의연방14) 과제 정리
수업간 과제 정리



📜 제목으로 보기✏마지막 댓글로
- 과제 테이블 그리는 템플릿
- table template
- 과제1
- 1번 incidence와 prevalence
- 2번 사망률
- 3번 Relative risk, Odds ratio
- 과제2
- 과제3
- 과제4(기말)
table template
사망률-direct age adjustment (과제1-2)
// Direct-age adjusted mortality rate table template
// 안적혀있으면 인구수보고 대충 10만명당으로 k 계산
|나이별그룹||집단A|||집단B||표준집단|집단A|집단B|
|---|---|---|---|---|---|---|---|---|---|
||인구수|사망자수|**k명당 사망률**|인구수|사망자수|**k명당 사망률**|인구수|**기대사망자수**|**기대사망자수**|
|나이그룹a|l|d1|d1/l X k|l'|d1'|d1'/l' X k|l+l'|k당사망률 X 표준인구 / k|k당사망률 X 표준인구 / k|
|나이그룹b|m|d2|d2/m X k|m'|d2'|d2'/m' X k|m+m'|위와 동일|위와 동일|
|나이그룹c|n|d3|d3/n X k|m'|d3'|d3'/n' X k|n+n'|위와 동일|위와 동일|
|합계|l+m+n|||l'+m'+n'|||(l+m+n)+(l'+m'+n')|계산 후 총합|계산 후 총합|
- 각 집단별 / 나이그룹별 10만명당 사망률 계산 -> 표 삽입
- 두 집단의 인구수를 더해서 표준집단 인구수 계산 -> 표 삽입
- 각 집단별 / 나이그룹별 기대 사망자수 계산 -> 표 삽입
- 각 집단별 기대사망자수 합 각 계산 -> 표 삽입
- 각 집단별 총 사망자수 / 표준인구 총합 X 10만 = 각 집단별 10만명당 age -adjusted mortality rate 계산
RR, OR (과제1-3번)
//노출여부그룹별 n수 + 질병환자수를 각각 줘서, risk를 a/n으로 계산할 경우
|노출여부| 전체n | 질병 O | (Absolute) risk | Odds|
|---|---|---|---|---|
|흡연|n|a| a/n |r1/1-r1|
|비흡연|m|b|b/n|r0/1-r0|
//노출여부그룹별 risk를 바로주거나, risk소수점을 없애려고 x k 해놓은 경우
|노출여부| k명당 발생자수(risk에 k곱) | (Absolute) risk | Odds|
|---|---|---|---|
|흡연|rr1| rr1 / k |r1 / 1-r1|
|비흡연|rr0|rr0 / k|r2 / 1-r2|
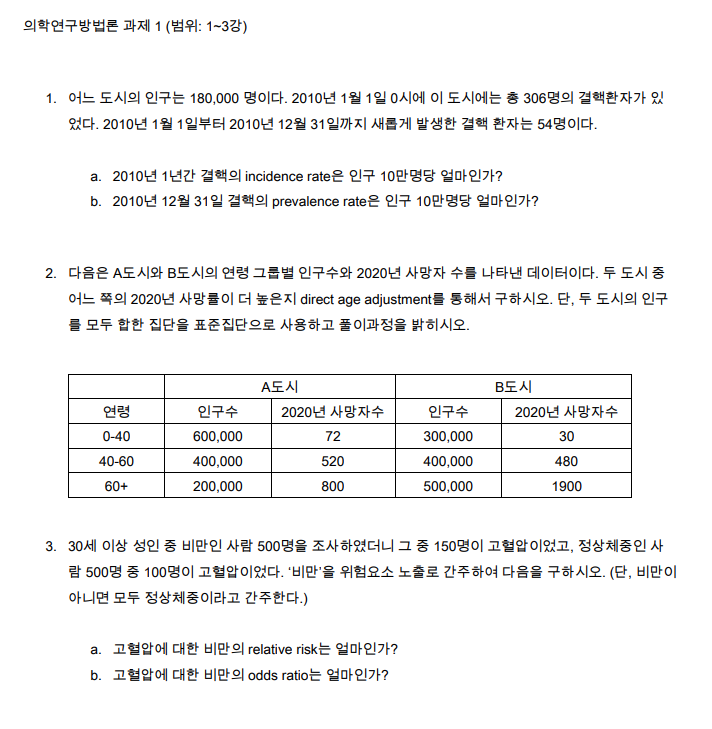
1번 incidence와 prevalence

a. 10만명당 1년간 결핵의 incidence rate = 30
-
1년간 새롭게 결핵이 발병한 환자 수 / 1년간 결핵에 노출된 인구 수 X 100,000
= 54 / 180,000 X 100,000
