의연방02) 이환율과 사망률
Morbidity and Mortality



📜 제목으로 보기✏마지막 댓글로

Incidence or Incidentce rate
- 분모:
전체인구가 아니라특정 기간동안위험에 노출된 인구 수- 위험에 노출된을 어떻게 정의? 언제든지 분자(새롭게 질병발생 환자)로 올라갈 수 있는 가능성이 있는 사람만 포함한다.
- 즉, 새롭게 질병 발생이 가능한 사람만 분모에
- ex> 자궁암의 incidence rate 계산 -> 자궁암 가능성이 있는 = 자궁이 있는 = 여성들만 분모에 넣어야한다(남성 빼야한다. 자궁적출술 여성은 빼야한다)
- 분자:
새롭게질병이 발생한 환자수 -
구체적으로 1000명당 인씨던트 레이트 -> 분자/분모에 * 1000
-
1000대신 다른 숫자도 원하는 대로
곱해줘서 N명당 incidence rate으로 명명한다.
-
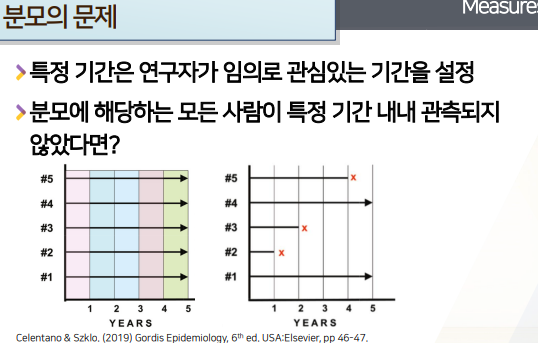

- 연구자가 정한 특정기간동안
모든 사람 다 관측시 -> 분모가 사람 수-
Cumulative incidence 또는 incidence proportion이라고도 한다.

-
Cumulative incidence 또는 incidence proportion이라고도 한다.
- 연구자가 정한 특정기간동안
일부기간만 관찰되는 사람 1명이라도 존재시 -> 분모가 py- (Cumulative incidence와 구분해주기 위해서) incidence density, person-time incidence rate라고 한다.

- (Cumulative incidence와 구분해주기 위해서) incidence density, person-time incidence rate라고 한다.
- incidence를 보면
분모를 보고 몇명당인지/몇py인지를 먼저 봐서 계산방법을 이해하자

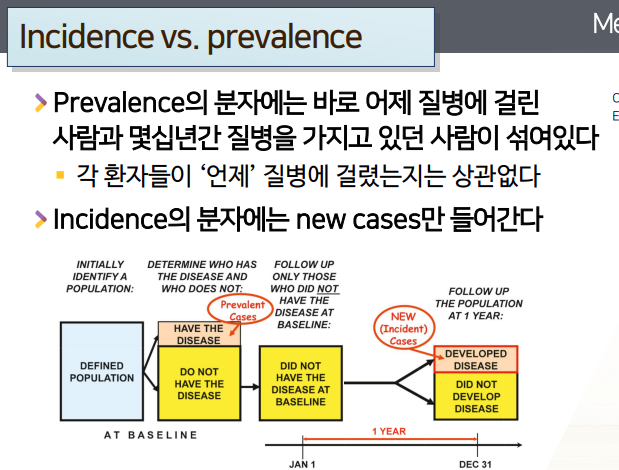
- 그림으로 보면,
관심있는 파퓰레이션(파란색)이 있을 때- 특정시점에 질병을 가진 사람 =
주황색 - 특정시점에 질병을 가지고 있지 않은 사람 =
노란색-
prevalence:
주황색/파란색
-
prevalence:
-
정해진 특정시점에 질병 없는노란색을 시작으로1년간 follow-up한다고 쳤을 때,-
incidence:
노란색(2nd, at baseline)중 새롭게 발생한 빨간색테두리의주황색(2nd)/ 전체노란색(2nd, at baseline)- incidence는
분자가 새롭게 발생해야하기 때문에, 애초에 시작점에서 질병 발생위험을 가지고 있지만질병이 없는 환자를 대상으로 한다
- incidence는
-
incidence:
- 특정시점에 질병을 가진 사람 =
-
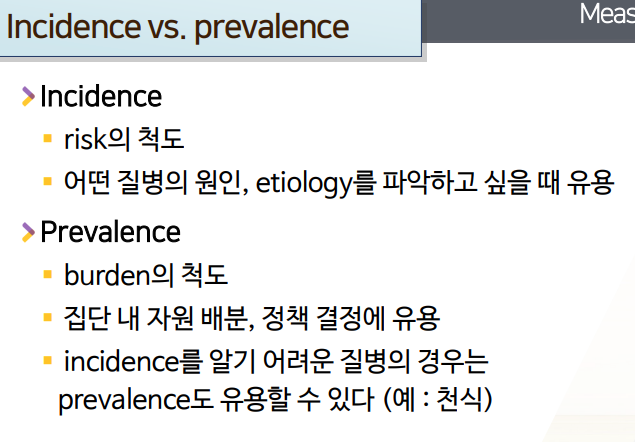
Incidence: 어떤 기간동안 새롭게 발병한 질병에 대한 것이므로 -> 질병이 없는 사람이 새로 질병이 발생할 가능성에 대한 정보를 준다 -> 질병에 걸릴 확률/위험에 대한 정보를 준다.
