의연방03-2) 삐뚤림(bias)
bias(통추개념1)



📜 제목으로 보기✏마지막 댓글로
- Bias

일부만 보다보니 데이터가 주는 에러 sampling error는 2가지로 나누어진다.
-
random error: 랜덤하게 sample을 취할 때, 어제/오늘 완전히 같은 방법으로 뽑았는데도 대부분은 다르게 추출된다. randomness자체에서 오는 변동성에서 오는 에러, 우연에 의해서 발생하는 에러. 피할수 가 없음.- 우연(chance)에 의해서 발생하는 에러
- 특정한 방향성이 없다: 상관관계가 더 크게 보이게 측정됨? 더 작게 측정됨? 상관관계를 에러에 의해 한쪽으로 보내진 않는 에러다.
- 샘플 사이즈를 늘릴 수록 random error는 줄어든다: 피할수는 없지만 줄일 수 있다. ex> 100만명을 알고 싶었는데, 10명씩 뽑는 실험? -> 뽑을 때 마다 다르다 / 90만명씩 뽑는다? -> 겹처서 sample마다 비슷한 특성을 가질 수 밖에 없다.
-
systematic error:- 연구디자인, 수행방법, 분석방법에 의해 발생하는 에러
- 보통 한쪽 방향으로 작용한다: 상관관계를 실제보다 크게 보이게 하거나, 작게보이게 하는 에러다
- 샘플 사이즈를 늘려도 줄어들지 않는다
-
Bias: sampling error 중에
systematic error에 의해 =연구디자인, 수행방법, 분석방법에 의해 발생하는 에러- 흔한, 유명한 바이어스만 살펴볼 것
-
내가 아무리 잘 뽑더라도, 그룹간 차이가 이미 systematic diffrence를 가지고 있는 그룹이라, 상관관계를 한쪽으로 방향성을 가지게 만드는, systematic bias를 가진다.
-
연구대상을 뽑을 때, 실제로 존재하지 않는 상관관계가, 있는 것처럼 발생한다.
- 위험노출 그룹 vs 위험노출X 그룹 을 각각 뽑을 때처럼
- 그룹간 다를 수 밖에 없는, 다른 방식의 연구디자인으로 뽑은 경우
- cases vs controls
-
질병o, 질병x 사람에 대해서,
실제와 똑같은 표집이 아닌, 디자인상으로 다를 수 밖에 없는 방법으로 표집을 하는 경우- 상관관계가 없음에도 있도록 보일 수 밖에 없음
-
질병o, 질병x 사람에 대해서,
- 위험노출 그룹 vs 위험노출X 그룹 을 각각 뽑을 때처럼
- 예) Open surgery vs. robotic surgery 그룹을 각각 뽑는데
- 내가 아무리 잘 뽑으려고 해도 관찰연구의 경우, 두 그룹이 다를 수 밖에 없음. robotic surgery 그룹 == 비싼 수술을 받는 그룹 == 경제적으로 윤택 == 좀더 건강에 신경많이 씀(운동, 영양상태 더좋음) -> 잘 뽑아도
시스테머릭 difference는 존재할 수 밖에없다. ->시스테머릭 에러가 발생한다 ->상관관계가 한쪽으로 더 보이게 한다
- 내가 아무리 잘 뽑으려고 해도 관찰연구의 경우, 두 그룹이 다를 수 밖에 없음. robotic surgery 그룹 == 비싼 수술을 받는 그룹 == 경제적으로 윤택 == 좀더 건강에 신경많이 씀(운동, 영양상태 더좋음) -> 잘 뽑아도
- 해결하려면?
- 디자인 자체를 잘 해서, 비슷한 그룹을 표집되도록 해야한다.
- RCT로 랜더마이즈하게 control trial를 해야한다.
-
환자들을 recruit한 뒤 -> open vs robotic surgery받을 지를 랜덤하게 결정하게 해야한다.(원래는 잘사는 사람들이 robotic을 고르기 때문에, 그 전에 랜덤하게 줘야한다)
- 가만히 두면, 경향성을 가진체로 그룹이 결성되니, 미리 그룹결성을 랜덤하게
- social economy status에 따른 그룹선택을 못하게 -> 미리 랜덤하게 선택되도록 하기

-
환자들을 recruit한 뒤 -> open vs robotic surgery받을 지를 랜덤하게 결정하게 해야한다.(원래는 잘사는 사람들이 robotic을 고르기 때문에, 그 전에 랜덤하게 줘야한다)
-
예를들어, 천식환자를 조사할 때, 흡연자(위험노출환자)가 무응답할 확률이 높다. -> 과소추정된다. -> 흡연과 천식의 상관관계가 더 약하게 보이게 한다.
