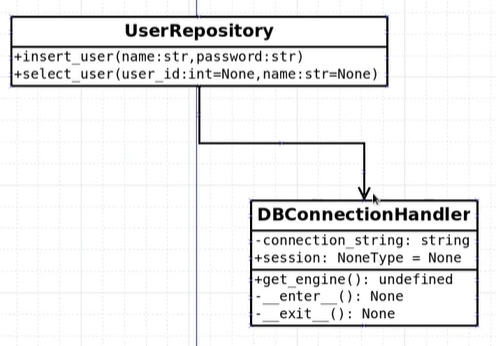
아래 그림과 같은 생성자(필드들)와 메서드를 만든다.
- engine용 url의 string 상수 필드와
- 객체별 sesion을 보유할 필드를 None으로초기화

class DBConnectionHandler: """Sqlalchemy database connection""" def __init__(self) -> None: self.__connection_string = 'sqlite://storage.db' self.session = None -
sqlalchemy의 create_engine메서드로, URL을 이용해서, db에 connection하여 engine을 생성하여 반환받는 메서드를
get_engine을 정의함from sqlalchemy import create_engine class DBConnectionHandler: """Sqlalchemy database connection""" def __init__(self) -> None: self.__connection_string = 'sqlite:///storage.db' self.session = None def get_engine(self): """Return Connection Engine :param - None :return - engine connection to Database """ engine = create_engine(self.__connection_string) return engine
-
-
src > infra > config >
db_base.py-
sqlalchemy의 entity class별 상속할 Base class를 반환해주는 파일이다.
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
-
03-2 config의 init.py에 같이 import될 모듈들 handler(db_config), Base(db_base) 올려놓기
- 내 폴더안에서 잇는 모듈들은
from .모듈명 import 사용할 class로 init에 import해놓을 수 있다.- init에 내하위모듈들을 import해놓으면 ->
외부에서 내 폴더 import시 다 같이 올라가는 효과다
- init에 내하위모듈들을 import해놓으면 ->
from .db_base import Base
from .db_config import DBConnectionHandler
04 entities 설정 및 생성
04-1 entity폴더 및 파일 생성
-
src > infra >
entities폴더 및init.py를 만든다. -
entity digram을 보고
소문자and복수 users.py / pets.py등 entity별로 py파일을 만든다.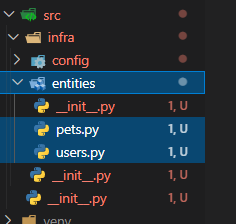
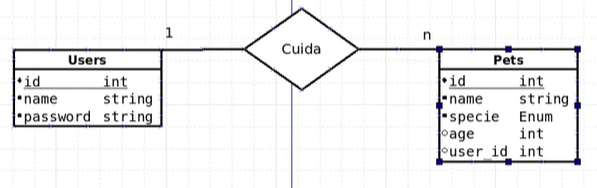
04-2 각 entity파일별, sqla재료들 + 선언후 Config가 올려놓은 것 중 1개인 Base class 사용하기
users.py
-
users.py에서 entity구성에 필요한 재료들과 config 속 Base class를 import한다
from sqlalchemy import Column, String, Integer from src.infra.config import Base -
users.py
-
entity class를 Base를 상속받아서 작성한다
-
fk관계가 필요하면
sqlalchemy.orm패키지에서relationshiop을 재료로 가져온다- relationship관계의 테이블은
"대문자복수 클래스명"으로 줘야한다. - 1:m관계에서는 1에서 relationship만 명시해주고,
M에서 ForeignKey재료를 사용해서 필드로 소유하게 한다
- relationship관계의 테이블은
- tablename은 소문자 복수로 적자
- repr는 unique필드로 1개로만 나타내주자
#.. from sqlalchemy.orm import relationship #.. class Users(Base): """Users Entity""" __tablename__ = "users" id = Column(Integer, primary_key=True) name = Column(String, nullable=False, unique=True) password = Column(String, nullable=False) id_pet = relationship("Pets") def __repr__(self): return f"User [name={self.name!r}]" -
pets.py
-
erd에 type이 적혀있으면
import enum후 enum.Enum을 상속한 class를 생성후 string 변수를 할당해주면 된다. -
M관계의 entity로서
ForeignKey재료가 추가 및 enum타입사용하려면Enum재료도 추가된다.- Column(Enum( 이넘상속정의한Class명), … )
- ForeignKey(“
소문자테이블명.id필드명“)으로 넣어준다.
import enum from sqlalchemy import Column, Integer, String, ForeignKey, Enum from src.infra.config import Base class AnimalTypes(enum.Enum): """defining Anymals Types""" dog = 'dog' cat = 'cat' fish = 'fish' turtle = 'turtle' class Pets(Base): """Pets Entity""" __tablename__ = 'pets' id = Column(Integer, primary_key=True) name = Column(String(20), nullable=False, unique=True) specie = Column(Enum(AnimalTypes), nullable=False) age = Column(Integer) user_id = Column(Integer, ForeignKey("users.id")) -
repr는 unique필드 외에, Enum필드(나를 묶어주는 상위개념) 및 fk까지 찍히도록 해준다.
def __repr__(self): return f"Pets: [name={self.name!r}, specie={self.specie!r}, user_id={self.user_id}]"
04-3 entities의 init.py에 같이 import될 모듈(entity)들 올려놓기
from .pets import Pets
from .users import Users
1:M entity 필드 정리(1:relationship(orm), M:ForeignKey)
- one table은
sqlalchemy.orm의relationship("대문자Class명")으로 연결을 유지하고 - many table은
sqlalchemy의ForeignKey("소문자테이블명.id필드명")으로 실제필드값을 유지한다.
05 python console에서 config + entities 2개 모듈로 DB연결 및 table생성
my) ipython설치하여 console에 자동완성
pip3 install ipython
from src.infra.config import *
-
vscode terminal에서
python로 python console에 진입한다. -
from src.infra.config import *를 통해 init에 올려둔 모듈들 모두 사용할 수 있게 한다.- import해서 사용하는 순간 각 모듈들 마다
__pycache__들이 생기고 .gitignore에서**/__pycache/로 처리했다
- import해서 사용하는 순간 각 모듈들 마다
-
DBConnectionHandler클래스의 객체()를 db_conn으로 받아서, get_engine()메서드를 호출하여
engine객체를 반환받자In [1]: from src.infra.config import * In [2]: db_conn = DBConnectionHandler() In [3]: engine = db_conn.get_engine() In [5]: engine Out[5]: Engine(sqlite:///storage.db) -
Base클래스의
.metadata.create_all( engine )으로 db를 생성하자- engine생성시 (DBConnectionHandler의 상수필드 -> create_engine시 인자) 명시된 db URL 주소에 db를 생성한다.
- sqlite는
-
://or:///:memory:-> 메모리 -
:///상대주소 -
:////절대주소
-
In [4]: Base.metadata.create_all(engine)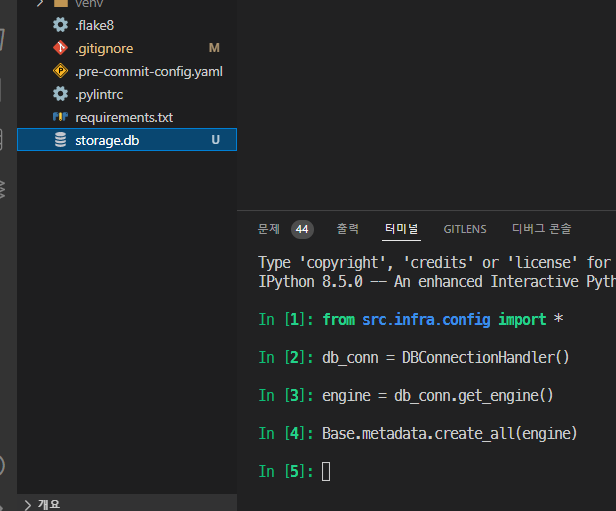
-
이대로 DBeaver에서 열어보면 entity들이 없다
- Base를 상속하고 있는 entity들을 import 안했기 때문에, metadata가 없다.
- 해당 잘못만들어진 db를 삭제해주자.
from src.infra.entities import * 까지하고 Base + engine으로 DB 생성
-
python console에서 config모듈들을(Base, ConnectionHandler)를 import하고
-
entity모듈들도 import 한다
In [2]: from src.infra.config import * In [3]: from src.infra.entities import * In [4]: db_conn = DBConnectionHandler() In [6]: engine = db_conn.get_engine() In [7]: Base.metadata.create_all(engine)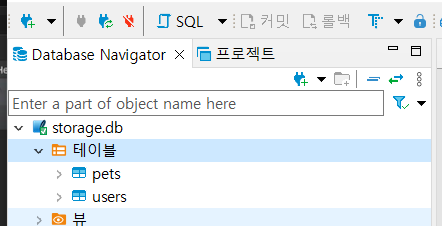
테스트용 sqlite.db파일은 ignore에 등록해주기 후 commit했었다면 cache제거해주기
**/__pycache__
venv
storage.db
git rm storage.db --cached
(git) 기존 commit에 처리 추가: add . 후 commit –amend –no-edit
git add .
git commit --amend --no-edit
1:M 관계확인
-
1에 해당하는 Users는
.orm패키지의 relationship만 가져 컬럼 및 외부키가 없다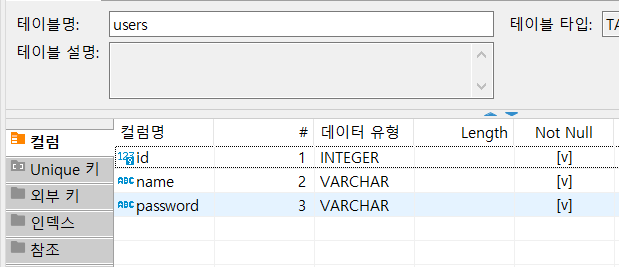
-
대신 참조당하므로
참조만 있다.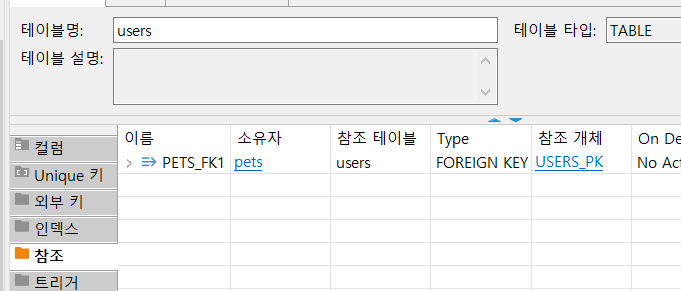
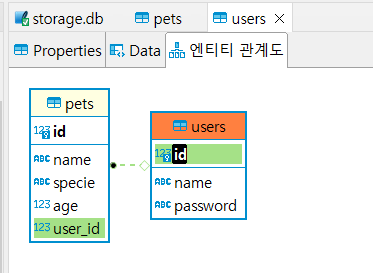
-
-
M에 해당하는 Pets는 user_id칼럼을 필드로 가지고 있으며, 외부키에 나타난다.