- risk(위험)의 척도
- 어떤 질병의 원인, etiology를 파악하고 싶을 때 유용
-
Prevalence: 프리벌런스는 옛날에 걸린사람 + 지금 걸린 사람을 섞어서 다 포함하고 있기 때문에, 새로운 질병이 얼마나 발생하기 쉬운지에 대한 정보는 없고, 지금 상태에서 영향을 받고 있는 사람/고통받고 있는 사람이 어느정도냐를 제는 것
- burden의 척도
- 원인보다는 집단내 메디컬서비스, 자원을 어떻게 배분할 것인가, 헬스 서비스 관련 정책을 어떻게 결정할 것인지(어디 질병 프로그램에 돈을 더 투자할 것인지 결정)에 유용
- 질병의 위험은 인씨던스가 더 유용하지만, **경우에 따라 인씨던스를 알기 어려운 질병도 있다.
-
ex> 천식 -> 정의도 떨어지지 않고, 증상도 서서히 드러나기 때문에 언제부터 발병했는지 판단불가 -> new case인지 알기 어려우므로 인씨던스 계산이 어렵다 -> 집단간의 비교나 시간에 따른 비교가 어려우므로 특정시점에서 계산해버리는 prevalence를 계산이 더 유용하다
-
ex> 천식 -> 정의도 떨어지지 않고, 증상도 서서히 드러나기 때문에 언제부터 발병했는지 판단불가 -> new case인지 알기 어려우므로 인씨던스 계산이 어렵다 -> 집단간의 비교나 시간에 따른 비교가 어려우므로 특정시점에서 계산해버리는 prevalence를 계산이 더 유용하다
- 공식: Prevalence = Incidence × Duration of disease
- Incidence가 시간에 따라 변하지 않고,
- prevalence가 너무 높지 않고
- 인구유입과 유출이 같은 경우 성립 성립한다
- 질병 앓는 기간 x 인씨던스를 곱해서 프리벌런스를 구한다.
- 대충 서로 비례한다고 직관적으로 생각할 수 있다.
-
직관(공식처럼 비례)과 어긋나는 경우
-
인쓰던스는 높지만 x 상수역할을 하던 Duration of disease가 아주 짧은 경우(금방 치료or사망) -> 인씨던스가 높아도 prevalence가 낮다
-
인씨던스가 아주 낮지만 x 상수역할을 하던 Duration of disease가 아주 긴 경우(오래동안 치료되지 않은 체 생존하고 있음) -> 인씨던스가 낮아도 prevalence가 높다

-
사망데이터
-
사망데이터는 생각해보면, proportion 및 prevalence의 개념이 의미가 없다
- 언젠간 모두 사망하므로 -> 언젠가 모두 사망O로 바뀜 -> 사망 O/X의 비율보다는 사망
시점(언제 사망)이 중요하므로 mortalityrate를 본다.
- 언젠간 모두 사망하므로 -> 언젠가 모두 사망O로 바뀜 -> 사망 O/X의 비율보다는 사망
-
Mortality Rate(사망률)
- Risk of dying(사망
위험의 측도) - Disease severity(시비리티)의 측도 (이 질병에 걸렸을 때
사망 률높다 -> 질병의심각도높다) - 치료 효과의 측도: 반대로 확줄어든다면 좋은 치료의 측도도 된다.
- Incidence rate의 proxy(대체자)로 기능할 수도 있다
- 조건 1) 치명률이 높은 병
- 조건 2) 투병기간이 짧은 병
- 새롭게 걸렸는데
금방+사망하는 병 -> 발병 인씨던스와 사망과 비슷한 이벤트가 된다. -> 사망률을 인씨던스 레이트 대신 쓰게 된다.
- 새롭게 걸렸는데
- Risk of dying(사망




- 사망률을 집단 전체가 아니라 나이or성별or진단명으로 나눠진 subgroup에 대해서만 구할 수 도 있다.
- age-specific rate : 분자와 분모에 같은 나이 조건을 걸어야 한다
- 예>
10세 미만아동의 연간사망률 -> 분모도10세 미만의 그해 7월1일 아동수 -> 분자도10세미만의
- 예>
- Disease-specific mortality의 예 : 분모는
전체인구수-> 분자만특정질병으로 사망 인구수
- 사망률(7월1일
전체 인구수)에 비해 치명률의 분모는특정 질병을 가진 사람이 대상이다- 곱하기 100을 하는 퍼센티지 개념을 많이 쓴다.
-
어떤 질병에 걸린 사람 중 몇프로가 죽었냐?에 대한 것이다.
- 질병의 심각도에 대한 측도: 심각한 병이면 치명률이 높다
- 치료 효과의 측도: 좋아지만 치명률이 낮아진다.

- 줄여서 YP LL, 최근에 많이 쓰는 측도
- 나이가 많은 사람이 사망하는 것보다 어린 사람이 사망하는 것이 더 큰 손실임을 반영한 측도
- 계산할 때는 기대수명부터 계산하고 -> 사망한 사람의 나이에서 뺀 뒤 총합
- 기대수명 계산법을 정하느냐에 따라 달라지니 먼저 확인한다.
