의연방08) Sample size
Sample size



📜 제목으로 보기✏마지막 댓글로
- 학습 목표
- Sample Size
- 정리하기
- R 고급 실습(이분형 결과변수의 samplesize계산을 위한 power.prop.test() ) 포함됨
-
샘플 사이즈를 계산하는 목적을 설명할 수 있다.
-
샘플 사이즈 계산의 주요 개념인 가설, α, β, 효과 크기에 대하여 설명할 수 있다.
-
이분형 결과변수를 사용하는 임상연구에서 필요한 샘플 사이즈를 계산할 수 있다.
- 제1종 오류 : 귀무가설이 참일 때 귀무가설을 기각하는 오류
- 제2종 오류 : 대립가설이 참일 때 귀무가설을 기각하지 못하는 오류
- α : 제1종 오류 확률의 최대값
- β : 제2종 오류 확률
- 샘플 사이즈 계산의 주요 개념
- 이분형 결과변수일 때 샘플 사이즈
- 기타 고려사항
- 샘플 사이즈가 너무 작으면 : 위험요소와 질병 간에 실제로 존재하는 상관관계를 보이지 못할 수 있다
- 샘플 사이즈가 너무 크면 : 비용과 시간이 많이 든다
- 유의미한 상관관계를 보일 가능성이 충분히 높은 샘플 사이즈를 확보하고 연구를 시작하자!
- 샘플사이즈 계산을 해야한다?! 왜??
- 없으면 포함하라고 리뷰어의 코멘트가 날아온다.
- IRB 심사받을 때도, Sample size 계산 근거를 제출하라고 날아온다.
- 너무 작으면 -> 데이터 정보 충분치 X -> 알고 싶은 정보를 알 수 없다.
- 위험요소-질병간의 상관관계 -> 인과관계를 알고 싶은데, 실제 존재하더라도 sample size가 작으면 알 수가 없게 된다
- 데이터가 크면 클수록 좋다
- 마냥 클 수 없는 것이 모으는데 비용과 시간이 많이 든다(환자수 1명당..)
-
보이고 싶은 것을 충분히 보일 수 있는 샘플 사이즈를 알아야한다
- 유의미한 상관관계(인과관계)를 보일 가능성 있는 충분히 높은 샘플 사이즈를 확보한 뒤 연구에 들어가자
-
유의미한 상관관계 보인다?!의 의미 : 상관관계에 대한 가설검정을 통과할 정도여야한다.
-
상관관계가 없다는 귀무가설을 기각해야한다 - p-value가 알파(0.05)보다 낫게 나와야한다
- 결국 가설검정해서 0.05보다 낫게 나와야한다
-
-
유의미한 상관관계 보일 가능성이 충분히 높다 = p 0.05보다 낫게 나올 가능성이 충분히 높다 = Power가 높다 = 베타가 낫다
- 가설
- α와β
- 효과 크기
-
귀무가설: 위험요소와 질병 간에 상관관계가 없다(차이가 없다) -
대립가설: 위험요소와 질병 간에 상관관계가 있다(차이가 있다)
- 이분형 결과변수(이벤트/질병발생이 있었는가 vs 없었는가)에 대해서 두 그룹(위험요소 노출 vs 노출안됨) 비교하는 경우를 생각해보자.
- p1: 위험요소 노출O그룹 = 실험군 에서 이벤트 있을 확률(risk)
- p0: 위험요소 노출X그룹 = 대조군에서 이벤트 있을 확률(risk)
-
귀무가설 :
차이가 없다=위험요소와 질병간 상관관계 없다=p1과 p0가 같다=OR = 1이다- cf) OR = 실험군오즈(p1/1-p1) / 대조군오즈(p0/1-p0)
- 대립가설 :
차이가 있다=위험요소와 질병간 상관관계 있다=p1과 p0가 다르다=OR != 1이다
-
귀무가설 :
제 1종 오류, 제 2종 오류
- 항상 귀무가설(H1)이 참이거나 거짓이거나 둘 중 하나다
- 무엇인지 모르지만 2가지 경우를 나누어서 본다.

- 무엇인지 모르지만 2가지 경우를 나누어서 본다.
- 다음엔 귀무가설을 기각할 수 도, 기각하지 못할 수 도 있다.