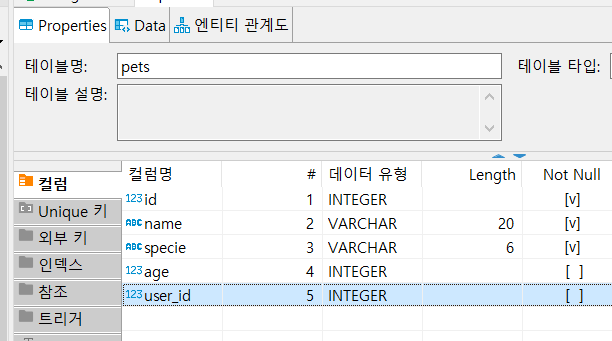
06 (DB연결 후) engine만(DB생성가능) 소유하던 DBConnectHandler를 CRUD를 위한 session소유 context manager화

-
참고 내 깃허브 CleanCode
-
DBConnector or DBConnectionHandler는 섹션을 실행동안만 유지되게 하기 위해서
enter/exit를 정의한 context manager를 만들어야한다.
-
DBConnector or DBConnectionHandler는 섹션을 실행동안만 유지되게 하기 위해서
참고) test.py로 context manage가 아니면 직접 close해야하는 번거로움
-
file.txt와 test.py 생성후 open()으로 파일을 열도록 하고 file변수.readline()으로 txt를 읽는 코드를 짠다.
- with as를 안쓰고, open만하면, rw동시에 안되서, 파일을 w하고 r mode로는 열기만
file = open('file.txt', 'r') print(file.readline()) -
terminal에서
python test.py -
만약, open된 file을 close안하고, 또다시 아래에서 with as로 열면.. 2번 열리게 된다(close 자동안됨)
file = open('file.txt', 'r') print(file.readline()) with open('file.txt', 'r') as file: print(file.readline())
DBConnectionHandler에 enter/exit 정의해주기
-
enter: 파라미터는 없으며 유지될 engine객체 생성 + .orm패키지의 sessionmaker객체 생성 -> 2개를 연결해서 Handler의 self.session필드에 유지하게 하고, return self를 반환해야한다.
-
exit: 필수파라미터 3개가 있으며, context(session_maker(bind=engine)객체)를 close해주면 된다.
#... from sqlalchemy.orm import sessionmaker class DBConnectionHandler: #... def get_engine(self): """Return Connection Engine :param - None :return - engine connection to Database """ engine = create_engine(self.__connection_string) return engine def __enter__(self): engine = self.get_engine() session_maker = sessionmaker() self.session = session_maker(bind=engine) return self def __exit__(self, exc_type, exc_val, exc_tb): self.session.close() # pylint: disable=no-memebr -
engine과 bind된 session객체 by session_maker를 가지고 있으면
CRUD에 직접적으로 사용된다.- handler 객체 -> session필드 -> .CRUD메서드()
with DBConnection() as db_connection -> db_connection.session.add()
- handler 객체 -> session필드 -> .CRUD메서드()
07 repo 설정 및 fake.py(Repo) 생성하기
-
src > infra> 아래에 repo폴더 및 init.py를 생성한다
-
entity별 repo class를 만들어야하는데,
fake.py를 일단 만든다.- config(db_base, db_config:handler)를 통째로 import할 일은, console에서 entities와 함께 DB생성 변경 할 때만이다.
-
Repo class는 상속없이 + CRUD메서드를 @classmehod로 정의한다.
class FakeRepo: """A simple Repository""" @classmethod def insert_user(cls, name: str, password: str): """something""" -
Repo class의 CRUD메서드를 정의하기 위해서는
DBConnectionHandler 및 해당 entity Class가 필요하다from src.infra.config import DBConnectionHandler from src.infra.entities import Users class FakeRepo: # ... -
insert(CREATE) 메서드의 경우를 예를 들어 작성한다.
- context manager가 된 handler를 with as 로 연다 -> 해당 구문이 끝나면 session이 자동 close
- session을 통한 CRUD를 try 작업+commit excetp rollback+raise finally session.close()형태로 작성한다
- finally는 작성안해도, handler를 통한 connection객체는 with구문이 끝나면 알아서 close될것 같은데..
# pylint: disable=E1101 from src.infra.config import DBConnectionHandler from src.infra.entities import Users class FakeRepo: """A simple Repository""" @classmethod def insert_user(cls, name: str, password: str): """some thing""" with DBConnectionHandler() as db_connection: try: new_user = Users(name=name, password=password) db_connection.session.add(new_user) db_connection.session.commit() except: db_connection.session.rollback() raise finally: db_connection.session.close() -
작성된 Repo class .py (fake.py)를 init에 올려두고 사용할 준비를 한다.
- Repo를 통한CRUD에 필요한 것은 이미 해당 repo파일에 handler + entity가import되어있다
-
python콘솔로 들어가,
from src.infra.repo import *을 통해, Repo를 올려놓고- 해당repo객체를 만들고 crud메서드를 작동시켜본다.
In [1]: from src.infra.repo import * In [2]: FakeRepo Out[2]: src.infra.repo.fake.FakeRepo In [3]: fake_repo = FakeRepo() In [4]: fake_repo.insert_user('cho', '1234')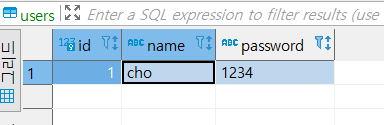
08 설정완료된 프로젝트를 push후 작업할 br을 딴 뒤, local원본레포삭제(.db챙기기) 후 특정브랜치만 clone하여 개별작업하기
01 설정이 끝난 project를 push하고 upstream으로 간주하며, 작업branch를 미리 따놓는다
-
github에 push해놓고
feat/xxx_repository형태로 언더라인으로 repository별 작업하도록 한다-
feat/user_repository따기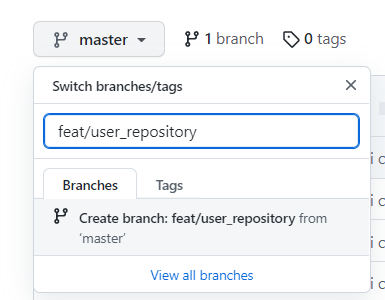
-
바로 이어서 user_repository -> pet_repository 바로 따기
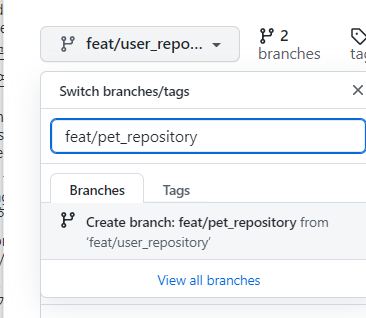
-
02 br생성된 repo를 pull해서 checkout해서 처리하지말고, PR을 사용하기 위해, 원본repo는 남겨두고 (남의repo면 fork후) 브랜치단위로 -b clone해서 작업후 PR로 끝내기
-
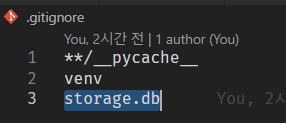
원본repo를 삭제하기 전에,
.gitignore에.db파일이 있나 확인한다.- 있으면 임시로 상위폴더에 옮겨준다.
-
작업했던
backend-python폴더를 upstrema으로 간주하고 삭제한다- venv터미널
- venv vscode다 꺼야한다
-
상위폴더에서 터미널을 켜고 -b 특정브랜치를 넣어서 clone한다
git clone -b feat/user_repository [복붙.git]
-
백업해놓은 .db파일을 복사만 해서 넣어준다(다른 br도 복사해서 쓸 것이기 때문에 자리 유지)
-
터미널에서 clone한 프로젝트로 들어가 ls와 git branch를 확인한다.
cd backend-python ls git branch
03 clone받고 백업db 넣어준 폴더에 가상환경 생성 -> requirements.txt 설치 -> pre-commit install까지
-
virtualenv로 가상환경 만들어주고, 진입후, txt에 따라 설치
python -m virtualenv -p python310 venv.\venv\Scripts\activatepip3 install -r requirements.txtpre-commit install -
code. > select interpreter
2 Repository와 PyTest
- 항상 프로젝트는 탐색기로 폴더 -> 터미널 -> code . > interpreter select선택후 내부터미널 재오픈 > 외부 터미널 venv직접 켜주기
-
터미널(venv) > vscode(venv)를 같이 유지한다.
-
01 User Repository 작성
-
fake.py 및 repo init 속 FakeRepo class올린 것 삭제
-
user_repository.py생성 후 UserRepository클래스 생성class UserRepository: """class to manage User Repository""" -
insert메서드 만들기
- create라서 자동생성용 id는 인자로 안받는다)
- docstring 작성
class UserRepository: """class to manage User Repository""" def insert_user(self, name: str, password: str): """insert data in user entity :param - name: person name - password: user password :return """
01 repository는 config의 handler와 entities의 entity를 기본적으로 import
-
CRUD메서드내에서 crud하기 위해서는 내부 session을 field로 유지하는
DBConnectionHandler을 with as db_connection으로 + 해당 db를 컨트롤 하기 위한Users entity가 필요하므로src>infra>config + entities에서 import 해서 쓴다from src.infra.config import DBConnectionHandler from src.infra.entities import Users -
insert 작성 및 pylint E1101(no-member) 무시하기
# pylint: disable=E1101 from src.infra.config import DBConnectionHandler from src.infra.entities import Users class UserRepository: """class to manage User Repository""" def insert_user(self, name: str, password: str): """insert data in user entity :param - name: person name - password: user password :return """ with DBConnectionHandler() as db_connection: try: new_uesr = Users(name=name, password=password) db_connection.session.add(new_uesr) db_connection.session.commit() except: db_connection.session.rollback() raise finally: db_connection.session.close() -
Repository는 CRUD메서드들을 @classmethod로 작성한다
- repository는
필드(멤버)가 없는 객체 1개 생성해서 돌려쓰기를 위해객체로 static 클래스처럼 쓰기 위해 cls로 정의한다
@classmethod def insert_user(cls, name: str, password: str): - repository는
02 pytest를 위해, user_repository_test.py를 작성한다.
-
테스트할 파일명
_test.py 형태로 바로 옆에 작성해준다.