- 아래 그림은
10만명당사망률에 대한age-adjusted mortality ratevsYPLL비교 표- 그냥 보면 Heart disease(심장병)가 제일 사망률이 높아보인다
- mortality rate로만 보면, Heart disease(심장병)이 167 가장 큰 원인 같고, Accidents(사고사)를 보면, 40.5으로 1/4정도 밖에 안되는 것 같다
- 하지만, YPLL도 같이 보게 되면 Accidents(사고사)가 더 높다 -> 어린사람이 더 큰손실이라는 YPLL개념 없이보면, 사망률은 1/4정도 였지만, YPLL로는 조금 더 높았다 -> 사고사 한 사람이 젊은 사람들이 더 많아서 그로인한 손실이 높게 평가되었다`
- Suicide도 심장병의 1/10정도였지만, YPLL로 보면 1/3수준으로 손실을 높제 잡아줬다 -> 젊은 사람이 많았다.
-
심장병에 의한 사망률을 줄이는 것도 중요하지만, YPLL을 보니, 사고사+자살을 방지하는 정책이 포텐셜라이프(기대수명)을 더 늘리는 방법일 수 있다.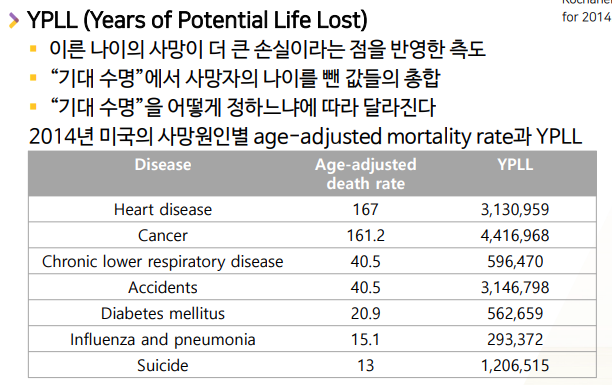
-
- 그냥 보면 Heart disease(심장병)가 제일 사망률이 높아보인다
사망률의 비교
- 사망률 비교시 항상 주의해야할 것은
나이라는 팩터다. 사망관련 자료를 볼 때 + 임상자료에서 생존분석시 항상 설명변수로 들어간다`- 나이가 사망과 관련성이 깊은 인자이기 때문
-
다른 집단간 사망률 비교 ->
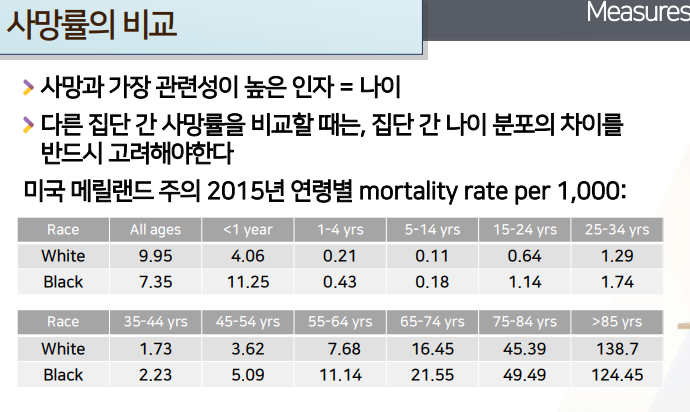
집단간 나이 분포차이부터 고려- 예시> 1000명당 사망률
- 모든 나이대 : 백인 9.95 , 흑인 7.35명 사망 -> 이렇게 보면 흑인이 더 의료서비스 접근성이 낮다거나 접근후 인종차별때문에 흑인이 좀 더 사망할 것 같은데, 이상하게 백인이 사망률이 높은 것 같다고 생각할 수 있다.
-
나이대로 쪼개보면, 왜 이런 결과가 나왔는지 확인할 수 있다.
- 각 연령대 모두에서 흑인의 사망률이 더 높다. 오직 85세 이상에서만 백인이 더 높다
- 85세이상 그룹때문에, all alges에서 백인의 사망률이 더 높은 것처럼 보이게 된 것이다.
- 이런 현상의 원인: 백인은 85세이상이 많았다(많이 살아남은 것) -> 그만큼 많이 죽었다. 흑인은 85세이상이 너무나 적었다. -> 이미 더 젊은 나이세 흑인들이 사망했지만, 그게 반영되지 않았음. + 85세 이상그룹이 인구수만 많이 측정되어 많이 반영되었다. -> 전체적으로 백인 사망률이 더 높은 것처럼 보이게 된 것
- 이렇게 전체사망률을 crude death rate로 비교하게 되면, 집단간의 사망률 비교가 정확하지 않게 된다.
- 예시> 1000명당 사망률
-
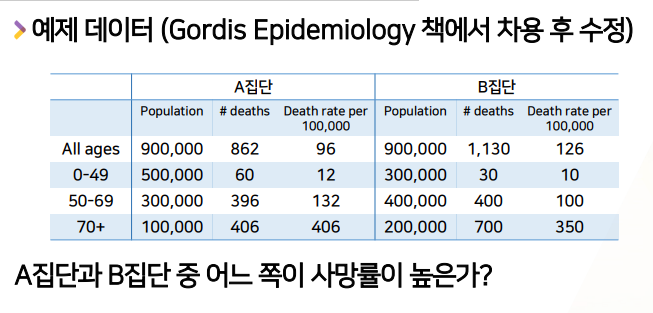
예제 데이터
- 2개의 집단, 인구 수 전체=90만명, 1년간사망자 수 = A집단 860 vs B집단 1130
- 2개의 집단, 인구 수 전체=90만명, 1년간사망자 수 = A집단 860 vs B집단 1130
-
Q. 어느쪽이 사망률이 높은가?
- 전체적으로 봤을 때는, B집단의 사망자수가 많으니 -> B집단의 사망률이 더 높은 것처럼 보인다.