b. 10만명당 2010년 12월 31일 결핵의 prevalence rate = 200
- 12월 31일 결핵을 가진 모든 환자수 / 집단 내 모든 인구 X 100,00 = 306+54 / 180,000 X 100,000
2번 사망률
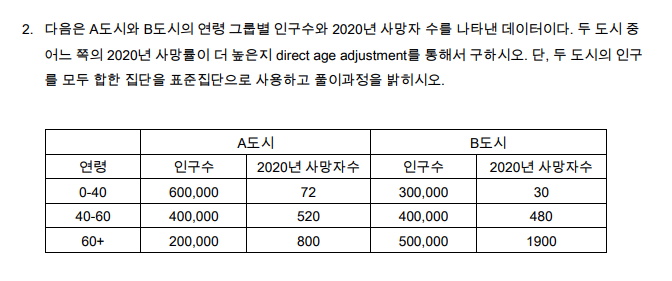
table-사망률-direct age adjustment (과제1-2)
// Direct-age adjusted mortality rate table template
// 안적혀있으면 인구수보고 대충 10만명당으로 k 계산
|나이별그룹||집단A|||집단B||표준집단|집단A|집단B|
|---|---|---|---|---|---|---|---|---|---|
||인구수|사망자수|**k명당 사망률**|인구수|사망자수|**k명당 사망률**|인구수|**기대사망자수**|**기대사망자수**|
|나이그룹a|l|d1|d1/l X k|l'|d1'|d1'/l' X k|l+l'|k당사망률 X 표준인구 / k|k당사망률 X 표준인구 / k|
|나이그룹b|m|d2|d2/m X k|m'|d2'|d2'/m' X k|m+m'|위와 동일|위와 동일|
|나이그룹c|n|d3|d3/n X k|m'|d3'|d3'/n' X k|n+n'|위와 동일|위와 동일|
|합계|l+m+n|||l'+m'+n'|||(l+m+n)+(l'+m'+n')|계산 후 총합|계산 후 총합|
| 나이별그룹 | A도시 | B도시 | 표준집단 | A도시 | B도시 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 인구수 | 사망자수 | 10만명당 사망률 | 인구수 | 사망자수 | 10만명당 사망률 | 인구수 | 기대사망자수 | 기대사망자수 | |
| 0~40 | 600,000 | 72 | 12 | 300,000 | 30 | 10 | 900,000 | 108 | 90 |
| 40~60 | 400,000 | 520 | 130 | 400,000 | 480 | 120 | 800,000 | 1040 | 960 |
| 60+ | 200,000 | 800 | 400 | 500,000 | 1900 | 380 | 700,000 | 2,800 | 2,660 |
| 합계 | 1,200,000 | 1,200,000 | 2,400,000 | 3,948 | 3,710 |
- 각 집단별 / 나이그룹별 10만명당 사망률 계산 -> 표 삽입
- 두 집단의 인구수를 더해서 표준집단 인구수 계산 -> 표 삽입
- 각 집단별 / 나이그룹별 기대 사망자수 계산 -> 표 삽입
- 각 집단별 기대사망자수 합 각 계산 -> 표 삽입
- 각 집단별 총 사망자수 / 표준인구 총합 X 10만 = 각 집단별 10만명당 age -adjusted mortality rate 계산
- A도시의 10만명당 age -adjusted mortality rate : 3,948 / 2,400,000 X 100,000 = 164.5
- B도시의 10만명당 age -adjusted mortality rate : 3,710 / 2,400,000 X 100,000 = 154.58