- y 귀무가설이 참인데 -> x 귀무가설을 기각하면 잘못된 것 ->
Type 1 Error- 귀무가설이 참인데, 귀무가설을 기각하는 오류
- y 대립가설이 참인데 -> x 귀무가설을 채택하면 잘못된 것 ->
Type 2 Error- 대립가설이 참인데, 귀무가설을 기각하지 못하는 오류
-
my H0/H1이 (고정)참일 떄 -> (고정)H0를 어떻게 했냐에 따라
- 같은 것 잘못(H0참 -> H0기각 : type1)
- 다른 것 잘못(H1참 -> H0기각 : type2)
- 2가지 오류를 나눠서 생각한다
- a =
제 1종오류의 최대허용치- a =
H0가 참인데 H0를기각할 오류의 최대허용치
- a =
- 유의수준이라고도 말한다.
- 보통 0.05을 사용한다
- 상황에 따라, 초반 연구(preliminary study)라서 조금 더 type 1 error를 높여
- 조금 더 높게 허용 = 0.05를 -> 0.1, 0.2, 0.25까지 올려서 사용하기도 한다.
- a를 낮추면 정확한 study가 되지만,
- 초반 연구 디자인/ 도움을 주기 위해서, 정확하진 않지만 a를 조금 높게 허용하기도 한다.
- a를 확 낮춰 정확한 study를 할 때는, 결과변수가 여러개일 때, 얻어걸리는 경우를 방지하기 위해 조금 더 엄격하게 연구하는 다중비교 (Multiple comparisons)에서, 다중성을 보정하기 위해 a를 낮춰 가설검정을 수행한다
- 상황에 따라, 초반 연구(preliminary study)라서 조금 더 type 1 error를 높여
- b =
제 2종오류- b =
H1대립가설이 참인데, H0를기각하지 못하는오류의 최대 허용치 - 만약, H1참인데, H0를 실제로 기각하고, H1을 채택하여 2종오류X ->
검정력이라고 함
- b =
- 검정력(power) = 1-b
- 보통 0.2로 많이 한다. 0.1로 할 때도 많다.
- b0.2 -> power는 0.8로 한다는 말
- b0.1 -> power를 0.9로 한다는 것
- 보통 0.2로 많이 한다. 0.1로 할 때도 많다.
- 위험요소 노출된 그룹과 노출 안된 그룹 간 결과변수 값의 차이
- 우리는 계속
이분형 결과변수를 보고 있음.- 이 경우, 두 그룹간의 event rate차이 =
p1과 p0의 차이가 효과크기기 된다. - 보통
p0(대조군 = 위험요소 노출X그룹의 질병발생율)은 보고가 되고 -
p0가 얼마일 때, p1 대신 아래 3가지 중 1가지를 제공한다면 -> 효과크기가 제공 되었다고 한다
- Absolute difference(=RD =attributable risk)
- p1 - p0 제시
- Relative change(OR, RR)
- OR o RR 제시
- 실험군(위험요소 노출된 그룹)의 이벤트 비율을 직접 언급
- p1을 직접 제시
- Absolute difference(=RD =attributable risk)
- 이 경우, 두 그룹간의 event rate차이 =
- 효과 크기 예제
- 대조군의 이벤트 비율 = 10%이라고 할 때, (
p0 제공)- p0 = 0.1
- 아래
네가지 중 하나를 같이 언급하면p1을 제시한 것과 같아서 ->effect size를 밝힐 수 있다.
-
p1= 25% = 0.25 -
absolute difference= 15% = 0.15- attributable risk =
p1-p0=p1- 0.1 = 0.15 - p1을 제시한 것과 동일
- attributable risk =
-
OR= 3.0- OR식을 p1으로 정리하여 recovery할 수 있다.

- OR식을 p1으로 정리하여 recovery할 수 있다.
-
RR= 2.5-
p1/p0= p1/0.1 = 2.5
-
-
- 대조군의 이벤트 비율 = 10%이라고 할 때, (
- α와 β, 효과 크기와 샘플 사이즈는 서로 얽혀있다
- 다른 모든 조건(샘플 사이즈, 효과 크기)이 동일한 경우,
- α가 커지면 β는 작아지고, α가 작아지면 β는 커진다
- type 1 error rate이 올라가면, type2 error rate이 내려간다
- type 1 error rate이 내려가면, type2 error rate이 올라간다
- α와 β는 서로 반대 방향으로 가는 관계이다.
- 효과 크기가 일정할 경우, 샘플 사이즈가 커질 수록 α와 β는 작아진다
- 샘플 사이즈가 커진다 = 데이터를 많이 모은다 = 정보가 많아진다 = 전체적으로 오류의 확률이 낮아진다.