- 각 나이 그룹별 10만명당 사망률을 계산해보자.
- 각 나이 그룹별 사망자수 / ( 전체인구수 ) X 10만 -> 10만명당 사망률
- 하지만, 나이 효과를 보정해서 보면 달라진다
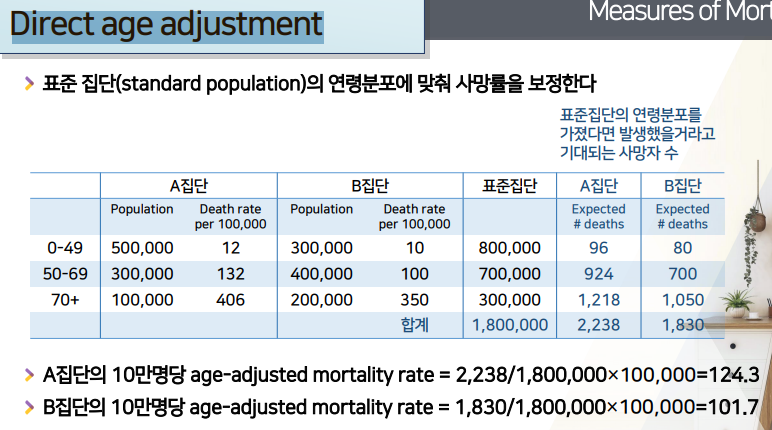
- 각 집단별(칼럼) / 연령그룹별(행) / 인구수(칼1)와 10만명당 사망률(칼2)
-
그룹별 10만명당 사망률에 대해,
연령분포를 통한 보정을 하기 위해서는- 먼저
표준집단을 상정해야한다.- 국가 인구통계에서 나온 것으로 정할 수 도 있고
- 인구 수가 비슷한 2집단의 경우 -> 두 집단의 합 =표준집단으로 잡을 수 있다.
- 각 그룹별 인구수합 -> 3그룹 다 합치면 90 + 90 = 총 180만명이 표준집단
-
구해놓은 그룹별 / 집단별 10만명당사망자률을 이용해서 -> 표준집단 나이분포라면 몇명이 사망했을지
표준집단이라면 사망자 수를 구한다- 각 그룹별로 A,B서로 다른 나이분포를 가지고 있으니 -> 미리 구해둔 사망률 + 표준집단으로 인구수 통일 -> 사망자 수 계산
-
ex> 0-49집단: 80만명(800,000) X 각 집단의 10만명당 사망률(
10만명당12 = 12 / 100,000)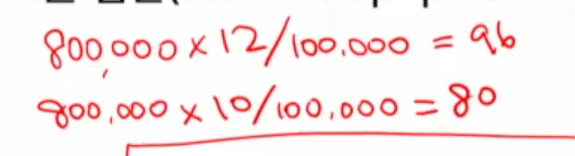

-
기대되는 사망자수를 각 집단별로 각각 구한 뒤 다 더해준다.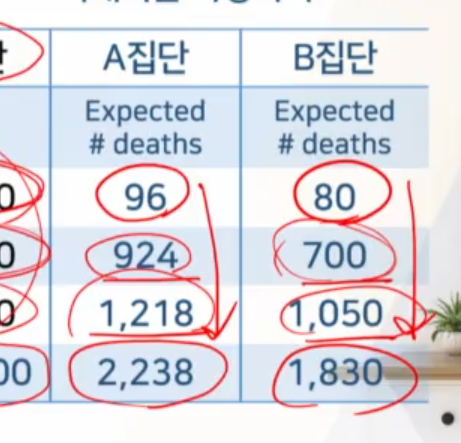
-
각 집단별로 나온
기대되는 사망자수에다가/ 표준인구 총합을 나눈 뒤,X 10만을 곱해서각 집단의 10만명당 age-adjusted mortality rate를 구한다.
-
전체적으로 사망률을 봤을 땐, B집단의 사망자수가 많으니 -> B집단의 사망률이 더 높은 것처럼 보였지만,
10만명당 에이지-어저스티드 모탈리티 레잇을 이용해서 보면, B집단보다 A집단의 사망률이 더 높다.- crude 모탈리티 레잇을 본 것과는 반대의 결과가 나온다.
- 먼저
- 앞의 예처럼,
인구 수가 비슷하면 합을 이용하는 hypothetical population(하이포 세티칼 파퓰레이션)으로 실존하지 않는 가상의 인구집단을 만들어서 할 수 도 있다. - 아니면, 인구조사통계를 이용할 수 있다.
-
주의점: 표준집단은, 비교하려는 비교집단이 너무 드라마틱하게 다르면, 비현실적인 통계량이 될 수 있다.
-
나이 말고도 다른 특성(성별, SES 등)의 분포 보정에도 사용할 수 있다.

Indirect age adjustment
-
Direct age adjustment의 적용이 불가능할 때가 있다.
