의연방13) 메타분석3(revman 실습)
Meta Analysis과 Revman 5 실습



📜 제목으로 보기✏마지막 댓글로
RevMan5 설치
-
구글에서
Review Manager를 검색하거나 아래 사이트를 통해 가서 설치한다. -
Revman 5 download >
For Academic use- 아래 항목 작성
- 아래 항목 작성
-
실행시
Non-Cochrane mode로 실행할 것(only 메타분석만 시행)-
Standard mode는 코크란에 SR이나 메타분석 출판을 위한 목적으로 나중에 설정에서 바꿔주면 된다.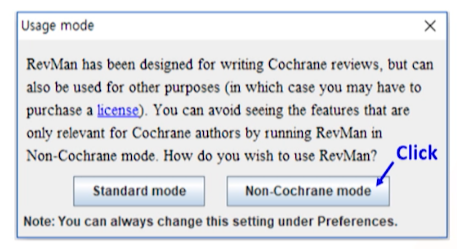
-
-
create new Review > Type of Review 선택(기본:intervention review)
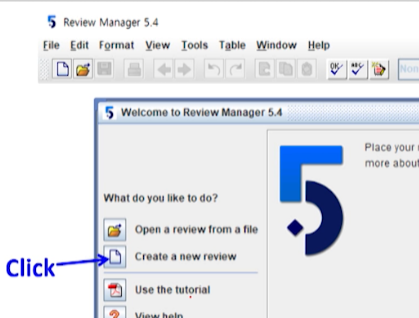
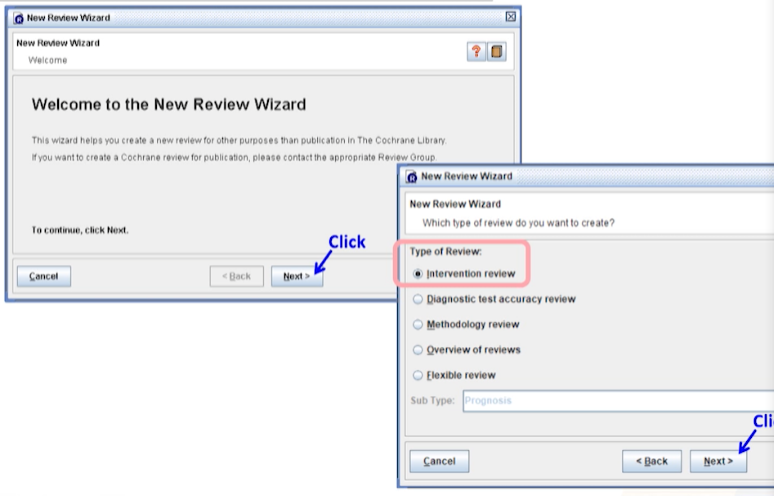
-
Title은 작성안하고 넘어가도 되고 작성해도 된다.
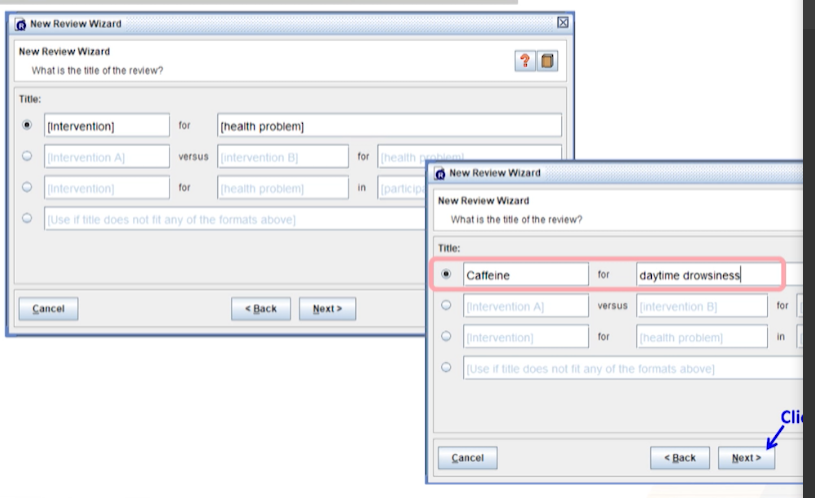
-
Stage만 유일하게 Protocol ->Full review로 변경해준다.- 메타분석은 SR에 포함된 것으로서 프로토콜만으로는 할 수 없다
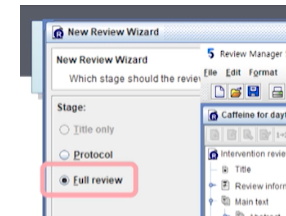
- 메타분석은 SR에 포함된 것으로서 프로토콜만으로는 할 수 없다
-
Outline Pane으로 작업 수행/ Content Pane이 Output창으로 생각하면 된다.