- 샘플 사이즈가 일정할 경우, 효과 크기가 클 수록 α와 β는 작아진다
- 효과의 크기가 크면 클수록 적은량의 데이터로도 차이가 잘 보이게 된다. = 오류를 범할 확률이 낮아진다.
-
우리는 오류의 확률(α와 β)을 낮추기를 희망한다
- 효과 크기가 크거나, 샘플 사이즈가 커야 양쪽 오류의 확률을 낮출 수 있다
- 샘플 사이즈를 계산하려면
- a, b 및 효과 크기를 가정해야한다.
- 어떤 효과 크기를 가정할까?
- 실제
효과 크기를 XX일 때,type 1 error 확률이 a(알파)보다 낮고,power가 1-b(베타)보다 높은샘플사이즈는 YY이다.
- 실제
-
a는 0.05로 많이하고, b는 0.2로 많이 하는데, 효과 크기는 얼마로 가정해야할까?
- 임상적으로 중요한 효과크기를 가정하는 것이 좋다.
- 선행연구에 관측한 효과크기를 쓰기도 한다.
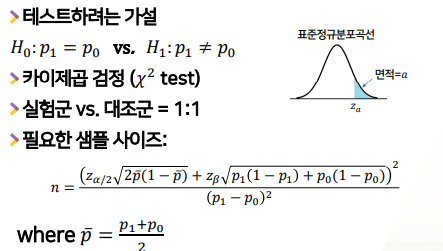
- 테스트 해야하는 가설이 아래와 같고
- 검정은 카이제곱 검정을 사용한다
- 실험군 vs 대조군은 1:1을 가정하지만
- RCT는 내가 모으는 거라 가정하지만, 관찰연구는 이미 숫자가 정해져있어서 1:1이 아님
- 1:1인 경우의 샘플사이즈 구하는 공식이 아래와 같이 나온다
- 공식 자체가 중요하진 않다. 소프트웨어로 계산하면 된다.
- 공식을 통해, 샘플 사이즈가 어떻게 효과크기/a/b에 영향을 받는지 확인한다.
- 효과크기 가정시 p1,p0가 가정되어있다.
- z sub a는 표준정규분포곡선에서 면적이 a가 되는 x값을 z sub a로 표시한다.
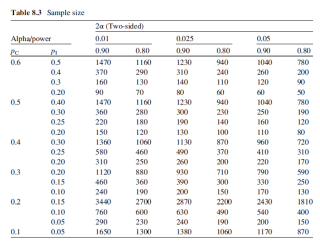
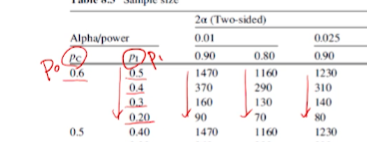
- 아래 표에서 Pc는 P0를, Pi는 P1을 의미한다.
- control / intervention
- control / intervention
-
세로축 방향으로 보자면, 가로축을 P0가 0.6일 때 고정시
- P1이 점점 작아진다. = 차이가 커진다 = 효과 크기가 커진다.
-
(차이가 잘보여)필요한 sample size는 줄어든다
-
(차이가 잘보여)필요한 sample size는 줄어든다
- P1이 점점 작아진다. = 차이가 커진다 = 효과 크기가 커진다.
-
가로축 방향으로 보자면
-
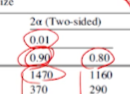
a(알파)값이 왼쪽으로 갈 수록 작아진다.(0.05, 0.025, 0.01)
-
1종 오류 확률을 낮춘다 = 오류가 낮은 테스트를 한다 = 데이터가 더 많이 필요하다
-
필요한 sample size가 커진다

-
필요한 sample size가 커진다
-
1종 오류 확률을 낮춘다 = 오류가 낮은 테스트를 한다 = 데이터가 더 많이 필요하다
-
0.90, 0.80은 power를 의미한다.
- power가 높으려면 더 많은 샘플사이즈를 필요로 할 것이다.
-
power가 높다 = 높은 확률로 실제 존재하는 두군간의 차이를 확인하고 싶다는 의미이므로 샘플 사이즈가 커야한다.
-
- (곡선 1개 고정) x축은 p0-p1을 의미한다.