- 이럴 때는 사실 할 수 있는 것이 많지는 않다
-
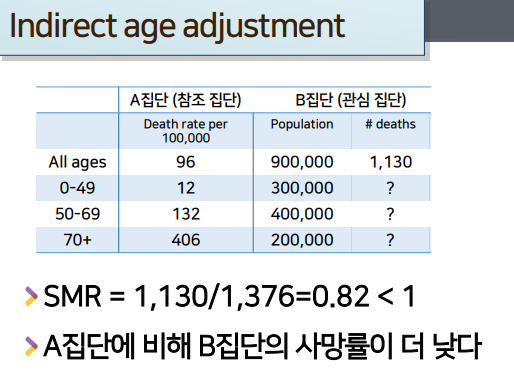
관심집단의 사망률을 -> 이미 잘 알려진 참조집단과 비교하고 싶을 때 사용한다.
- 관심집단의 전체 사망률만 알고 있고, 연령그룹별 인구 수는 알고 있으나,
연령그룹별 사망률을 모를 때 -
참조 집단의 연령그룹별 사망률이 있다고 가정할 때, 그것을 이용한다

- 관심집단의 전체 사망률만 알고 있고, 연령그룹별 인구 수는 알고 있으나,
- 참조집단의 연령별 사망률이 있고, 그것을 이용해, 몇명이 사망했을 것이라고 기대되는지 계산후, 그것의 비율로 계산한
SMR을 이용한다.- 분모: 특정기간동안, 참조집단과 같은 연령별사망률을 가졌더라면 발생됬을거라 기대되는, 사망자의 수
- 분자: 특정기간동안, 실제로 관측된, 사망자의 수
- 곱하기 100한 뒤 %
-
A를 참조집단, B집단을 관심집단이라고 가정한다.
- A집단은 참조집단으로서 연령그룹별
10만명당 사망률(사망률 분포)이 알려져있다- 연령그룹별로
10만명당 몇명씩 사망했는지도 다 알려져있다.
- 연령그룹별로
-
B집단은
연령그룹별 인구수+실제 총 사망자수만 알고 있지만,연령그룹별 사망자수는 모른다- 연령그룹별로 1130명이 어떻게 분포하는지 모른다. 연령그룹별 10만명당 사망자수를 모른다.
- A집단은 참조집단으로서 연령그룹별
-
Q. A집단과 비교해서 관심집단 B의 사망자률이 더 높을까?
-
B의 각 연령그룹별 인구수에서 X참조집단 A의 10만명당 사망률을 가졌더라면 ->몇명이 죽었을까? 기대되는 사망자 수를 계산한다- B집단에서는 참조집단의 연령그룹별 사망률을 참고 했을 때, 36명이 죽었을 거라 기대할 수 있다.
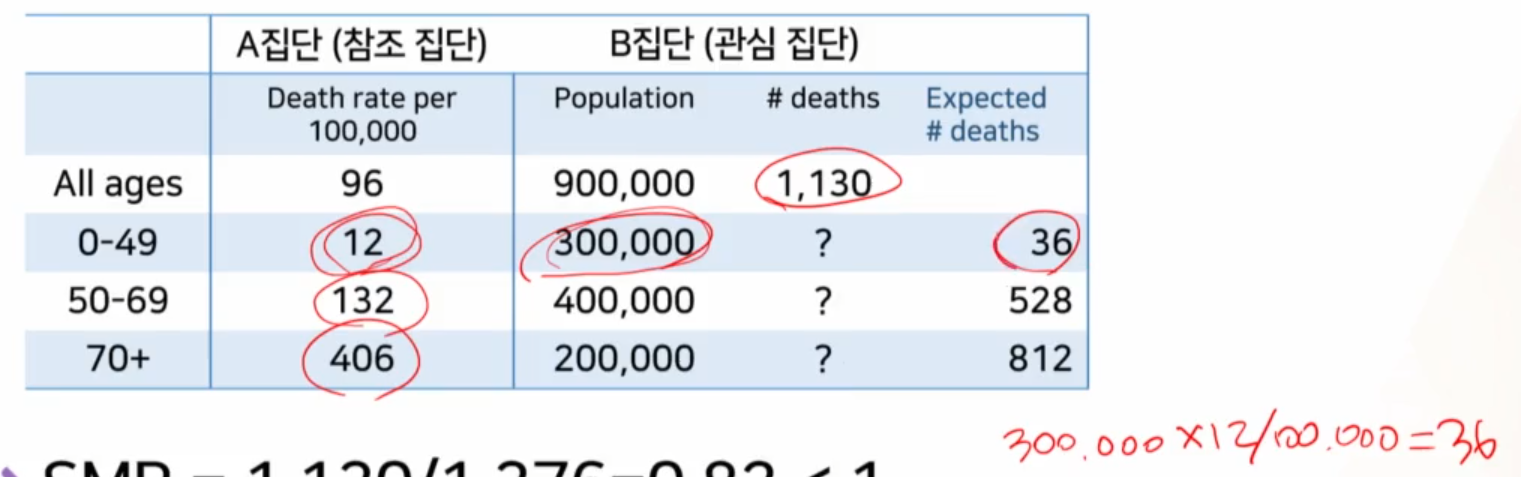
- B집단에서는 참조집단의 연령그룹별 사망률을 참고 했을 때, 36명이 죽었을 거라 기대할 수 있다.