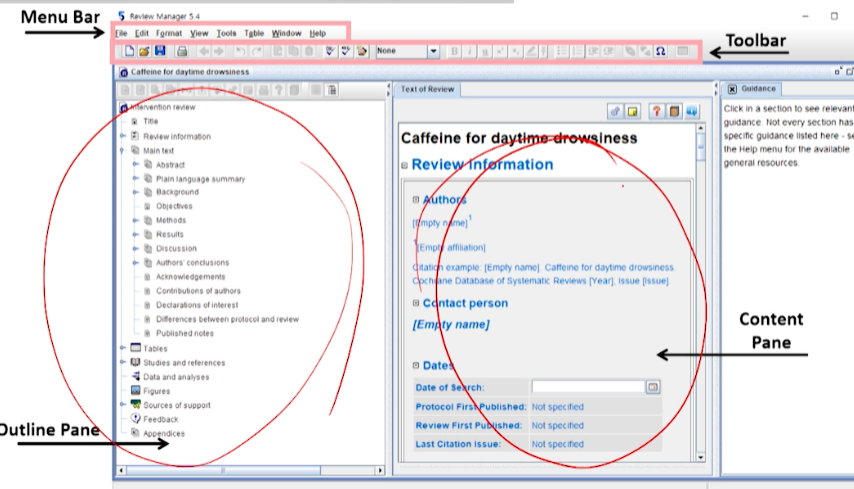
RevMan5 사용법
Example Data
- 사용하기 전에 데이터가 있어야한다
-
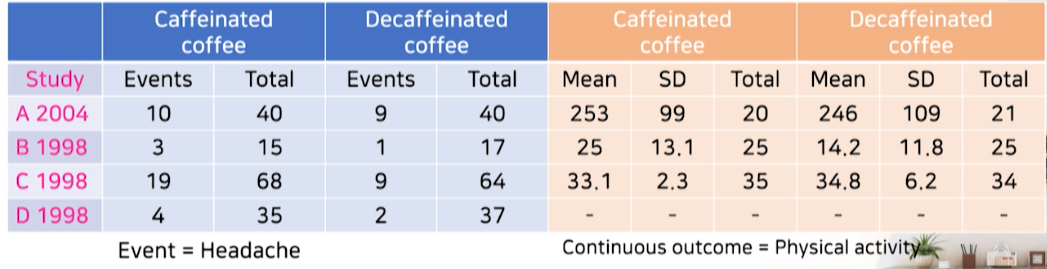
가상으로 만든 2가지 outcome에 대한 4가지 연구들의 데이터를 확인해보자.
- Headache(binary type outcome)
- Physical activity(Continuous outcome)
-
caffeine 커피가 두통을 더 많이 일으킬 것이다로 검색시 4가지 연구
- 각 군마다 환자수(total)와 두통발생수(events)를 조사한다
-
binarytype의 outcome인 경우:각 군당 n수와 event수 2가지 조사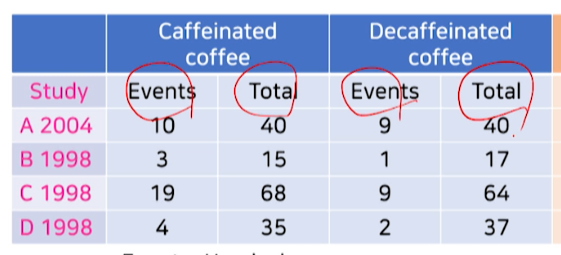
-
- 각 군마다 환자수(total)와 두통발생수(events)를 조사한다
-
caffeine과 decaffeine 커피에 대해 생리 활동이 다를 것이다 검색시 3가지 연구
연속형type의 outcome이므로각 군당 n수 + Mean + Sd 3가지 조사
Add study
- 임상연구 시작시, 각 환자마다 subject_id를 생성하듯이
- 각 study에 대한
Study ID를 생성한 후, 관련된 개별 연구(문헌)들을 추가함.- Cochrane review의 경우 추천하는 규칙이 따로 있다. ->
제 1저자 + 출판연도- Study ID : the name of the lead author + the year of publication (예: Stephens 1996)