- x축이 커질수록 효과크기가 커져, 샘플사이즈는 적게 필요하므로 점점 줄어드는 모양의 그래프가 나타난다
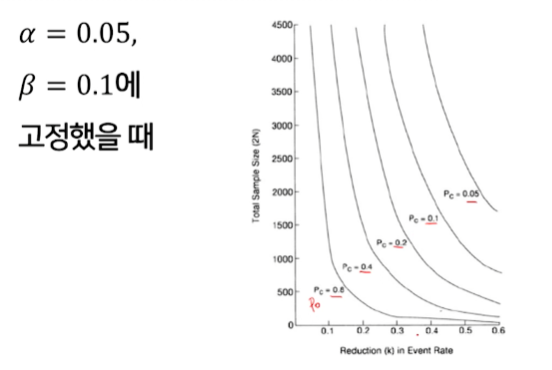
- x축이 커질수록 효과크기가 커져, 샘플사이즈는 적게 필요하므로 점점 줄어드는 모양의 그래프가 나타난다
- (x축 고정) 같은 효과크기에 대해 기울기 = Pc = P0 를 의미하므로
- 대조군의 event rate에 따라 필요로 하는 샘플 사이즈가 달라진다.
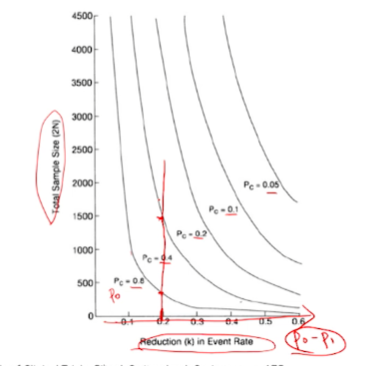
- 대조군의 event rate에 따라 필요로 하는 샘플 사이즈가 달라진다.
- 위에서 나타난 샘플사이즈 공식 + 그래프는
- 코호트, 크로스섹셔널, RCT에서는 적용가능하나
- Case-control study에서는 적용이 불가능하다.
- Case-Control의 경우
- 실험군-대조군이 존재하지 않고, case와 control이 있다.
- 이미 질병(event)이 발생한 vs 발생하지 않은 그룹이 있다.
- 각각 위험요소 노출이 얼마나 되었는지 확인하는 study이다.
- 그래서 p1과 p0의 정의가 위 코호트, 크로스섹셔널, RCT study와는 다르다.
- p1 : case 중 위험요소 노출확률
- p0 : control 중 위험요소 노출확률
- 샘플 사이즈 공식은 같으니 그대로 이용하면 된다.

- 샘플 사이즈 공식은 같으니 그대로 이용하면 된다.
- Cohort study나 RCT는 LTF가 생긴다.
- 일부는 이사가기도 하고, 일부는 연락두절 등 되서 끝까지 follow up 못한다.
- 이런 loss까지 반영하여 샘플 사이즈를 좀 더 크게 확보해야한다.
- LTF가 생기는 매너니즘이 ignorable하다고 가정한다?
- 중간에 환자를 사라지게 하는 여부 <-> outcome과 관계없다고 가정하는 것
-
이 가정을 이용해서 아래 공식을 통해 샘플 사이즈를 뻥튀기(inflate)한다
- N(*) = N / 1-R (R = LTF 비율)
- 원래 N보다 좀 더 크게 나온다.
- N(*) = N / 1-R (R = LTF 비율)
- 예) 연구에 필요한 환자 수가 100명이어야, 내가 significant level 0.05에서 80% power를 가지고 효과크기를 추정할 수 있다고 결론을 내린 상황 + 약 20%의 환자가 LTF될 것이라고 예측된다면?
- 100명 모아도 20%는 나가리 될 예정이니
- R = 0.2 -> N(*) = 100/(1-0.2) = 125명을 가지고 시작해야 나중에 100명을 얻을 수 있다.
- 관찰연구의 경우 이미 가용한 데이터가 정해져있어서 샘플 사이즈를 바꿀 수 없는 경우가 종종 있다
- 관찰 연구의 경우, 내가 쓸 수 있는 데이터 수가 정해져있다.
- observation study에서는 sample size 필요없다고 생각해서 논문을 투고했더니, sample size justification 해서 보내라고 피드백이 올 것이다.
- 그런데, 생각해보면, 관찰 연구라도 sample size justification가 필요하다.
- 이 연구가 애초에 될 연구/안될연구인지 체크하는 정도로 생각하면 된다.