03 pytest + faker를 설치하고 _test.py에서 사용한다.
pip3 install faker
pip3 install pytest
-
faker와 현재폴더에 원본py 속 테스트할 클래스를 import한다
- 같은 폴더의 py은
.을 붙여서 from으로 잡고 import class를 하면 됨.
from faker import Faker from .user_repository import UserRepository - 같은 폴더의 py은
-
Faker객체와, 테스트할클래스 객체를 생성해놓고,
test_로 메서드를 만들어서 작성한다from faker import Faker from .user_repository import UserRepository from src.infra.repo import user_repository faker = Faker() user_repository = UserRepository() def test_insert_user(): """Should Insert User""" name = faker.name() password =faker.word() user_repository.insert_user(name, password)
04 pytest는 터미널에서 돌린다
pytest
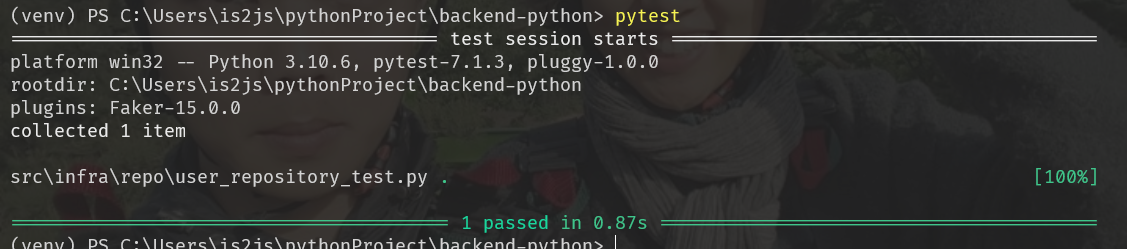
-
pytest할때마다 데이터가 추가될 것이다.
pytest의 결과 .pytest_cache폴더가 추가되니 gitignore에 폴더를 추가한다
**/__pycache__
venv
storage.db
.pytest_cache
02 _test.py에서 CREATE(insert) 메서드 테스트
01 원본메서드 내부에서 확인할 생성 데이터를 namedTuple(불변클래스)의 객체로 생성해서, 반환한다
class UserRepository:
"""class to manage User Repository"""
@classmethod
def insert_user(cls, name: str, password: str):
"""insert data in user entity
:param - name: person name
- password: user password
:return
"""
InsertData = namedtuple("Users", "id name password")
with DBConnectionHandler() as db_connection:
try:
new_uesr = Users(name=name, password=password)
db_connection.session.add(new_uesr)
db_connection.session.commit()
return InsertData(id=new_uesr.id, name=new_uesr.name, password=new_uesr.password)
except:
# ...
return None
02 test메서드에서는 return물을 받아 print한다
def test_insert_user():
"""Should Insert User"""
name = faker.name()
password =faker.word()
new_user = user_repository.insert_user(name, password)
print(new_user)
03 pytest에서는 -v + -s옵션을 가한다
-
옵션별 출력
-
pytest
-
pytest - v: 메서드별 성공여부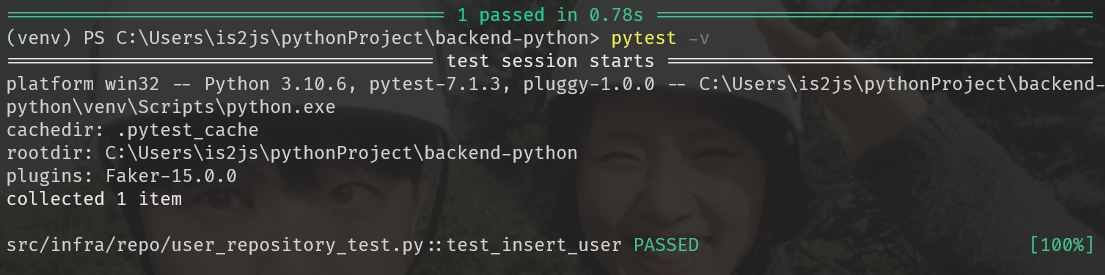
-
-
생성된 데이터를 변수에 받아 print까지 한 다음
pytest -v -s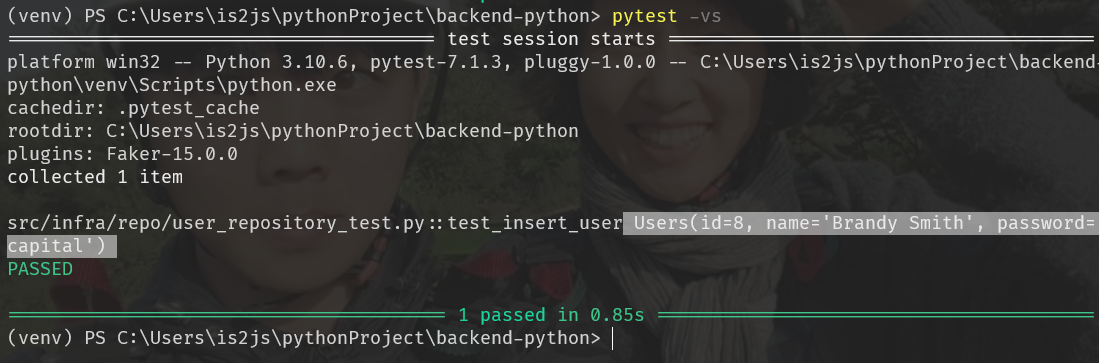
04 namedTuple의 typename을 entity와 동일하게 준 것의 장점을 살려, insert메서드의 return type 명시 및 docstring도 수정해준다.
- docstring에서는 tuple이라고 이름지어놓는다?!
class UserRepository:
"""class to manage User Repository"""
@classmethod
def insert_user(cls, name: str, password: str) -> Users:
"""insert data in user entity
:param - name: person name
- password: user password
:return - tuple with new user inserted
"""
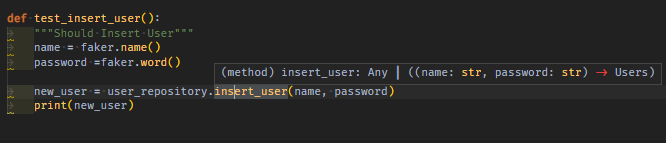
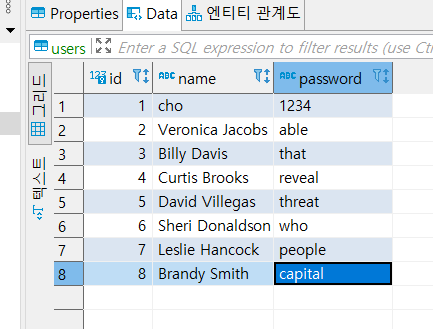
05 handler의 engine -> execute sql query를 이용해서, 생성된 데이터를 print없이 DB데이터로 필드끼리 assert로 비교한다
-
이미 repository는 crud메서드내에서, with handler-> engine -> bind 한 session필드를 가지고 있지만, **
test에서 추가로handler를 import해서실시간session이 아닌 engine만 가져와execute해서 db속 데이터를 직접 가져와서필드끼리 assert로 비교한다. **#... from src.infra.config import DBConnectionHandler from .user_repository import UserRepository #... db_connection_handler = DBConnectionHandler() def test_insert_user(): # ... engine = db_connection_handler.get_engine() new_user = user_repository.insert_user(name, password) # SQL Commands query_user = engine.execute(f"SELECT * FROM users WHERE id='{new_user.id}'").fetchone() assert new_user.id == query_user.id assert new_user.name == query_user.name assert new_user.password == query_user.passwordpytest -v -s -
execute후 fetchone()의 결과는 LegacyRow타입이며
출력은 튜플형태지만,.필드로 데이터를 가져올 수 있다.def test_insert_user(): #... new_user = user_repository.insert_user(name, password) # SQL Commands query_user = engine.execute(f"SELECT * FROM users WHERE id='{new_user.id}'").fetchone() print(new_user) print(type(query_user)) print(query_user)pytest -v -s Users(id=14, name='Andrew Moore', password='amount') <class 'sqlalchemy.engine.row.LegacyRow'> (14, 'Andrew Moore', 'amount')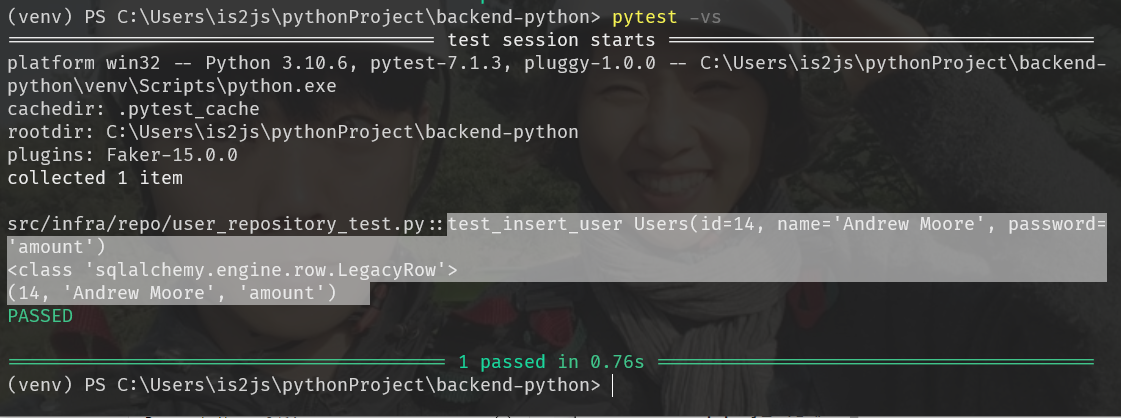
생성 -> sql로 로드 -> 비교 전 db속 데이터는 sql로 삭제까지 해준다.
def test_insert_user():
#...
new_user = user_repository.insert_user(name, password)
# SQL Commands
query_user = engine.execute(f"SELECT * FROM users WHERE id='{new_user.id}'").fetchone()
engine.execute(f"DELETE FROM users WHERE id='{new_user.id}'")
assert new_user.id == query_user.id
assert new_user.name == query_user.name
assert new_user.password == query_user.password
pytest -v -s
03 pre-commit 설정에 pytest 추가하기
-
.pre-commit-config.yaml맨 아래에 아래 스크립트를 추가한다.- repo: local hooks: - id: pytest name: pytest language: system entry: pytest -v -s always_run: true pass_filenames: false stages: [commit] -
일부러 test가 에러나도록 수정한다.
def test_insert_user(): #... # assert new_user.id == query_user.id assert new_user.id == 101 assert new_user.name == query_user.name assert new_user.password == query_user.password -
git commit을 통해 pytest가 실패를 잘 잡아내는지 확인한다.
git add . git commit -m "feat: Createing UserRepository with insert_user and test it"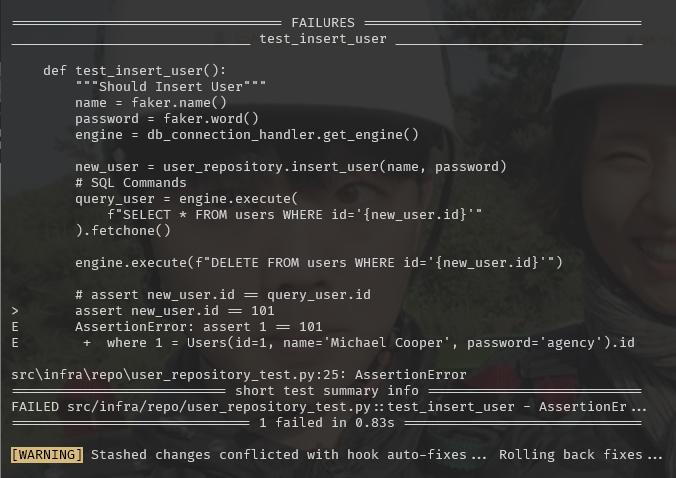
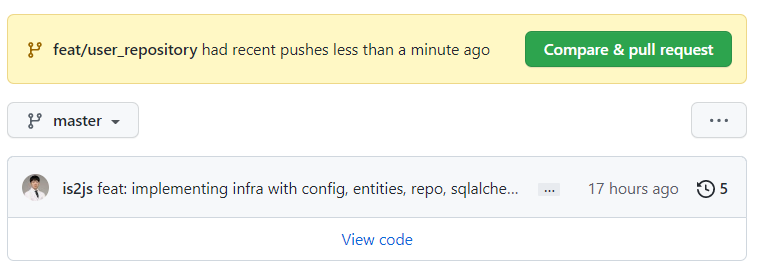
04 upstream(내꺼라면 remote)에 push해서 해당 작업br를 확인한다.
git push
-
master에 들어가도 PR가 뜨긴한다.
-
작업br로 들어가서 직접 파일을 볼땐 꺼지지만, 바꾼 즉시는 떠있다.