-
예) 천식 환자 중 흡연자가 비흡연자에 비해 무응답 비율이 높다면?
- 일반적으로 무응답자는 응답자와 다른 특성을 가지고 있음이 알려져 있다
- 무응답률을 줄이기 위해 최대한 노력
- 무응답의 이유, 무응답자의 특성 파악을 위해 최대한 노력
- 연구에서 비교하는 그룹 간 misclassification rate가 비슷한 경우
- case를 -> control로 잘못 분류
- control을 -> case 잘못 분류
- 서로 비슷하게 잘못 분류됨
- 데이터에 노이즈가 많아짐
- 잘못된 입력된 것이 많을 때 노이즈가 많아진다고 한다.
- Association이 실제보다 더 약하게 (OR 또는 RR이 1에 가깝게) 추정된다
- 상관관계다 더 줄어든다 == OR이나 RR이 실제보다 더 1에 가깝게 나온다
-
case(질병O인 사람)가 control에 비해과거의 일(event들)을 더 잘 기억함으로 발생하는 bias- 예) 기형아 출산 여성은 정상아 출산 여성에 비해 임신 중 감염이나 이벤트를 더 잘 기억하는 경향
-
질병O인 사람으로서, 내가 낳은 아이가 기형아다 -> 출산 준비하는 중언제부터/왜/뭐가 잘못됬지 생각할 수 밖에 없다.기억을 되짚어 보면서 더 잘 기억하게 됨
-
- 예) 기형아 출산 여성은 정상아 출산 여성에 비해 임신 중 감염이나 이벤트를 더 잘 기억하는 경향
-
기억자체를 잘하고/못하고 문제가 아니라, 기억을 똑같이 하더라도,
질병O인 사람이 그것을 과대포장or과소포장을 더 잘함 -
case가 control에 비해 과거일을
더 잘 보고하거나,더 잘 누락함- 예) HIV환자가 성경험이나 약물 사용에 대해 보고하지 않는 경향,
- case가 덜 보고하려함
- 예) 폐암환자가 흡연력, 음주량을 줄여서 보고하는 경향
- case가 덜 보고하려함
- 예) HIV환자가 성경험이나 약물 사용에 대해 보고하지 않는 경향,
-
사람이다 보니, 상대방에게 어떻게 보일 것인지 생각하다보니 이러한 bias가 발생함
- 사람이 아닌 컴퓨터, ARS 등을 이용한 설문이 bias를 줄여줄 수 있다.
- 사망자의 배우자로부터 자료를 수집할 때, 아내들은 사망한 남편의 직업과 생활습관에 대해서 실제보다 더 좋게 보고하는 경향이 있음
- 치료군을 더 잘 모니터해서 질병 발생을 더 잘 찾아냄
- 내가 치료방법을 제시한 경우, 치료법의 부작용으로 나타나는 질병 때문에 -> 그 군을 더 열심히 모니터링 하는 경향 -> 발생해도 몰랐을 수 있는, 부작용으로 지켜보던 질병은 바로 잡아낸다.
- 예) 경구 피임약과 혈전 정맥염(thrombophlebitis)의 관계
- 경구 피임약 처방을 해준 경우, 약의 부작용을 의식한 의사가
- 데이터 측정과 수집을 최대한 표준화, 자동화한다
- 가능한 경우 랜덤화(randomize) 한다
- 할수만 있다면, 이미 그룹이 원래특성을 가진 체 나누기 전에, 전체 환자군을 먼저 recruit해놓고
- 어느 치료법을 쓸 것인지 random하게 그룹을 나누어서, 경제적지위 등이 안녹아들게 하기
- 어떤 위험요소 노출을 할 것인지를 random하게 나누어서 그룹을 나누기
- 할수만 있다면, 이미 그룹이 원래특성을 가진 체 나누기 전에, 전체 환자군을 먼저 recruit해놓고
- 가능한 경우 눈가림(blinding)한다
- 무응답을 줄이고, 무응답자 특성 파악을 위해 노력한다
- bias를 줄일 수 있는 통계방법을 사용한다
- Absolute risk는 risk라고도 하며, 질병이 발생할 확률이다.
- 질병과 위험요소 간의 상관관계를 파악하기 위해, relative risk, odds ratio, attributable risk 등을 사용한다.
- Relative risk는 위험요소에 노출되었을 때의 위험이, 노출되지 않았을 때의 위험에 비해 몇배인지 나타낸다.
- Odds ratio는 위험요소에 노출되었을 때의 오즈가, 노출되지 않았을 때의 오즈의 몇배인지 나타낸다.