- 그러나 이미 정해져있기 때문에 sample size라는 용어대신 power analysis라고 부르는데,
- 주어진 sample size + 내가 가정한 효과 크기를 가지고, 내가 몇프로의 power를 가질 수 있는지 계산하는 것이 된다.
- 지금까지는 a,b,효과크기 가정 -> sample size 계산
- 관찰연구 a,효과크기 가정, 주어진 sample size -> b를 계산하는 과정이다.
- 혹은 a, b, 주어진 sample size -> 효과 크기를 추정하는 minimum detectable diffrence도 있다.
- 최소 요만큼은 효과 크기를 dectect할 수 있다.
- 실제 효과크기가 요정도 이거나 이것보다 크면, power 80%로 두군간의 차이를 detect할 수 있다고 분석하기도 한다.
- 최소 요만큼은 효과 크기를 dectect할 수 있다.
- 관찰연구에서 sample size 계산 없이 분석만 했다면?
- 너무 작은 샘플 사이즈로 분석된 경우
- 상관관계를 보이는데에 실패했을 경우(p-value 0.05보다 높게 나옴) : 결과 해석이 어렵다
- 상관관계가 없어서 못 보인 것인지
- 상관관계가 있는데도 데이터 양이 적어서 못보이는 것인지 -> 결론을 내릴 수 없다.
- 상관관계를 보이는데에 운좋게 성공할 경우(p-value 0.05보다 낮게 나옴): 여러가지 분석 중 유의하게
나온 것만 골라서 보고한 것이 아닌지 의심받을 수 있다
- 샘플 사이즈가 이렇게 작은데 p-value가 0.05보다 낫게 나왔다면, 조작을 의심할 수 있다.
- 여러 위험요소 분석 후 얻어걸린 것을 보고한 것은 아닌지 research integrity(리서치 인테그러티) 의심됨.
- 상관관계를 보이는데에 실패했을 경우(p-value 0.05보다 높게 나옴) : 결과 해석이 어렵다
- 너무 작은 샘플 사이즈로 분석된 경우

- 대상 모집단: 병원 밖에서 심장 발작으로 구급대원의 치료를 받는 중 정맥주사로 epinephrine을 맞는 환자들
- 실험군 : usual treatment +
vasopressin - 대조군 : usual treatment +
placebo - 결과변수 : restoration of spontaneous circulation (ROSC) at any time during resuscitation
- 저절로 순환 및 호흡하는
좋은 event가 결과 변수 - ROSC가 비율이 높을 수록 좋은 것
- 저절로 순환 및 호흡하는
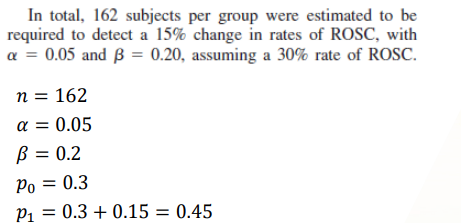
- 샘플사이즈 계산
- 대조군이 30% ROSC라고 가정했다
- 15%의 ROSC change를 detect하기 위해 필요한 sample size를 계산했다.
- 2군간의 ROSC 차이를 계산했다.
- RD = p1-p0 = 0.15라고 했다.
- 대조군에서는 0.30의 30% ROSC가 있을 것이라고 가정했고
- 실험군에서는 0.45의 45% ROSC가 있을 것이라고
효과 크기를 가정한 것이다.
- 이를 바탕으로 계산했더니 162명의 sample size가 필요하다는 결론을 얻었다.
# - 기본 내장된 함수 power.prop.test()를 쓰면 된다.
?power.prop.test
# power.prop.test(n = NULL, p1 = NULL, p2 = NULL,
# sig.level = 0.05, #알파
# power = NULL, # 1-베타
# alternative = c("two.sided", "one.sided"),
# strict = FALSE, tol = .Machine$double.eps^0.25)
# - 여기서 대조군/실험군이 어떤 것인지는 중요하지 않음.
# 이분형 결과변수의 경우, 단측검정이 불가능하다
# -> 양측 검정으로만 해야한다.
# -> 카이제곱 검정을 하기 때문에 그렇다.
power.prop.test(
p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
power = 0.8, # b=0.2
alternative = "two.sided"
)