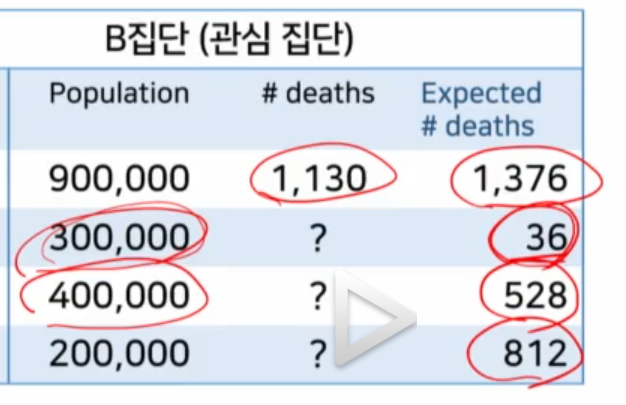
- 1.의 방법으로 각 연령그룹별 사망자 수를 각각 구한 뒤 -> 다 더한
기대되는 총 사망자수를 구한다.- 참고로
실제 총 사망자수는 이미 알고 있는 상태에서,A집단 참조 기대되는 총 사망자수를 구한 상태다- 기대되는 총 사망자수: 1,376
- 실제 총 사망자수 : 1,130
- 참고로
-
실제 총 사망자수 / A집단의 연령그룹별 사망률 참조 기대되는 총 사망자수를 계산하여 1보다 큰지 작은지 확인한다.- 기대되는 것을 분모에 두고 -> 기대되는 것 대비 0.82 < 1-> 기대의 82%만 사망했다. -> B집단의 사망률이 A집단의 0.82로 사망률이 더 낫다

- 크게 인씨던스와 프리벌런스로 질병률을 계산했다.
- 인씨던스: 특정기간동안 위험 노출 인구집단 내 -> 새롭게 질병 발생 비율
- 인씨던스의 분모를 계산시, 모든 기간이 아니라 일부만 관찰되는 환자 존재시 -> 분모를 person 대신 person-time으로 계산하며 -> person-time incidence rate이라 한다
- 질병 발생하는 속도 = 새롭게 질병발생하는 것에 대한 얘기 -> risk의 척도
- 프리벌런스: 고정된 특정시점에서 질병에 거린 사람의 비율
- 특정시점에서 얼마나 힘든상탠지 -> burden의 척도
- 인씨던스: 특정기간동안 위험 노출 인구집단 내 -> 새롭게 질병 발생 비율
- 모탈리티 레잇: 특정기간동안 발생한 사망자수를 / 특정기간 중앙시점의 인구수로 나눈 것
- 년간사망률 -> 7월1일 인구수로 나눈다.
- 그외 모탈리티를 보는 것으로는 case-fatality라던가 YPLL의 메저도 있다.
- 집단간의 모탈리티 레잇을 비교시 반드시 연령분포를 고려해서 비교해야한다
- 연령분포 차이를 보정하는 2가지 방법이 있다.
- direct age adjustment : age-adjusted mortality rate
- indirect age adjustment : SMR
- 연령분포 차이를 보정하는 2가지 방법이 있다.
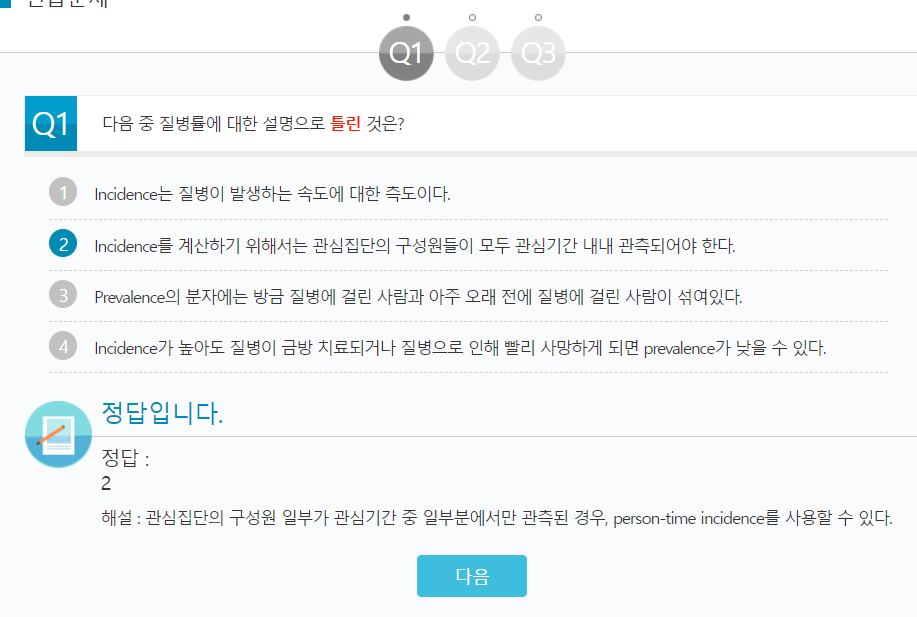
다음 중 질병률에 대한 설명으로 틀린 것은?
1 Incidence는 질병이 발생하는 속도에 대한 측도이다.
2 Incidence를 계산하기 위해서는 관심집단의 구성원들이 모두 관심기간 내내 관측되어야 한다.
3 Prevalence의 분자에는 방금 질병에 걸린 사람과 아주 오래 전에 질병에 걸린 사람이 섞여있다.
4 Incidence가 높아도 질병이 금방 치료되거나 질병으로 인해 빨리 사망하게 되면 prevalence가 낮을 수 있다.
정답입니다. 정답 : 2 해설 : 관심집단의 구성원 일부가 관심기간 중 일부분에서만 관측된 경우, person-time incidence를 사용할 수 있다.