- Attributable risk among the exposed는 위험요소에 노출된 경우의 질병발생확률에서 노출되지 않았을 경우의 질병발생확률을 뺀 값이다.
- Attributable risk for the population은 population 전체의 질병발생확률에서 위험요소에 노출되지 않은 그룹의 질병발생확률을 뺀 값이다.
- 관심 모집단의 일부분인 샘플을 표집하는 과정에서 발생하는 error중, random error가 아닌 연구디자인, 수행, 분석방법에 의해 발생하는 systematic error가 bias이다.
- 샘플로 뽑아서 발생하는 error 중에 random에러가 아닌 systematic error가 bias다.
- bias를 줄이기 위해서는 데이터 수집을 최대한 자동화, 표준화하고, 가능하면 랜덤화, 눈가림 하는 것이 좋다. 무응답을 되도록 줄이고, bias를 줄일 수 있는 통계방법을 사용하는 것도 좋다.
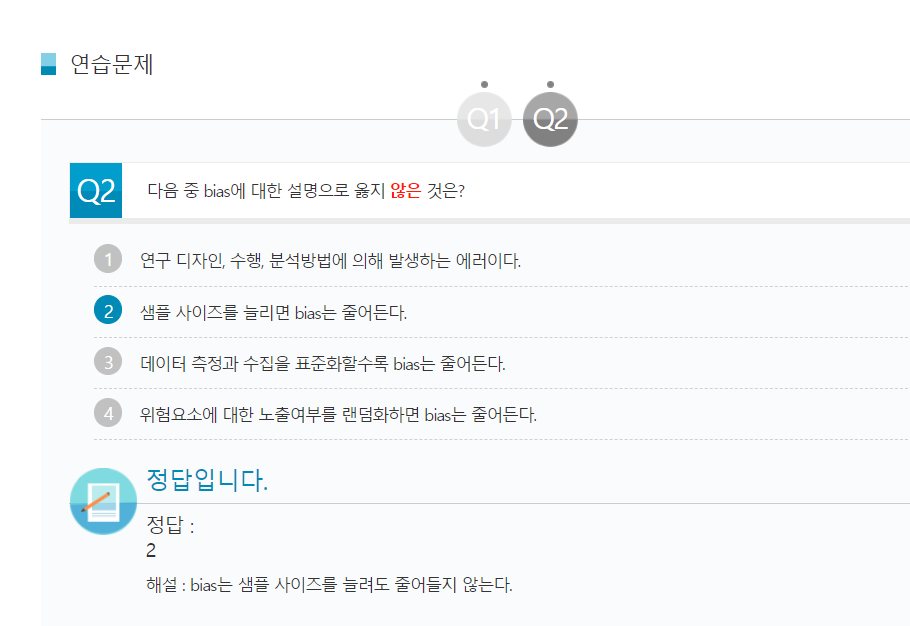
Q2 다음 중 bias에 대한 설명으로 옳지 않은 것은?
- 연구 디자인, 수행, 분석방법에 의해 발생하는 에러이다.
- 우연(chance)에 의해서 발생하는 에러 -> sampling error 중 random error
- 연구 디자인, 수행, 분석방법에 의해 발생하는 에러이다. -> sampling error 중 systematic error = bias
- 샘플 사이즈를 늘리면 bias는 줄어든다.
- 샘플 사이즈를 늘릴 수록
random error는 줄어든다: 피할수는 없지만 줄일 수 있다. ex> 100만명을 알고 싶었는데, 10명씩 뽑는 실험? -> 뽑을 때 마다 다르다 / 90만명씩 뽑는다? -> 겹처서 sample마다 비슷한 특성을 가질 수 밖에 없다. -
systematic error = bias는 random error와 달리, 디자인의 문제라서, 샘플 수 늘려도 랜덤문제를 해결할 수 없다.
- 샘플 사이즈를 늘릴 수록
- 데이터 측정과 수집을 표준화할수록 bias는 줄어든다.
- 데이터 수집을 최대한 자동화, 표준화하고,
- 가능하면 랜덤화, 눈가림 하는 것이 좋다.
- 무응답을 되도록 줄이고,
- bias를 줄일 수 있는 통계방법을 사용
- 위험요소에 대한 노출여부를 랜덤화하면 bias는 줄어든다.
-
치료법(case)vs 대조군 or위험요소 노출여부vs 대조군으로로 그룹을 나누는데, 2가지에 대해서는 랜덤화할 수 있으면 bias를 줄인다.
-
- 정답 :2
- 해설 : bias는 샘플 사이즈를 늘려도 줄어들지 않는다.