- 2020년 사망률은
A도시가 더 높다
3번 Relative risk, Odds ratio

table2-RR, OR (과제1-3번)
//노출여부그룹별 n수 + 질병환자수를 각각 줘서, risk를 a/n으로 계산할 경우
|노출여부| 전체n | 질병 O | (Absolute) risk | Odds|
|---|---|---|---|---|
|흡연|n|a| a/n |r1/1-r1|
|비흡연|m|b|b/n|r0/1-r0|
//노출여부그룹별 risk를 바로주거나, risk소수점을 없애려고 x k 해놓은 경우
|노출여부| k명당 발생자수(risk에 k곱) | (Absolute) risk | Odds|
|---|---|---|---|
|흡연|rr1| rr1 / k |r1 / 1-r1|
|비흡연|rr0|rr0 / k|r2 / 1-r2|
| 위험요소 | 인구수 | 질병 O | (Absolute) risk | Odds |
|---|---|---|---|---|
| 비만 | 500 | 150 | 0.30 | 0.429 |
| 정상 | 500 | 100 | 0.20 | 0.250 |
a. RR = 1.5
b. odds ratio = 1.716


1번 위험요소 2개 incidence rate without interaction
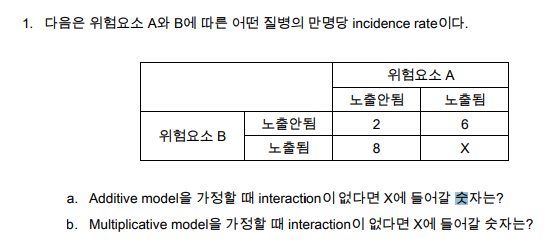
- interaction이 없다면, model별 각 요소가 어떤질병에 끼친 효과의 변화량을 합 or 곱해주면 된다.
- a. 2 + 4(A에 의해 증가된 B가 어떤질병에 끼치는 효과) + 6(B에 의해 증가된 효과) = 12
- b. 2 x 3 x 4 = 24
2번 Case-control study에서 unmatched data OR
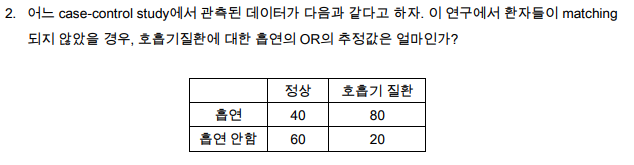
- OR = ad/bc = 80x60 / 40x20 = 6
3번 Case-control study에서 matched data OR
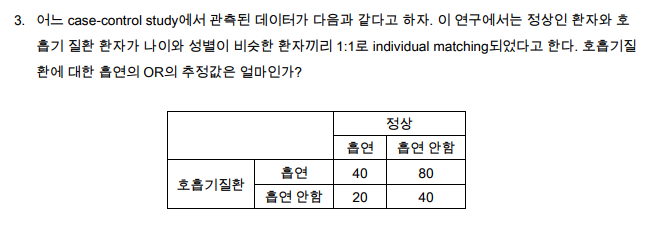
- macchted case-control study에서 OR은 n12/n21과 같으므로
- 80 / 20 = 4
4번 cohort study 논문 분석

a. 연구질문 : 예상한 산전요인 혹은 산후요인들이 산후우울증에 영향을 주는가?
b. 산후우울증
c. measure: OR
- 산전요인
- 산전우울감: OR=5.19, 95% CI : 1.41-19.0
- 임신의도 점수가 1점 증가: OR=1.57, 95% CI : 1.09-2.27
- 사회적 지지 점수 1점 증가: OR=1.27, 95% CI : 1.06-1.53
- 산후요인
- 모성우울감: OR=4.22, 95% CI : 1.60-11.12
d. 결론
- OR이 가장 높게 측정된
산전우울감으로 미루어, 산전부터 산후우울증에 노출될 위험이 큰 집단을 선별하고 중재하여 산후우울증을 예방할 수 있기를 제언함.