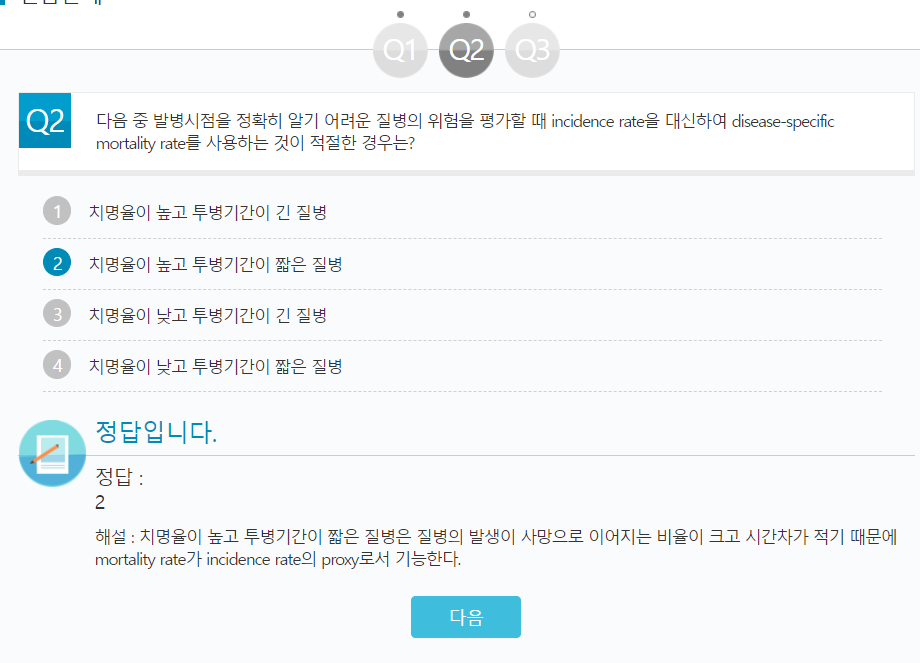
다음 중 발병시점을 정확히 알기 어려운 질병의 위험을 평가할 때 incidence rate을 대신하여 disease-specific mortality rate를 사용하는 것이 적절한 경우는?
1 치명율이 높고 투병기간이 긴 질병
2 치명율이 높고 투병기간이 짧은 질병
3 치명율이 낮고 투병기간이 긴 질병
4 치명율이 낮고 투병기간이 짧은 질병
정답입니다. 정답 : 2 해설 : 치명율이 높고 투병기간이 짧은 질병은 질병의 발생이 사망으로 이어지는 비율이 크고 시간차가 적기 때문에 mortality rate가 incidence rate의 proxy로서 기능한다.
-
상관없는 개념이야기
- age-specific rate : 분자와 분모에 같은 나이 조건을 걸어야 한다
- 예> 10세 미만 아동의 연간사망률 -> 분모도 10세 미만의 그해 7월1일 아동수 -> 분자도 10세미만의
- Disease-specific mortality의 예 : 분모는 전체인구수 -> 분자만 특정질병으로 사망 인구수
- age-specific rate : 분자와 분모에 같은 나이 조건을 걸어야 한다
-
incidencate rate 대신 prevalence를 쓰는 예-> 천식
- 천식 -> 정의도 떨어지지 않고, 증상도 서서히 드러나기 때문에 언제부터 발병했는지 판단불가 -> new case인지 알기 어려우므로 인씨던스 계산이 어렵다 -> 집단간의 비교나 시간에 따른 비교가 어려우므로 특정시점에서 계산해버리는 prevalence를 계산이 더 유용하다
-
incidencate rate 대신 (Disease-specific) mortality rate를 사용하는 경우
- 치명율이 높고 빨리 사망해서
-
인씨던스의 새롭게 발생과 ==사망률의 이벤트가 비슷해진 경우 - 치명률이 높고 투병이가 짧은 질병
-
- 치명율이 높고 빨리 사망해서
다음은 2021년 A집단과 B집단의 연령별 인구분포와 사망자수이다. 두 집단을 합한 인구집단을 표준집단으로 해서 A집단과 B집단의 1000명당 age-adjusted mortality rate를 구하여라.