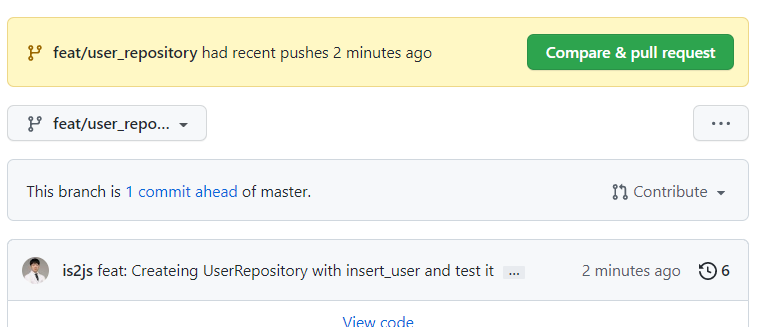
-
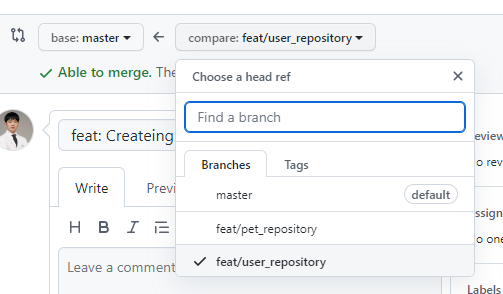
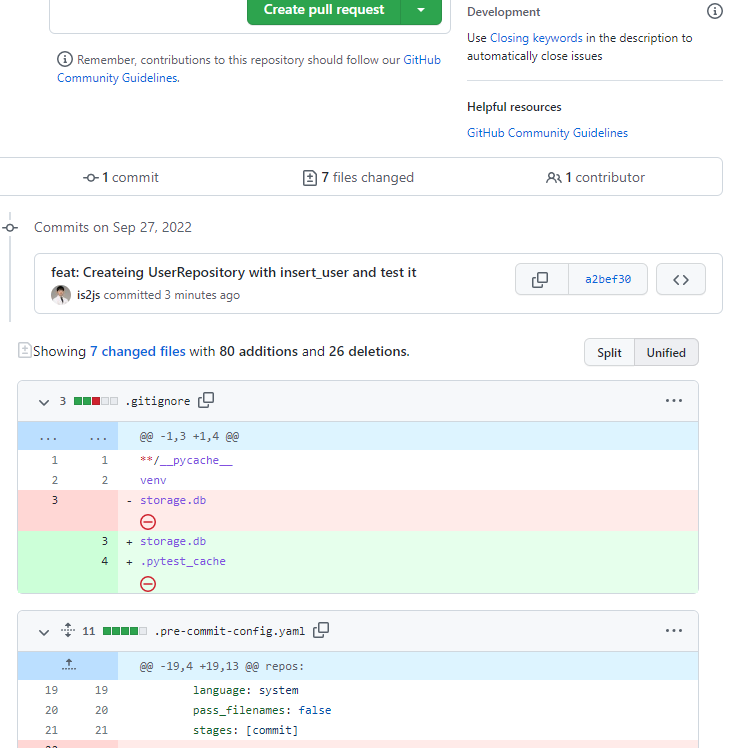
PR을 누르고, base <- compare쪽을 작업br로 확인하고 아래 코드변화를 확인한다
-
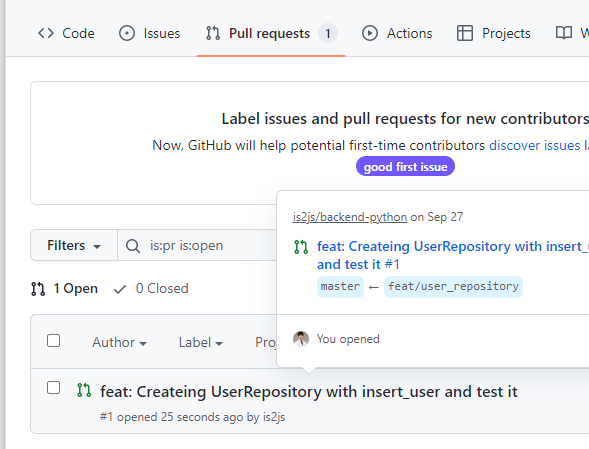
관리자는 PR탭으로 가서 확인한다.
-
관리자는 file changes 탭에서 변화를 본다
- 코멘트를 달고나서 finish review를 해준다.
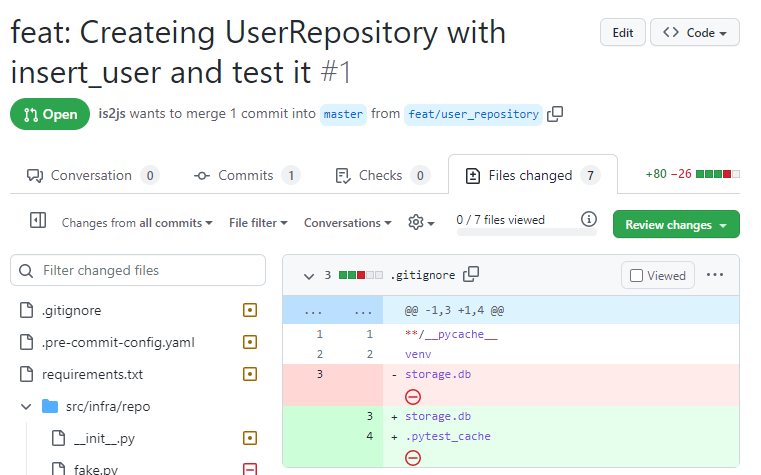
-
관리자는 파일마다 Viewed를 클릭하면, 확인한 파일들 쉽게 확인할 수 있다.
-
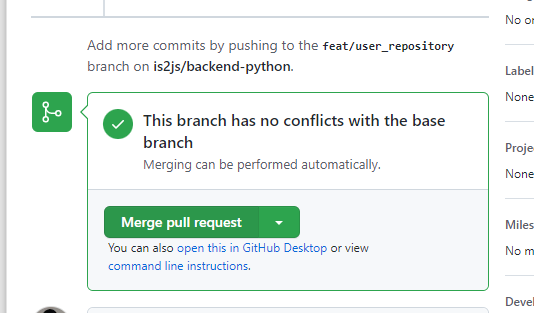
확인이 끝나면, merge PR해준다.
3 Domain layer 및 models, use_cases 개발
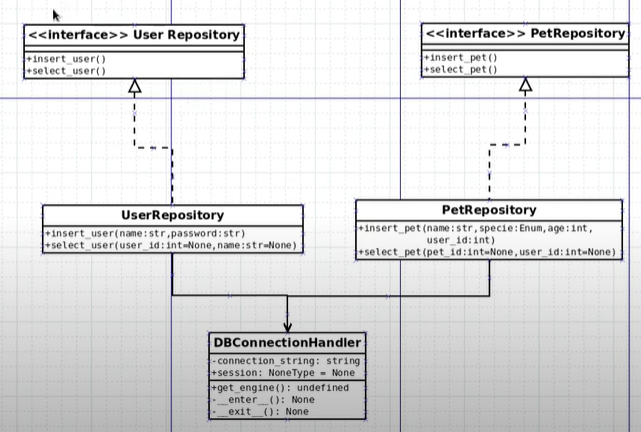
01 src> domain > models, use_cases 모듈 생성
-
src>
domain폴더 및 init.py를 생성 -
src> domain >
models폴더 및 init.py를 생성 -
src> domain >
use_cases폴더 및 init.py를 생성
02 repository에 있던 namedTuple(“Users”)를 domain > models>users.py로 옮기고, Users entity는 UsersModel로 취급하기
-
user_repository에 있는 namedTuple import + 사용코드를 src>model>
users.py만들어 로 옮긴다.from collections import namedtuple InsertData = namedtuple("Users", "id name password") -
불변클래스 변수명 == import된 class명으로서 Users로 수정한 뒤, init에 올린다.
from collections import namedtuple Users = namedtuple("Users", "id name password")from .users import Users -
user_repository에서는 DTO개념으로서 src>models>user.py에 정의된 namedTuple의 불변클래스
Users를 import해서 기존 InsertData관련 로직을 대체한다.- namedTuple -> User(model)
- User(entity) -> UsersModel
# from collections import namedtuple from src.domain.models import Users #... class UserRepository: # ... # InsertData = namedtuple("Users", "id name password") with DBConnectionHandler() as db_connection: try: # new_uesr = Users(name=name, password=password) new_uesr = UsersModel(name=name, password=password) db_connection.session.add(new_uesr) db_connection.session.commit() # return InsertData( return Users( id=new_uesr.id, name=new_uesr.name, password=new_uesr.password ) except: db_connection.session.rollback() raise finally: db_connection.session.close() return None -
교체한 로직이 잘 작동하는지 pytest -vs를 돌렵노다.
pytest -vs -
잘 작동하면 git status add commit한다.
git commit -m "feat: Implementing models in domain layer"
03 select_user(SELECT)메서드를 객체가 부르는 static메서드인 @classmethod로 정의
01 select의 결과는 List[model(불변class)]
-
id와 동등한 unique필드 name이 있으므로
id와 name모두 = None형태로 선택형으로 받는다. -
return 타입을 typing을 import해 정의하며 결국엔
List[model]형태로 반환받는다.@classmethod def select_user(cls, user_id: int = None, name: str = None) -> List[Users]: """ Select data in user entity by id and/or name :param - user_id: Id of the registry - name: User name :return - List with Users selected """
02 select는 insert와 달리 파라미터의 경우의수 -> try가 제일 바깥에서 내부if elif별 진입후에 with handler
-
select는 id외에 대체칼럼인 unqiue칼럼을 쓸 수 있는 순간부터 옵셔널하게 받을 수 있어야한다.
- 파라미터를 =None으로 모두 주고, 모두 None이면 예외처리 해야할 듯
-
select결과는 1개일수도 여러개일 수도 있다. 결과는 List로 맞춰났으니, 가변변수에 1개일시 []씌워서 반환해준다.
- 가변변수 query_data = None에다가
-
.one()1개시 -> [data] 할당 - 2개이상시 -> 그대로 할당
-
@classmethod def select_user(cls, user_id: int = None, name: str = None) -> List[Users]: """ Select data in user entity by id and/or name :param - user_id: Id of the registry - name: User name :return - List with Users selected """ try: query_data = None if user_id and not name: with DBConnectionHandler() as db_connection: data = db_connection.session.query(UsersModel).filter_by(id=user_id).one() query_data = [data] elif not user_id and name: with DBConnectionHandler() as db_connection: data = db_connection.session.query(UsersModel).filter_by(name=name).one() query_data = [data] elif user_id and name: with DBConnectionHandler() as db_connection: data = db_connection.session.query(UsersModel).filter_by(id=user_id, name=name).one() query_data = [data] return query_data except: db_connection.session.rollback() raise finally: db_connection.session.close() - 가변변수 query_data = None에다가
04 select메서드에 대한 test메서드 작성
insert(create메서드 -> db조회후 db삭제 )와 달리, select는 db삽입생성후 -> select메서드 -> db삭제
-
조회의 경우, entity에 데이터를 넣어서 entity객체로 조회한다.