5번 RCT study 논문 분석

a. 심리적 지지가 고위험 임산부의 예상되는 주요 고위험출산 결과들에 영향을 주는가
b. 저체중아출산
c. 심리적지지 없이 일반적인 케어만 받는 임산부
d. 결과변수가 이분형 변수들인데 비해, count와 proportion을 적절하게 제시하지 않았다. 효과 크기에 대한 검정결과를 카이제곱이나 회귀분석을 통해 적절한 검정결과를 보여주지 못했다.

01번
두가지 수술방법의 합병증 비율을 비교하는 임상시험을 하려고 한다. 수술방법 A는 15%의 환자에게 서 합병증이 발생할 것이고 수술방법 B는 5%의 환자에게서 합병증이 발생할 것으로 예상되는 상황 이라고 하자. 두 수술방법의 합병증 비율에 차이가 있다는 것을 유의수준 0.05에서 80% 파워(검정력) 으로 보이려면, 총 몇 명의 환자를 모집해야 하는가? (단, lost-to-follow up이나 결측은 고려하지 않는 다. 계산을 위한 R 코드와 출력결과를 답안에 포함한다.)
- n = ?
- α(유의수준) = 0.05
- β = 0.2
- p0 = 0.15
- p1 = 0.05
power.prop.test(
p1 = 0.15, # 수술방법A
p2 = 0.05, # 수술방법B
sig.level = 0.05,
power = 0.8, # b=0.2
alternative = "two.sided"
)
Two-sample comparison of proportions power calculation
n = 140.0951
p1 = 0.15
p2 = 0.05
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
- 총 280명이 필요하다
02번
두가지 수술방법의 합병증 비율을 비교하는 임상시험을 하려고 한다. 수술방법 A는 15%의 환자에게 서 합병증이 발생할 것이고 수술방법 B는 5%의 환자에게서 합병증이 발생할 것으로 예상되는 상황 이라고 하자. 두 수술방법의 합병증 비율에 차이가 있다는 것을 유의수준 0.05에서 80% 파워(검정력) 으로 보이려면, 총 몇 명의 환자를 모집해야 하는가? (단, lost-to-follow up이나 결측은 고려하지 않는 다. 계산을 위한 R 코드와 출력결과를 답안에 포함한다.)
- n = 200 +200
- α(유의수준) = 0.05
- β = ?
- p0 = 0.15
- p1 = 0.05
# sample size가 고정(n=400)된 경우, power 계산
power.prop.test(
p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
n = 400,
alternative = "two.sided"
)
Two-sample comparison of proportions power calculation
n = 400
p1 = 0.45
p2 = 0.3
sig.level = 0.05
power = 0.9928852
alternative = two.sided
NOTE: n is number in *each* group
- power 99.3%를 가지고 유의수준 0.05에서 두 군간의 차이를 detect할 수 있다.
03번
-
Propensity score matching을 사용한 연구결과를 보고하는 논문 1편을 조사하여 다음에 답하시오.
- a. 연구질문(research question)이 무엇인가?
- 한국인/연길거주 조선족의 체형은 체질별 체형에 여향을 주는가
- 논문
- a. 연구질문(research question)이 무엇인가?
- b. 연구에 사용한 결과변수의 정의가 무엇인가?
- 체질별(태음인, 소음인, 태양인, 소양인) 체형
- c. 연구에서 비교한 그룹이 무엇인가?
- 한국인 vs 연길거주 조선족
- d. Propensity score 분석 방법을 사용한 이유가 무엇인가?
- 치료군과 대조군간의 confounding을 제거하여 RCT 같은 데이터를 만들기 위해서
- e. Propensity score를 어떤 방법으로 추정하였는가?
- **matching의 방법을 사용함** - f. 매칭된 데이터의 밸런스를 어떻게 평가하였는가?
- **이분형 변수의 SMD를 활용하여 0.2 미만일 때, balance가 잘 맞는 것으로 판단함** - g. 매칭 이후 분석은 매칭된 데이터라는 점을 반영하였는가? 반영하였다면 어떤 방법으로 반영하였는가?