# 162.3 -> 올림해서 163명으로 해도된다.
# 주의할 점은, 각 군에서 필요한 sample size다.
# NOTE: n is number in *each* group
# 1) power 계산
# 2) detect할 수 있는 효과크기 (minimum detetable diffrence) 계산이 가능하다.
# 1) 고정된 sample size + 가정한 효과크기 -> power를 계산한다
# - power를 제외하고 다른 것들을 채워주면 된다.
power.prop.test(
p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
# power = 0.8, # b=0.2
n = 200,
alternative = "two.sided"
)
# power = 0.8754082
# -> sample size 200명을 가지고 계산하면, power가 87% 정도가 생긴다
# -> 효과크기는 p1,p0에 의해 결정이 되므로
# -> 1가지는 고정해서 채워넣어야한다.
# -> 문제에서는 대조군의 ROCS rate가 30%라 했으니, 0.3을 살려놓고 돌려보자.
# --> p1을 계산시킨다.
power.prop.test(
# p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
power = 0.8, # b=0.2
n = 200,
alternative = "two.sided"
)
# p1 = 0.1806459
# 대조군에서 30% ROCS를 가정할 시,
# -> 치료군에서 ROCS는 18%나 이것보다 작게 나와서 -> 두군간의 차이가 커지면
# --> power 80%를 가지고 sig 0.05에서 두군간의 차이를 detect할 수 있다.
# 주의점
# -> 치료군의 ROCS가 높아질 것으로 예상하고 있다( good event라서)
# -> 즉, p1이 p2인0.3보다 높아질 것이라고 기대를 했는데, 더 낮게 나왔다
# --> 더 높은 확률을 산출하도록 바꿔야한다
# p1자리에 0.3을 넣어주자.
power.prop.test(
p1 = 0.3,
# p2 = 0.3,
sig.level = 0.05,
power = 0.8, # b=0.2
n = 200,
alternative = "two.sided"
)
# p2 = 0.4346572
# 즉, 치료군의 실제 ROCS비율이 43.5%이거나 더 높을 경우,
# power 80%를 가지고 sig 0.05에서 두군간의 차이를 detect할 수 있다.
두가지 수술방법의 합병증 비율을 비교하는 임상시험을 하려고 한다. 수술방법 A는 15%의 환자에게 서 합병증이 발생할 것이고 수술방법 B는 5%의 환자에게서 합병증이 발생할 것으로 예상되는 상황 이라고 하자. 두 수술방법의 합병증 비율에 차이가 있다는 것을 유의수준 0.05에서 80% 파워(검정력) 으로 보이려면, 총 몇 명의 환자를 모집해야 하는가? (단, lost-to-follow up이나 결측은 고려하지 않는 다. 계산을 위한 R 코드와 출력결과를 답안에 포함한다.)
- n = 200 +200
- α(유의수준) = 0.05
- β = ?
- p0 = 0.15
- p1 = 0.05
# 1) power 계산
# 2) detect할 수 있는 효과크기 (minimum detetable diffrence) 계산이 가능하다.
# 1) 고정된 sample size + 가정한 효과크기 -> power를 계산한다
power.prop.test(
p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
n = 400,
alternative = "two.sided"
)
두가지 수술방법의 합병증 비율을 비교하는 후향적 연구를 하려고 한다. 아직 데이터를 분석하기 전 이지만, 수술방법 A는 15%의 환자에게서 합병증이 발생할 것이고 수술방법 B는 5%의 환자에게서 합병증이 발생할 것으로 예상되는 상황이라고 하자. 연구자가 근무하는 병원에서 A수술을 받은 환자 200명, B수술을 받은 환자 200명, 이렇게 총 400명이 연구 참여에 동의하여 데이터를 수집할 수 있었 다. 두 수술방법의 합병증 비율에 차이가 있다는 것을 유의수준 0.05에서 보이기 위한 파워(검정력)는 얼마인가? (단, lost-to-follow up이나 결측은 고려하지 않는다. 계산을 위한 R 코드와 출력결과를 답안 에 포함한다.)
- n = ?
- α(유의수준) = 0.05
- β = 0.2
- p0 = 0.15
- p1 = 0.05
# - power 계산
power.prop.test(
p1 = 0.45,
p2 = 0.3,
sig.level = 0.05,
n = 400,
alternative = "two.sided"
)
- Propensity score matching을 사용한 연구결과를 보고하는 논문 1편을 조사하여 다음에 답하시오.
- a. 연구질문(research question)이 무엇인가?
- b. 연구에 사용한 결과변수의 정의가 무엇인가?
- c. 연구에서 비교한 그룹이 무엇인가?
- d. Propensity score 분석 방법을 사용한 이유가 무엇인가?