- Users entity -> UsersModel로 가져온다.
from faker import Faker from src.infra.config import DBConnectionHandler from .user_repository import UserRepository from src.infra.entities import Users as UsersModel -
faker로 필드데이터를 만들고, select전 DB생성부터 한다
def test_select_user(): """Should select a user in Users table and compare it """ user_id = faker.random_number(digits=5) name = faker.name() password = faker.word() data = UsersModel(id=user_id, name=name, password=password) engine = db_connection_handler.get_engine() engine.execute( f" INSERT INTO users (id, name, password) VALUES ({user_id}, {name}, {password});" )
데이터를 assert 필드비교를 떠나 entity객체별 비교하기 위해서, entity별 eq메서드 정의하기(파라미터를 other로 주고 비교)
class Users(Base):
"""Users Entity"""
__tablename__ = "users"
id = Column(Integer, primary_key=True)
name = Column(String, nullable=False, unique=True)
password = Column(String, nullable=False)
id_pet = relationship("Pets")
#...
def __eq__(self, other):
return self.id == other.id and self.name == other.name and self.password == other.password
\없이 enter를 편하게 줄바꿈하기 위해서 괄호를 걸어주고 친다.
class Pets(Base):
"""Pets Entity"""
__tablename__ = "pets"
id = Column(Integer, primary_key=True)
name = Column(String(20), nullable=False, unique=True)
specie = Column(Enum(AnimalTypes), nullable=False)
age = Column(Integer)
user_id = Column(Integer, ForeignKey("users.id"))
def __repr__(self):
return f"Pets: [name={self.name!r}, specie={self.specie!r}, user_id={self.user_id}]"
def __eq__(self, other):
return (
self.id == other.id
and self.name == other.name
and self.specie == other.specie
and self.age == other.age
and self.user_id == other.user_id
)
uniquekey칼럼을 가진 경우의수별 조회결과(1개라도List[entityModel])를 assert in으로 여러개 다 비교하기
- 가짜데이터로 -> 모델 data객체를 만든다.
- 가짜데이터를 -> db에 삽입생성한다.
- select메서드로 db조회하여 -> List[모델]을 만든다.
- 1번에서 만든 모델data vs 3번에서 db조회한 List[모델]을 객체 in [객체List]로 비교한다.
- f-string sql 중 VALUES다음에는 각 {value}에는 바깥쪽에 ‘‘작은따옴표를 씌워서 넣어줘야한다.
def test_select_user():
"""Should select a user in Users table and compare it """
user_id = faker.random_number(digits=5)
name = faker.name()
password = faker.word()
data = UsersModel(id=user_id, name=name, password=password)
engine = db_connection_handler.get_engine()
engine.execute(
f" INSERT INTO users (id, name, password) VALUES ('{user_id}', '{name}', '{password}');"
)
query_user1 = user_repository.select_user(user_id=user_id)
query_user2 = user_repository.select_user(name=name)
query_user3 = user_repository.select_user(user_id=user_id, name=name)
assert data in query_user1
assert data in query_user2
assert data in query_user3
engine.execute(f"DELETE FROM users WHERE id='{user_id}';")
pytest -v -s
commit(포맷팅등) 후 hook에 의해 취소되었다면, 수정된 것을 다시 한번 add commit
git status
git add .
git commit -m 'feat: implementing select_user in UserRepository'

05 PR후 동일br에서 다른 작업이 끝났을 때
commit후 push 전, github를 보니 이전 PR이 merge되어있는데도 남아있다면, close PR해준다.
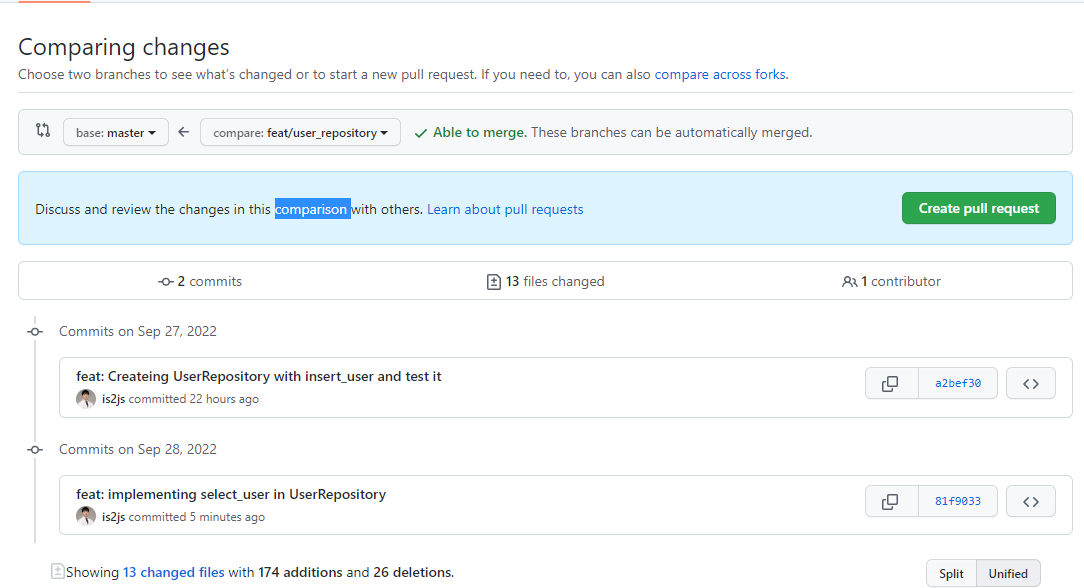
push전 PR>New pull request를 눌러 들어가서, Comparing changes로 이전PR이 어디까지 작업됬는지 확인한다
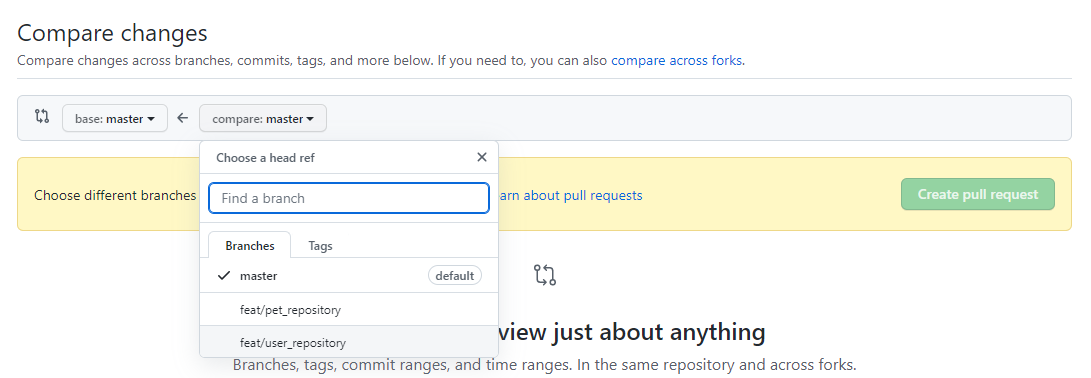
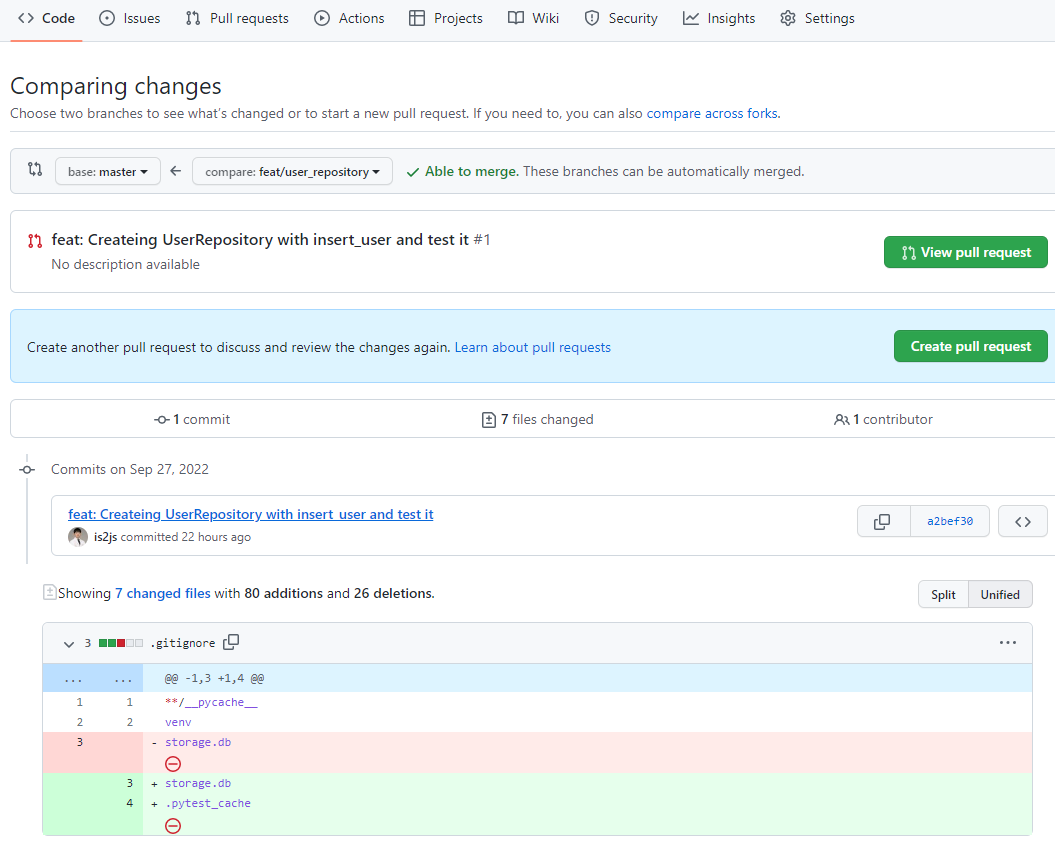
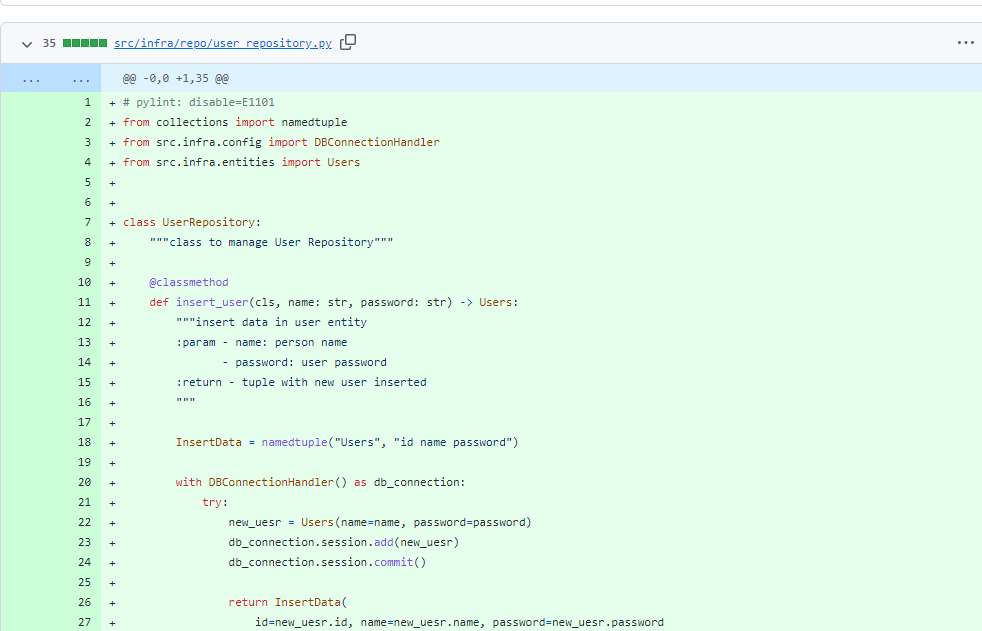
local의 [clone 작업br]에서 commit을 push해서한 뒤 -> 직접 New PR > Compare branch 바꿔서 -> Create PR해서 새로운 PR을 만든다.