- **매칭된 데이터는 서로 독립이 아닌데, 이를 반영하기 위해서 `logistic regression with correlation structure (GEE)`**를 사용함 - h. 연구의 결론이 무엇인가?
- 연길거주 조선족의 체질별 체형은 한국인과 유사하다
- 태음인 > 소양인, 소음인 체질 순으로, 연길거주 조선족과 한국인 체형이 차이가 났지만, 거시적으로는 비슷하다.
- 연길거주 조선족의 체질별 체형은 한국인과 유사하다

-
메타분석의 결과를 보고하는 논문 1편을 조사하여 다음에 답하시오.
-
연구질문(research question)이 무엇인가? PICOS 형식에 맞추어 답하시오.
- P: 허리수술 후 급성 수술후 통증 환자
- I: 침치료
- C: 가짜 침치료
- O: visual analogue scale (VAS)
- S: Randomized Controlled Trials
-
문헌검색에 사용된 데이터베이스는 무엇인가?
- pubmed
- Risk of bias를 평가하였는가?
- yes
- 결과를 요약하기 위해 사용한 요약통계량이 무엇이었는가?
- standard mean difference
- 이질성을 평가하였는가? 평가하였다면, 어떤 방법으로 평가하였는가?
- using the chi-square test and the Higgins I2 test.
- sub group analysis
- Reporting bias를 평가하였는가? 평가하였다면, 어떤 방법으로 평가하였는가?
- Cochrane handbook에 의해 리뷰어2명이 평가했다고 나와있으나, 구체적인 방법은 명시되지 않음.
- 민감도 분석을 수행하였는가? 수행하였다면, 내용과 결과를 요약하시오.
- no
- 이 연구의 결론은 무엇인가?
- 수술 후 통증의 침 치료에 대한 결과는 수술 후 24시간의 통증 강도에 대한 VAS에서, 가짜 침술과 비교할 때 효과가 있다.(SMD -0.67(-1.04~-0.31), P=0.0003)
-
본인이 관심있는 주제에 대하여 아래 질문에 따라 임상연구 계획을 세워 보시오. (관심있는 주제를 떠 올리기 어려울 경우 1강 강의록의 ‘Research Question’ 슬라이드에 있는 예제 중 하나를 이용하여도 좋다.)
- 연구질문(research question)이 무엇인가?
- P: 허리수술 후 만성 통증 환자
- I: 도침 치료
- C: 가짜 도침치료
- O: VAS
- S: Randomized Controlled Trials
- 이 연구는 descriptive studies, analytic studies, clinical trials 중 어느 단계에 속하는가?
- descriptive studies - Meta-analysis
- 이 연구의 주요 결과변수와 주요 독립변수(위험요소 또는 치료법)은 무엇인가?
- VAS - 도침치료
- 이 연구의 디자인은 무엇인가? (case-control, cross-sectional, cohort study, trial, meta analysis 등)
- meta analysis
- 이 연구에서 발생할 것으로 우려되는 bias는 무엇인가? 대응책은 무엇인가?
- publising bias
- 대응책
- Trim-and-Fill method 사용
- Largest study anaysis
- 이 연구에 작용할 것으로 우려되는 confounder는 무엇인가? 그것을 어떻게 다룰 것인가?
- 연령, 성별, 소득 수준
- 대응책
- 디자인 단계에서 랜덤화
- 데이터 분석단계에서 confounding 보정
- Stratification or Adjustment or Propensity score analysis
- (Extra credit) 이 연구에 알맞은 통계분석계획을 세워 보시오
- 요약통계량 선정
- 연속형 type의 outcome 사용 -> MD로 선정
- VAS는 scale이 다를 수 있다 -> SMD로 선정
- summary measure를 RR로 선정
- 통계모형을 fixed effect model로 선정 후, 이질성이 보이면
- Random effec model로 변경
- sub group analysis 시행
- publication bias 확인
- funnel plot을 그려보고 확인 될 경우
- 대응책
- Trim-and-Fill method 사용
- 요약통계량 선정
- 연구질문(research question)이 무엇인가?