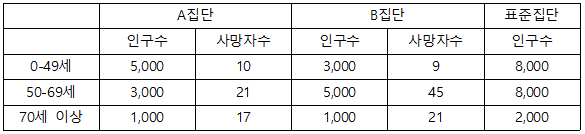
- 표준집단 구하기: 두 인구수의 합 -> 총 표준집단 인구수 : 18000
-
표준집단이였다면 기대되는 사망자수(해당 집단의 1000명당 사망률 X 표준집단 인구수)를 연령별로 집단별로 구하기
- 문제에서 주어진 단위(1000명당)으로 사망률도 계산할 것
- 각 연령그룹별/집단별
1000명당사망률부터 구하기 - 1000을 곱해서 %같은 률- A: 10 / 5000 1000 = 2 | B: 9 / 3000 1000 = 3
- A: 21 / 3000 1000 = 7 | B: 45 / 5000 1000 = 9
- A: 17 / 1000 1000 = 17 | B: 21 / 1000 1000 = 21
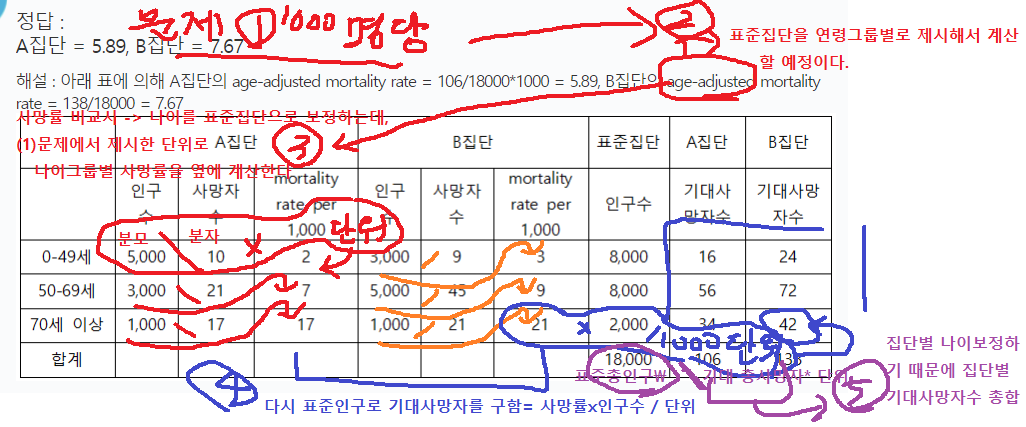
- 표준집단을 인구수로 가정 && 구한 1000명당 사망률을 반영해
표준집단이었더라면 기대되는사망자수구하기 - 1000을 나눠서 실제 수- A: 2 x 8000 / 1000 = 16 | 3 X 8000 / 1000 = 24
- A: 7 x 8000 / 1000 = 56 | 9 X 8000 / 1000 = 72
- A: 17 x 2000 / 1000 = 34 | 21 X 2000 / 1000 = 42
-
집단별 기대되는 사망자수 더하기
- A: 106 | B: 114
-
각 집단별로 나온 기대되는 사망자수 /
표준인구 총합을 나눈 뒤,X 단위(1000)을 곱해서 각 집단의 단위명당 age-adjusted mortality rate를 구한다.- A: 106 / 18000 * 1000 = 5.8888 -> 소수 2번째자리까지 반올림 -> 5.89
- B: 138 / 18000 * 1000 = 7.6666 -> 7.67
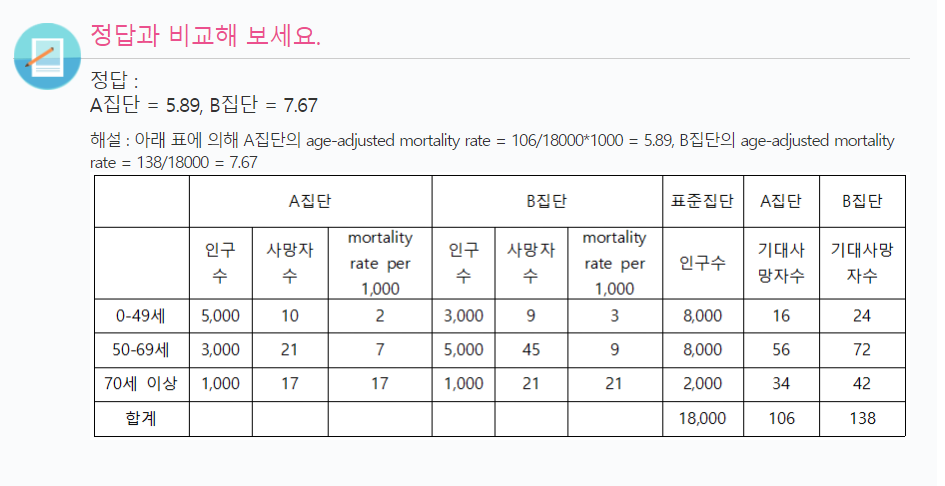
계산 예제 참고
- Direct age adjustment 예시
-
그룹별 10만명당 사망률에 대해,
연령분포를 통한 보정을 하기 위해서는- 먼저
표준집단을 상정해야한다.- 국가 인구통계에서 나온 것으로 정할 수 도 있고
- 인구 수가 비슷한 2집단의 경우 -> 두 집단의 합 =표준집단으로 잡을 수 있다.
- 각 그룹별 인구수합 -> 3그룹 다 합치면 90 + 90 = 총 180만명이 표준집단
-
구해놓은 그룹별 / 집단별 10만명당사망자률을 이용해서 -> 표준집단 나이분포라면 몇명이 사망했을지
표준집단이라면 사망자 수를 구한다- 각 그룹별로 A,B서로 다른 나이분포를 가지고 있으니 -> 미리 구해둔 사망률 + 표준집단으로 인구수 통일 -> 사망자 수 계산
-
ex> 0-49집단: 80만명(800,000) X 각 집단의 10만명당 사망률(
10만명당12 = 12 / 100,000)
-
기대되는 사망자수를 각 집단별로 각각 구한 뒤 다 더해준다. -
각 집단별로 나온
기대되는 사망자수에다가/ 표준인구 총합을 나눈 뒤,X 10만을 곱해서각 집단의 10만명당 age-adjusted mortality rate를 구한다. -
전체적으로 사망률을 봤을 땐, B집단의 사망자수가 많으니 -> B집단의 사망률이 더 높은 것처럼 보였지만,
10만명당 에이지-어저스티드 모탈리티 레잇을 이용해서 보면, B집단보다 A집단의 사망률이 더 높다.- crude 모탈리티 레잇을 본 것과는 반대의 결과가 나온다.
- 먼저