- vscode에서 git push(로그인 된 터미널개념)
-
새 PR 누르기
-
Comparing Changes에서 작업br로 바꾸기
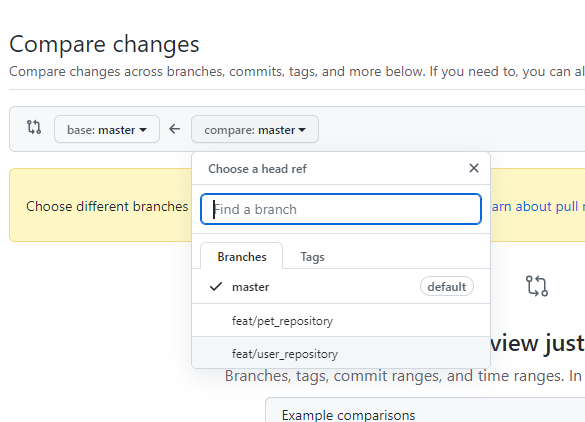
-
직접 create PR 누르기
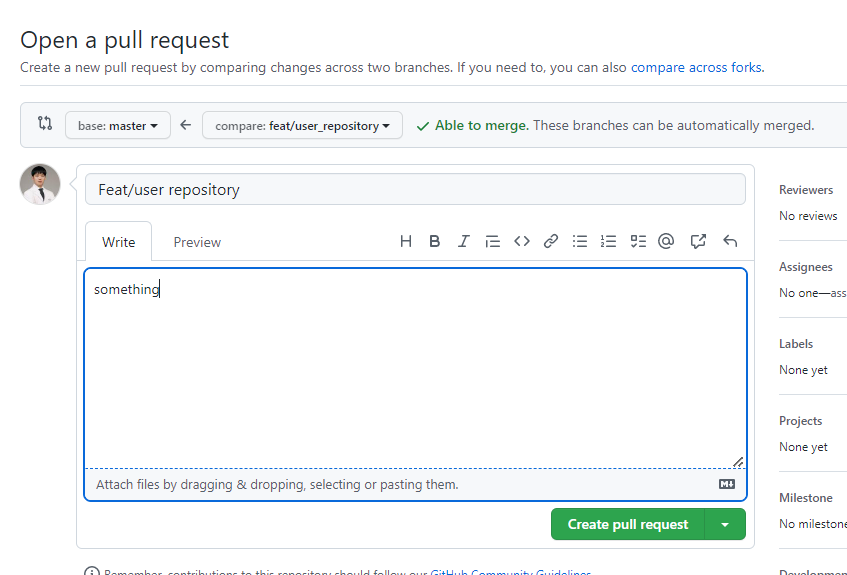
-
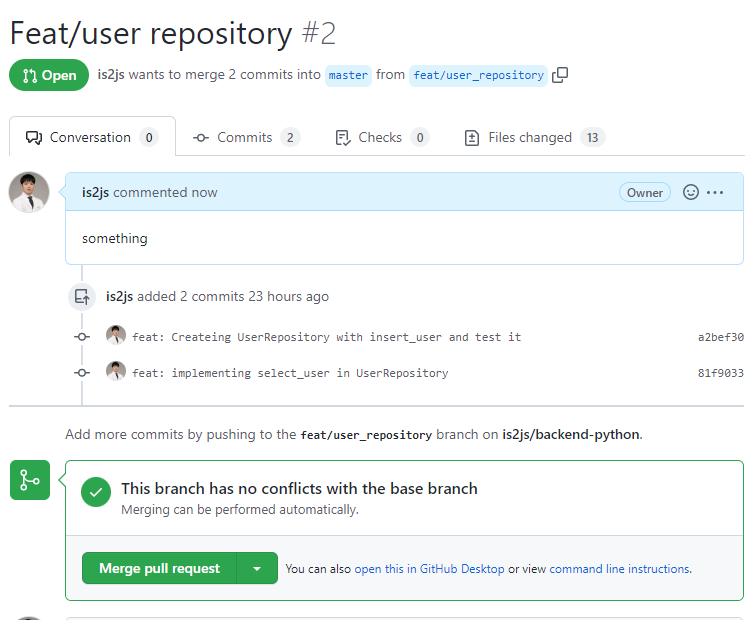
직접 merge 누르기
-
master에서 merge된 것 확인하기
06 github에서 만든 타 작업br을 가져오되, 최신master를 rebase하고 사용하기
br1과 br2를 동시에 만들고 동시에 clone -b했었더라면
- feat/user_repository -> clone -b
-
feat/pet_repository -> clone - b 안됨(폴더명 동일해서)
- 다른 폴더에 clone -b 했어야함
-
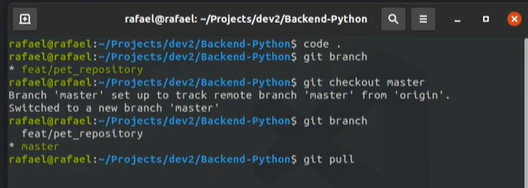
feat/pet_repository br을 clone해 둔 곳으로 가서, 터미널을 열고
- git branch
-
git checkout master
- 작업b만clone-b한 상황에서
master로 checktout하면 master가 생긴다.
- 작업b만clone-b한 상황에서
- git branch
-
git pull
- feat/user_repository에서 작업한 것들이 다 maste로 받아진다.
다음작업br만 local clone -b하고, ignore되었던 -> 상위폴더에 백업해놓았던 sqlite .db파일을 복붙해준다.
-
나는 폴더명을 pet_repository로 만들고 진입한 뒤, 터미널을 열어서
현재폴더 .에 clone - b해온다git clone -b feat/pet_repository https://github.com/is2js/backend-python.git .
-
상위폴더에 백업해둔 db파일을 복붙한다.
-
혹시 몰라서 master로 checkout하고 git pull해준다.
PS C:\Users\is2js\pythonProject\pet_repository> git branch * feat/pet_repository PS C:\Users\is2js\pythonProject\pet_repository> git checkout master Switched to a new branch 'master' Branch 'master' set up to track remote branch 'master' from 'origin'. PS C:\Users\is2js\pythonProject\pet_repository> git branch feat/pet_repository * master PS C:\Users\is2js\pythonProject\pet_repository> git pull
최신업뎃된 master를 두고, 다시 작업br로 넘어와, git rebase master를 통해 master로부터 최신작업을 가져온다.
-
일단 최신업뎃 master의 git log를 보자.
-
rebase결과 1줄로 이어지므로, 미리 보자.

-
-
최신업뎃master를 둔 상태에서, 작업br로 checkout한다.
git checkout feat/pet_repository -
작업br에서 -> master에게 rebase를 요청한다
git rebase master First, rewinding head to replay your work on top of it... Fast-forwarded feat/pet_repository to master.
07 clone한 폴더 new setting(최초)
01 gitignore중에 db파일 있으면 옮겨주기
02 github에서 따온 빈 새br에 대해, venv를 만들고 활성화하고 vscode를 연다
python -m virtualenv -p python310 venv
.\venv\Scripts\activate
03 최초 requirements.txt 직접 설치
pip3 install -r requirements.txt
04 최초 pre-commit install 직접 설치
pre-commit install
08 pet repository 개발
insert_pet(CREATE) 메서드
pets entity에 대한 src>domain>models에서 pets.py(dto Pets) 만들어서 올리기
-
src>infra>entities에 있는 pet.py의 Pets class entity의 필드를 확인하고, namedTuple로 DTO class를 먼저 만든다.
-
pets.py
from collections import namedtuple Pets = namedtuple("Pets", "id name specie age user_id") -
modes의 init에 올리기
from .users import Users from .pets import Pets
-
pets entity에 대한 src>infra>repo에서 pet_repository.py 에서 CREATE메서드(insert_)부터 만들기
-
classmethod로 id를 제외한 필드를 인자로, 반환타입은 DTO Pets로(생성된 것을 반환하여 확인하게 한다)
- 반환타입에 의해, 어쩔수 없이
model(dto)를 import 해야하므로, 먼저 정의했다.
from src.domain.models import Pets class PetRepository: """Class to manage Pet Repository""" @classmethod def insert_pet(cls, name: str, specie: str, age: int, user_id: int) -> Pets:-
import 추천이 뜨는데 소문자로 import된다?
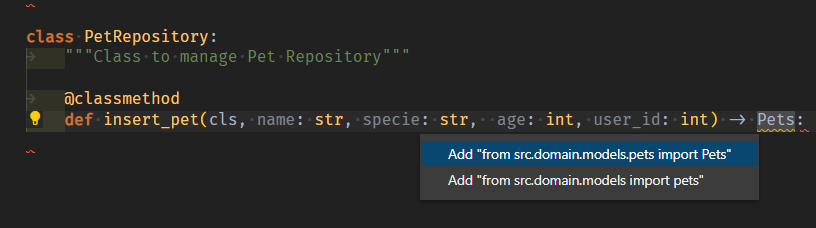
- 반환타입에 의해, 어쩔수 없이
-
crud를 하려면, return타입DTO뿐만 아니라, 실제
entity + session이 필요하다as PetsModel+handler를 import하자.from src.domain.models import Pets from src.infra.config import DBConnectionHandler from src.infra.entities import Pets as PetsModel -
with handler -> conn -> session객체로 entity객체를 add해서 commit후, commit후 자동으로 변수에 등록된 id를 사용해서 DTO를 채워 반환한다.
# pylint: disable=E1101 from src.domain.models import Pets from src.infra.config import DBConnectionHandler from src.infra.entities import Pets as PetsModel class PetRepository: """Class to manage Pet Repository""" @classmethod def insert_pet(cls, name: str, specie: str, age: int, user_id: int) -> Pets: """Insert data in pets entity Args: name (str): name of the pet specie (str): Enum with species accpets age (int): pet age user_id (int): id of the owner (FK) Returns: Pets: tuple with new pet inserted """ with DBConnectionHandler() as db_connection: try: new_pet = PetsModel(name=name, specie=specie, age=age, user_id=user_id) db_connection.session.add(new_pet) db_connection.session.commit() return Pets( id=new_pet.id, name=new_pet.name, specie=new_pet.specie, age=new_pet.age, user_id=new_pet.user_id ) except: db_connection.session.rollback() raise finally: db_connection.session.close() return None
pet repo 메서드1개 만들때마다 _test.py에 test작성하기
-
pet_repositort_test.py를 만들고test_해당메서드를 정의한다.def test_insert_pet(): """Should insert pet in Pet table and return it""" -
테스트 데이터를 만들기 위해, faker를 사용한다
- faker객체는 전역변수로 1개로서 import 밑에 만들어준다.
- faker로 못만드는
enum은 직접 입력해준다.
from faker import Faker faker = Faker() def test_insert_pet(): """Should insert pet in Pet table and return it""" name = faker.name() specie = "fish" age = faker.random_number(digits=1) user_id = faker.random_number() -
repository를 import해서 거기 메서드를 사용해 테스트할 것이다.