- e. Propensity score를 어떤 방법으로 추정하였는가?
- f. 매칭된 데이터의 밸런스를 어떻게 평가하였는가?
- g. 매칭 이후 분석은 매칭된 데이터라는 점을 반영하였는가? 반영하였다면 어떤 방법으로 반영하였는가?
- h. 연구의 결론이 무엇인가?
-
누구 샘플 사이즈는 적게 가져가도 충분한 power를 가지길 원한다.
-
연속형 결과변수를 사용한다
- 이분형 결과변수에 비해 훨씬 더 많은 정보를 가지고 있다.
- 잘 생각해보면, 연속형 변수를 자르면 이분형 변수가 되기 때문
- 이분형 결과변수로 바뀐 순간, cut off보다 높다? 낮다? 의 정보만 가지게 된다. (정확한 값은 모르게 된다.)
- 같은 샘플 사이즈를 가지더라도 더 높은 power를 가지게 된다.
- 같은 power를 달성하는 데에도 더 적은 샘플 사이즈가 필요로 된다.
- 이분형 결과변수에 비해 훨씬 더 많은 정보를 가지고 있다.
- (어쩔 수 없이)이분형 결과변수를 사용할 경우, (되도록이면) 이벤트가 발생하는 확률이 높은 결과변수를 사용한다. (up to 0.5)
- 확률이 0.5근처에 있을수록 더 좋다
- 0이나 1에 가까울수록 샘플사이즈가 더 많이 필요로 된다.
- 이벤트 발생확률이 높은 고위험군 환자를 연구
- 추적관찰 기간을 늘린다
- 이벤트가 발생할 확률을 늘인다.
- 확률이 0.5근처에 있을수록 더 좋다
- 지금까지는 가설검정 기반(그룹간 비교)의 샘플사이즈 계산만 봐왔다.
- 하지만, 임상연구 초반에서는 현상만 설명하는 descriptive study를 하게 된다.
- 검정이 주목적이 아닌 추정이 주목적이 된다.
- 예) 우리나라 당뇨병 유병률이 몇퍼센트인가?
- 추정이 중요하지 그룹간 비교가 중요하지 않다.
- 이런 경우, 추정의 precision이 샘플 사이즈 선정의 기준이 된다.
- 예) 우리나라 당뇨병 유병률이 몇퍼센트인가?
- 추정량에 대한 95% 신뢰구간을 구할 때
- 신뢰구간의 폭이 좁을 수록 -> 내가 더 추정치에 대해 자신있게 된다.
- 검정이 주목적이 아닌 추정이 주목적이 된다.
- sample size와 신뢰구간의 폭의 관계를 가지고 sample size justicfication을 할 수 있게 된다.
- sample size가 정해진 경우, 이 추정량에 대한 95%의 신뢰구간이 얼마가 될 것으로 추정이 된다.로 justify할 수 있다.
- 반대로, 신뢰구간의 폭이 얼마가 되길 원하는데, 필요한 sample size는 n명이다. 그래서 우리는 n명의 데이터를 모았다.로 justify할 수 있다.
- 중요한 confounder가 있을 경우, confounder를 반드시 모형에 포함시킨 Multivariable analysis를 실시해야한다.
- 이럴 경우 모델의 complexity에 걸맞는 sample size를 사용해줘야한다.
-
모델이 변수가 많아서 복잡한데, sample size가 작을 경우,
overfitting이 발생한다.- 모델이 작은 수의 데이터만 설명하고, 비슷한 데이터는 설명 못하게 된다.
- 이분형 결과변수인 경우 사용하는 Multivariable logistic regression의 경우
-
rule of sum으로서
15×[독립변수의 개수]가 2개 그룹 중작은 그룹의 환자 수가 최소 이정도는 되어야한다- 주로 event발생하는 적은 수의 환자 수 = 15 x 독립변수의 개수
- 만약, 환자 수가 이것보다 작으면, 환자 수에 비해 모델이 너무 복잡해서 overfitting이 발생하는 것으로 본다.
- 주로 event발생하는 적은 수의 환자 수 = 15 x 독립변수의 개수
-
rule of sum으로서
- 이미 데이터 분석을 마쳐서 결론을 얻고, OR를 구하고 x와 y의 상관관계를 구한 상태라고 할 때
- 여기서 구한 OR + 관측한 sample size를 가지고 -> power를 몇퍼센트 가졌는지 계산하는 것이다.