- 전역 객체변수를 만든다.
from faker import Faker from .pet_repository import PetRepository faker = Faker() pet_repository = PetRepository() -
sqlalchemy CRUD를 증명하기 위해 hanlder를 import해서 engine.execute를 활용할 것이다.
- 전역 hadler -> db_connection_handler객체를 만든다.
from faker import Faker from .pet_repository import PetRepository from src.infra.config import DBConnectionHandler faker = Faker() pet_repository = PetRepository() db_connection_handler = DBConnectionHandler()
create(insert)의 결과비교는 메서드 결과(namedTuple) vs engine쿼리결과(LecayRow, tuple) 결과은 어쩔수 없이 필드끼리 한다
-
repo메서드 결과물(dto, namedTuple) vs engine쿼리결과물(tuple)을 비교한다
-
참고: commit이 이루어지는 순간 entity model로 만든 객체에는, id를 포함한 정보가 부여된다.
>>> from src.infra.entities import Pets >>> from src.infra.config import DBConnectionHandler >>> with DBConnectionHandler() as db_conn: ... new_pet = Pets(name='adf',specie='fish',age=33,user_id=1) ... print(type(new_pet), new_pet) ... db_conn.session.add(new_pet) ... db_conn.session.commit() ... print(type(new_pet), new_pet) ... db_conn.session.rollback() ... <class 'src.infra.entities.pets.Pets'> Pets: [name='adf', specie='fish', user_id=1] <class 'src.infra.entities.pets.Pets'> Pets: [name='adf', specie=<AnimalTypes.fish: 'fish'>, user_id=1]- repo -> entitymodel -> session.addcommit -> entitymodel완성 -> dto(namedTuple)
-
참고: engine으로 fetchone()해온 결과물은 tuple같은 것이다.
>>> query_user = engine.execute('select * from users where id = 1;').fetchone() >>> print(type(query_user), query_user) <class 'sqlalchemy.engine.row.LegacyRow'> (1, 'cho', '1234')
-
test_insert_pet
from faker import Faker
from src.infra.entities import Pets as PetsModel
from src.infra.config import DBConnectionHandler
from src.infra.entities.pets import AnimalTypes
from .pet_repository import PetRepository
faker = Faker()
pet_repository = PetRepository()
db_connection_handler = DBConnectionHandler()
def test_insert_pet():
"""Should insert pet in Pet table and return it"""
name = faker.name()
specie = "fish"
age = faker.random_number(digits=1)
user_id = faker.random_number()
# SQL Commands
new_pet = pet_repository.insert_pet(name, specie, age, user_id)
engine = db_connection_handler.get_engine()
query_pet = engine.execute(
f'SELECT * FROM pets WHERE id ="{new_pet.id}";'
).fetchone()
engine.execute(f"DELETE FROM users WHERE id = '{new_pet.id}';")
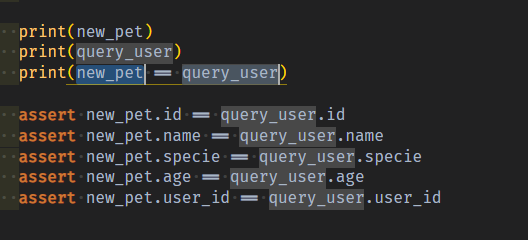
print(new_pet)
print(query_pet)
print(new_pet == query_pet)
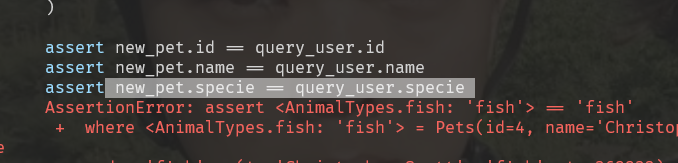
assert new_pet.id == query_pet.id
assert new_pet.name == query_pet.name
assert new_pet.specie == query_pet.specie
assert new_pet.age == query_pet.age
assert new_pet.user_id == query_pet.user_id
pytest를 경로를 직접 찾아가 1개의 test.py만 걸 수도 있다.
- 상위폴더부터 직접 py까지 가주면 된다.
pytest .\src\infra\repo\pet_repository_test.py -vs
[DTO] repo의 create(insert)메서드의 결과물에서 enum field를 DTO에 담을 때는 .value로 담는다.
class PetRepository:
#...
@classmethod
def insert_pet(cls, name: str, specie: str, age: int, user_id: int) -> Pets:
#...
with DBConnectionHandler() as db_connection:
#...
return Pets(
id=new_pet.id,
name=new_pet.name,
# specie=new_pet.specie,
specie=new_pet.specie.value,
age=new_pet.age,
user_id=new_pet.user_id
)
my) DTO(namedTuple)과 LecacyRow 모두 tuple이라 값비교시 통과 바로 되더라…

method test완료후 commit(작업을 이어할 것이면, push없이 commit후 바로 진행)
git add .
git commit -m "feat: implementing insert_pet in PetRepository"
select_pet 메서드
-
select부터는 1개든 여러개는 return type이
List[DTO]형태다.- typing 패키지에서 List 를 import한다.
- select시 파라미터가 선택형이므로 = None으로 선언하며, 자신의 id or unique key칼럼 or
하위entity(M)으로서 fk를 반드시 포함시킨다.- pet_id : 자신의 id
- user_id: Manyentity가 가지고 있는 상위entity의 id (FK)
from typing import List #... @classmethod def select_pet(cls, pet_id: int = None, user_id: int = None) -> List[Pets]: -
select는 unique or fk 등 선택형이 가능하기 때문에
try -> 가변변수 -> if elif return List[DTO] -> 각 경우마다 with의 전략으로 간다.
조심! fk가 select메서드에 들어간 경우, .one()이 아니라 .all()을 쓰며, return [data]가 아니라 그냥 return data
@classmethod
def select_pet(cls, pet_id: int = None, user_id: int = None) -> List[Pets]:
"""
Select dat in PetEntity by id and/or user_id
:param - pet_id: Id of the pet registry
- user_id: Id of the owner
:return - List with Pets selected
"""
try:
query_data = None
if pet_id and not user_id:
with DBConnectionHandler() as db_connection:
data = (
db_connection.session.query(PetsModel)
.filter_by(id=pet_id)
.one()
)
query_data = [data]
elif not pet_id and user_id:
with DBConnectionHandler() as db_connection:
data = (
db_connection.session.query(PetsModel)
.filter_by(user_id=user_id)
.all()
)
query_data = data
elif pet_id and user_id:
with DBConnectionHandler() as db_connection:
data = (
db_connection.session.query(PetsModel)
.filter_by(id=pet_id, user_id=user_id)
.one()
)
query_data = [data]
return query_data
except:
db_connection.session.rollback()
raise
finally:
db_connection.session.close()
return None
select_test
insert(CREATE)와 다르게, id도 faker로 생성해서 조회한다.
def test_select_pet():
"""Should select a pet in Pets table and compare it"""
pet_id = faker.random_number(digits=4)
name = faker.name()
specie = "fish"
age = faker.random_number(digits=1)
user_id = faker.random_number(digits=4)
insert(CREATE) test와 다르게, select(READ) test는 해당 entity Model 및 enum도 직접필요하다.
insert는 dto(tuple) vs query결과(tuple)
create는 faker -> entitymodel vs faker->insert into -> select메서드 List[DTO]
-
entity 및 entityModel객체 생성에 필요한 enum도 같이 import한다.
from faker import Faker #... from src.infra.entities import Pets as PetsModel from src.infra.entities.pets import AnimalTypes -
faker로 만든 데이터로 entityModel을 만든다.
def test_select_pet(): """Should select a pet in Pets table and compare it""" pet_id = faker.random_number(digits=4) name = faker.name() specie = "fish" age = faker.random_number(digits=1) user_id = faker.random_number(digits=4) specie_mock = AnimalTypes("fish") data = PetsModel(id=pet_id, name=name, specie=specie_mock, age=age, user_id=user_id) -
engine으로 select할 데이터를 db에 삽입생성한다.
# SQL Commands engine = db_connection_handler.get_engine() engine.execute( f""" INSERT INFO pets (id, name, spiece, age, user_id) VALUES ('{pet_id}', '{name}','{specie}','{age}','{user_id}'); """ ) -
select를 파라미터 경우의 수(3가지)로 날려서 entityModel객체 in select쿼리결과List[Dto]으로 비교한다.
query_pets1 = pet_repository.select_pet(pet_id=pet_id) query_pets2 = pet_repository.select_pet(user_id=user_id) query_pets3 = pet_repository.select_pet(pet_id=pet_id, user_id=user_id) print(data, type(data)) print(query_pets1, type(query_pets1)) assert data in query_pets1 assert data in query_pets2 assert data in query_pets3 -
insert와 달리, 비교끝내고 삽입한 데이터를 삭제한다.
assert data in query_pets1 assert data in query_pets2 assert data in query_pets3 engine.execute(f"DELETE FROM users WHERE id='{pet_id}';") -
테스트한다.
pytest .\src\infra\repo\pet_repository_test.py -vs -
entity model과 List[DTO]는 타입이 다르지만,
entity model 속 __eq__으로 인해, 필드끼리 비교하게 되니 가능한 것이다.-
entity class 속 __eq__def __eq__(self, other): return ( self.id == other.id and self.name == other.name and self.specie == other.specie and self.age == other.age and self.user_id == other.user_id )
[name='Marcus Smith', specie=<AnimalTypes.fish: 'fish'>, user_id=5935] <class 'src.infra.entities.pets.Pets'> [Pets: [name='Marcus Smith', specie=<AnimalTypes.fish: 'fish'>, user_id=5935]] <class 'list'> -
pre-commit에 의해 한번은 걸리고, 수정되니 매번 add하지말고 그냥 -am으로 commit해주고 log확인하자
git status
git commit -am "feat: implementing insert_pet and select_pet in PetRepository"
git log --oneline
[Test] 정리: insert메서드와 select메서드 테스트
01 insert메서드(test_insert_pet)
- faker로 insert메서드의 필드재료들을
db배정 id필드제외하고 만든다 -
insert메서드로 new_pet(DTO)로 반환받는다.
- (내부)재료->entity모델객체->db에 add(INSERT, CREATE)후 entity객체에 id배급 -> entity모델객체의 필드들로 DTO를 만들어서 반환
- assert는 DTO필드(namedTuple) == query필드(tupe, LegacyRow)의 필드비교이며 DTO필드에 대응되는 query결과 tuple이 요구된다
-
insert메서드결과 DTO에서 id만 받아와서 db engine으로 select -> query_pet으로 받아주고 바로 engine으로 delete까지 먹여준다.
- query_data에 sqlalchemy insert된 데이터의 id로 데이터만 조회해오면 됨
- dto필드들과 query필드들을 비교한다.
-
요약
- id제외 faker + insert메서드 -> new_dto
- new_dto속 배정id + engine db select -> query_data -> engine db delete
- assert new_dto.필드 == query_data필드 비교
02 select 메서드(test_select_pet)
- faker로 select메서드들의 재료들을
이미db에있으니 id까지만든다.- enum type이라면, enumClass(enum value)로 _mock 필드를 만든다.
- id포함 재료들 +
entity모델객체를 직접 만든다.- entity모델객체는 비교를 위한 것이며, sqlalchemy로 CRUD를 직접 하진 않는다??!
- 똑같은 id포함재료들 + engine -> db insert로 삽입생성해서 db에 select할 데이터를 세팅해놓는다.
-
select메서드로
id 및 fk_id경우의수만큼query_data =List[Entity모델객체]를 반환받는다.- (내부) session query(Entity모델).filter등 one() or all() -> List[Entity모델객체]
- assert는 (session조작없이 그냥만든) entity모델객체 in List[entity모델객체]이다
- select를 위해 id포함재료들로 만든 db데이터를 engine으로 delete해준다.
-
요약
- id포함 faker -> entity모델 객체
- id포함 재료들 + engine db insert -> db데이터만들어놓기
- id, fk재료들 + select메서드 -> List[entity모델객체들]
- engine db delete
4 insert, select 메서드들의 Interface 제작
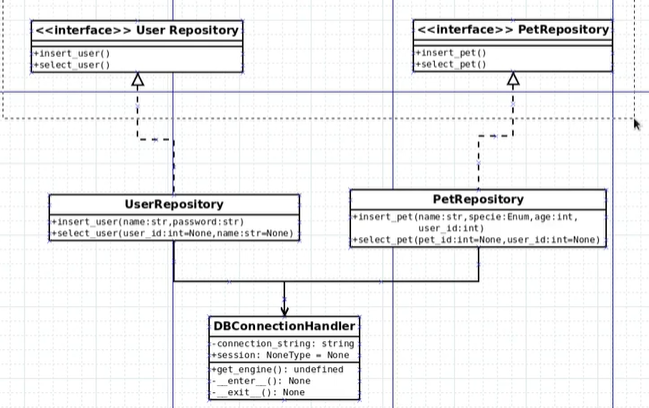
01 src> data폴더 및 init 생성 > interfaces 폴더 및 init생성
-
db관련된 entities(Base상속class entity모델)는
infra layer에 **, **실제로 사용되는 객체와 관련된 models(DTO)는domain layer에 , interface는data layer에 속한다.
02 각 repository.py별 repository_interface.py 만들기
-
pet_repository_interface.py생성class PetRepositoryInterface(): -
각 Interface class들은 추상클래스가 되어야하므로 아래 것들을 import한다.
- abc 패키지에서 추상클래스ABC와 추상메서드모듈
- select메서드의 응답타입 List
- insert메서드의 응답타입(id배정된entity->DTO)인 models의 DTO
from abc import ABC, abstractclassmethod from typing import List from src.domain.models import Pets -
interface클래스는 ABC를 상속해서 @abstractmethod로 정의한다.
from abc import ABC, abstractclassmethod from typing import List from src.domain.models import Pets class PetRepositoryInterface(ABC): """ Interface to Pet repository""" -
추상메서드의 signature는
repo의 method signature를 복사해서 구성한다- repo메서드는 class메서드이므로
cls를 추상메서드용self로 변경해서 쓴다 - 구현안되고 호출되는 경우는 예외가 발생할 수 있게
raise Exception("")을 작성해주면 된다.
@abstractclassmethod defclass PetRepositoryInterface(ABC): """ Interface to Pet repository""" @abstractclassmethod def insert_pet(self, name: str, specie: str, age: int, user_id: int) -> Pets: """ abstractmethod """ raise Exception("Method not implemented") @abstractclassmethod def select_pet(self, pet_id: int = None, user_id: int = None) -> List[Pets]: """ abstractmethod """ raise Exception("Method not implemented") - repo메서드는 class메서드이므로
user_repository_interface.py도 Pet꺼를 복사해서 바꿔주기
from abc import ABC, abstractclassmethod
from typing import List
from src.domain.models import Users
class UserRepositoryInterface(ABC):
""" Interface to Pet repository"""
@abstractclassmethod
def insert_user(cls, name: str, password: str) -> Users:
""" abstractmethod """
raise Exception("Method not implemented")
@abstractclassmethod
def select_user(cls, user_id: int = None, name: str = None) -> List[Users]:
""" abstractmethod """
raise Exception("Method not implemented")
03 init.py에 생성한 Interface 올려주기
from .pet_repository_interface import PetRepositoryInterface
from .user_repository_interface import UserRepositoryInterface
04 각 infra>repo속> repository.py들의 class들은 data>interfaces 속>repository_interface.py들을 상속해서 구현해야한다.
-
interface import 후 class가 상속
#... from src.data.interfaces import UserRepositoryInterface #... class UserRepository(UserRepositoryInterface): """class to manage User Repository"""#... from src.data.interfaces import PetRepositoryInterface #... class PetRepository(PetRepositoryInterface): """Class to manage Pet Repository""" -
pytest 돌려서 메서드들 작동 문제없는지 확인
pytest -vs
05 작업br 완료(구현 pytest) -> 커밋 push -> github에서 new PR까지
-
status 확인후 add . 후 -am으로 커밋->실패->-am커밋
- add를 먼저 날려야 add된상태로 pytest하는 것 같다?!
git status git add git commit -am "feat: implementing data interfaces" git commit -am "feat: implementing data interfaces" -
git push는 현재 로그인된 vscode에서 하고 있음.
-
github에 들어가보면,
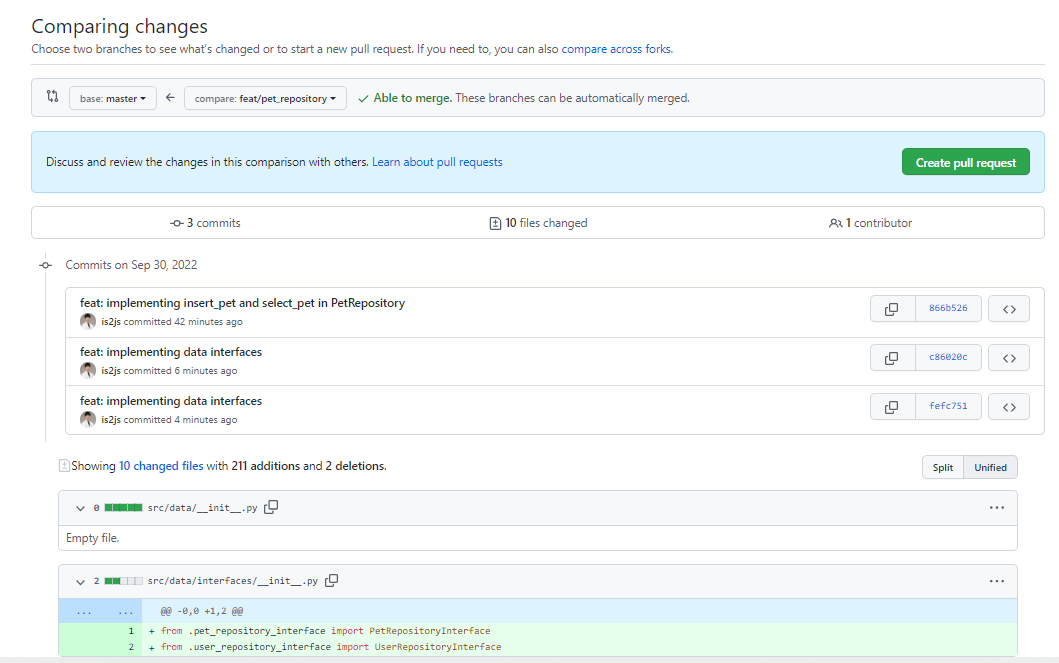
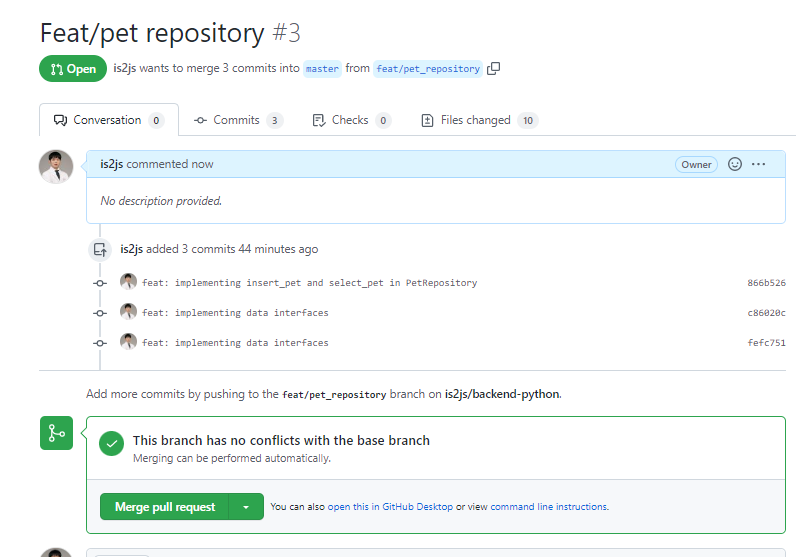
Compare & pull request가 떠있더라도PR탭 > new PR로 들어가는 버릇을 들여보자.- Comparing change까지 들어가서 코드를 확인하고
Able to merge및세부코드를 확인하고 직접 Create PR까지 가자

- Comparing change까지 들어가서 코드를 확인하고
-
merge후 master에 반영되었는지까지 확인하자
참고
gitignore
-
git에 commit되었던 것을 ignore하고 싶을 때
git rm [파일명] --cached
- console 등에서 init import부터 생기는 pycache폴더
- venv
- 연습용 sqlite .db파일
- pytest시 생기는 .pytest_cache 폴더
**/__pycache__
venv
storage.db
.pytest_cache
sqlalchemy패키지
- 일반 패키지: create_engine / 칼럼재료들
- .orm 패키지: relatioship(1관계)/sessionmaker(handler의 enter에서 engine을 묶어서 가지고 있을 놈)
clone후 작업 세팅
- gitignore중에 db파일 있으면 옮겨주기
- 없으면 config import해서 Base + enigne bind한 다음, create_all()해줘야할듯??
- github에서 따온 빈 새br에 대해, venv를 만들고 활성화하고 vscode를 연다
python -m virtualenv -p python310 venv
.\venv\Scripts\activate
- 최초 requirements.txt 직접 설치
pip3 install -r requirements.txt
- 최초 pre-commit install 직접 설치
pre-commit install
clone -b 작업+테스트완료후 ~ merge까지 정리
-
status 확인후 add . 후 -am으로 커밋->실패->-am커밋
- add를 먼저 날려야 add된상태로 pytest하는 것 같다?!
git status git add git commit -am "feat: implementing data interfaces" git commit -am "feat: implementing data interfaces" -
git push는 현재 로그인된 vscode에서 하고 있음.
-
github에 들어가보면,
Compare & pull request가 떠있더라도PR탭 > new PR로 들어가는 버릇을 들여보자.
- Comparing change까지 들어가서 코드를 확인하고
Able to merge및세부코드를 확인하고 직접 Create PR까지 가자
- merge후 master에 반영되었는지까지 확인하자
vscode 설정
"files.exclude": {
"**/__pycache__": true,
"**/.pytest_cache": true
}
test정리
-
test_insert_X
- id제외 faker + insert메서드 -> new_dto
- new_dto속 배정id + engine db select -> query_data -> engine db delete
- assert new_dto.필드 == query_data필드 비교
-
test_select_X
- id포함 faker -> entity모델 객체
- id포함 재료들 + engine db insert -> db데이터만들어놓기
- id, fk재료들 + select메서드 -> List[entity모델객체들]
- engine db delete