- 임상저널의 리뷰어가 하라고 하는 경우가 종종 있다.
- 하지만, 이 분석은 통계적으로 타당하지 않으며, 결과가 정해져있기 때문에필요없는 분석이다
- 여기서 구한 OR + 관측한 sample size를 가지고 -> power를 몇퍼센트 가졌는지 계산하는 것이다.
-
필요없고 하면 안되는 분석이다. 왜?
- 내가 관측한 효과크기에 완전히 의존하는 분석이기 때문이다.
- 내가 관측한 효과크기가 유의하면 power가 크게 나온다.
- 내가 관측한 효과크기가 유의하지 않으면 power도 부족하게 나오기 때문이다.
- 즉, 내가 계산한 p-value와 Post-hoc power analysis로 계산한 power값이 완전히 1:1대응이 된다.
- p-value이상의 정보를 제공해주지 못함.
- 이미 일어난 사건에 대한 확률을 계산하는 것이라 통계적으로 말이 안되는 분석이다.
- 내가 관측한 효과크기에 완전히 의존하는 분석이기 때문이다.
- 이 계산을 하지 않겠다 대응하면 된다.
- 한계점 : 샘플 사이즈 계산은 overlay되어있다.
- 사실은 많은 가정 하에 이뤄지는 예측일 뿐이다
- 우리는 효과크기를 계산해야하는데, 그 효과크기를 모르기 때문에 연구하는 건데, 모르는 값을 가정해놓고 구하는 sample size는 틀릴 가능성이 높다.
- 쉽게 어긋날 수 있다
- 쉽게 ‘조작’할 수 있다
- a, b, test종류, 양측검정vs단측검정, samplesize에 비해 바뀌기 때문에, 맞춰서 꾸미기도 쉽다.
- all-or-nothing의 결정을 내려선 안된다
- sample size 구한 것을 절대적으로 생각해선 안된다.
- 높은 확률로 성공적인 연구를 수행하기 위하여 주어진 정보를 바탕으로 최선의 결정을 내리기 위한 노력이라고 이해해야한다
- 유의미한 상관관계를 보일 가능성을 충분히 확보하기 위하여 연구 시작 전 샘플 사이즈를 계산한다
- α는 제1종 오류 확률의 최대허용치이고, β는 제2종 오류 확률이다. 파워는 1-β이다.
- 이분형 결과변수의 경우 효과크기는 두 그룹간 event rate의 차이로 결정된다
- 원하는 α와 β값과 어떤 효과 크기를 가정하면, 필요한 샘플 사이즈를 계산할 수 있다
- 가설검정이 주요 검정이 아닌 경우 신뢰구간의 폭을 기준으로 샘플 사이즈를 계산할 수 있다
- Multivariable logistic regression의 경우, 이분형 결과변수로 나누어지는 두 개의 그룹 중 작은 그룹의 환자 수가 적어도 15×[독립변수의 개수] 정도 되어야 한다
- Post-hoc power analysis는 통계적으로 타당하지 않으며, 결과가 정해져 있기 때문에 필요없는 분석이다
02 다음 중 임상연구의 샘플 사이즈에 대한 설명으로 맞는 것은?
-
다른 모든 조건을 같게 유지하면서 유의수준 α를 감소시키면, 필요한 샘플 사이즈도 작아진다.
-
다른 모든 조건을 같게 유지하면서 파워를 높이면, 필요한 샘플 사이즈는 작아진다.
-
이분형 결과변수일 때 다른 모든 조건을 같게 유지하면서 실험군과 대조군의 이벤트 확률의 차이를 크게 하면, 필요한 샘플 사이즈도 작아진다.
-
연구에 필요한 환자 수가 100명이고, 연구기간 중 약 20%의 환자가 lost to follow up될 것이라고 예상된다면, 100명 + 20명 = 120명을 모집해야 한다.
- 연구에 필요한 환자 수가 100명이고 약 20%의 환자가 LTF된다고 예상된다면, 100/(1-0.2) = 125명을 모집해야한다.
- 정답 : 3
- 해설 : 유의수준을 감소시키거나 파워를 높인다는 것은 각각 제1종의 오류, 제2종의 오류를 줄인다는 뜻이므로, 필요한 샘플 사이즈가 늘어난다. 실험군과 대조군의 이벤트 확률 차이가 커지면 두 군간의 차이를 detect하기 더 쉬워지므로, 필요한 샘플 사이즈가 작아진다.