- 만일 동일한 저자명과 연도를 가지는 study가 하나 이상 존재하면 알파벳 문자 추가
- 예 : Stephens 1996
a, Stephens 1996b
- 예 : Stephens 1996
- Cochrane review의 경우 추천하는 규칙이 따로 있다. ->
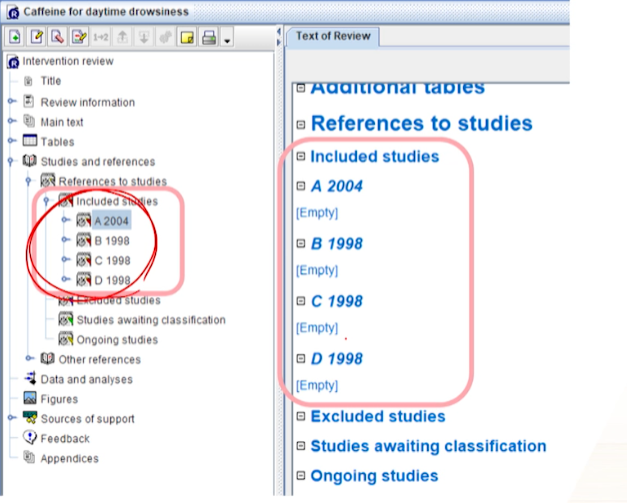
- outline pane에서 Studies and references > references to studies > included studies >
RMB > Add study를 클릭해서 Study_id들을 추가해줘야한다.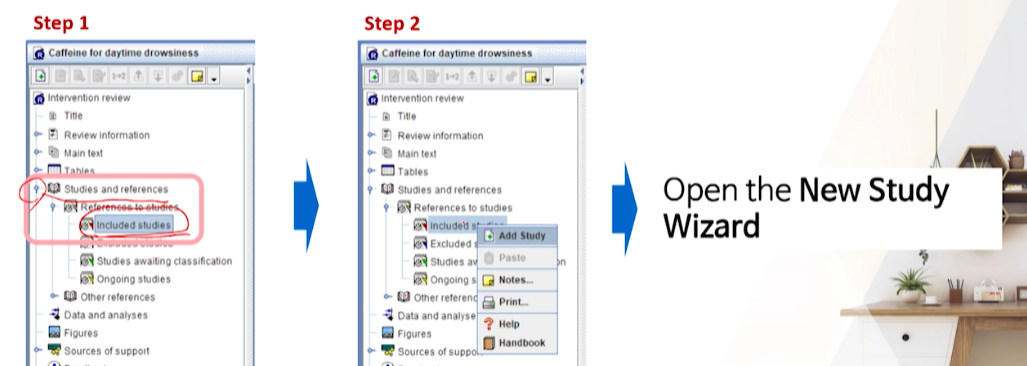
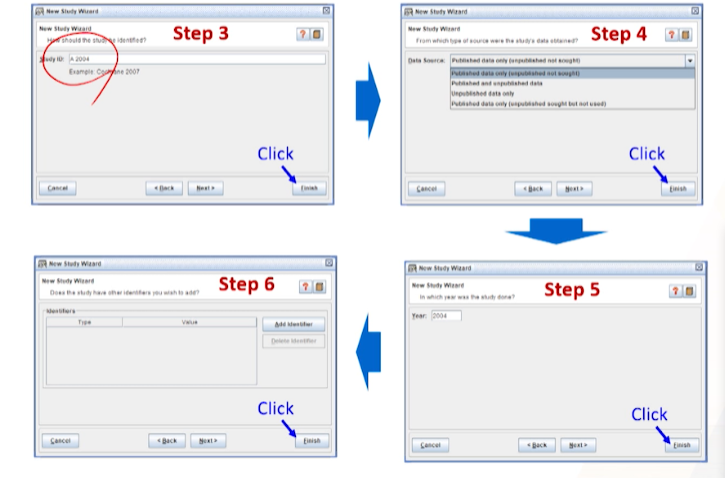
- 오타: next버튼을 마지막전까지- 각 study들을 추가하다가 맨 마지막 study의 경우
Nothing을 선택해서 Finish한다.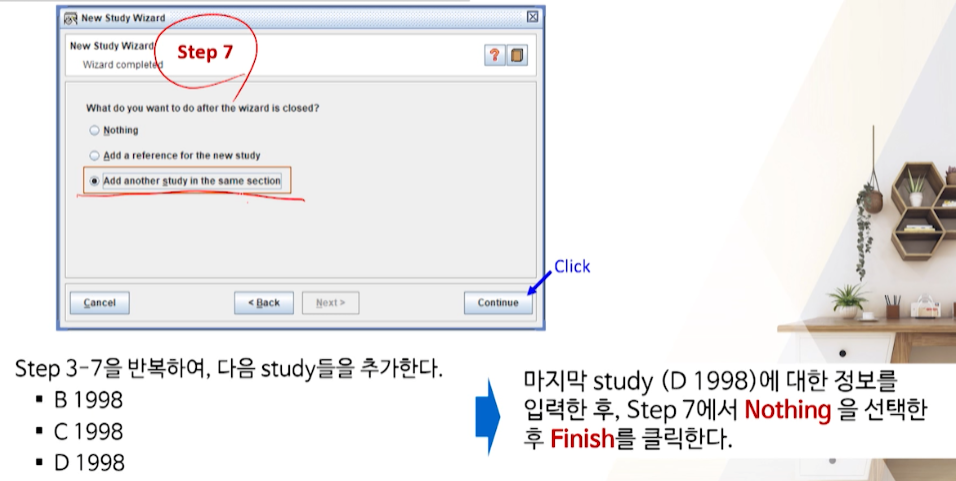
- 각 study들을 추가하다가 맨 마지막 study의 경우
Data 입력 및 분석
- Step 1. Intervention과 control간의
비교 정보를 입력한다.- ex) Caffeinated coffee vs. decaffeinated coffee
- Step 2. 각 비교에 대해, 측정된
outcome 정보를 입력한다.- ex) Dichotomous outcome: Headache
- outline pane에서
Data and analyses를 선택 >RMB > Add comparison- 여기서부터 메타분석이 시작된다.
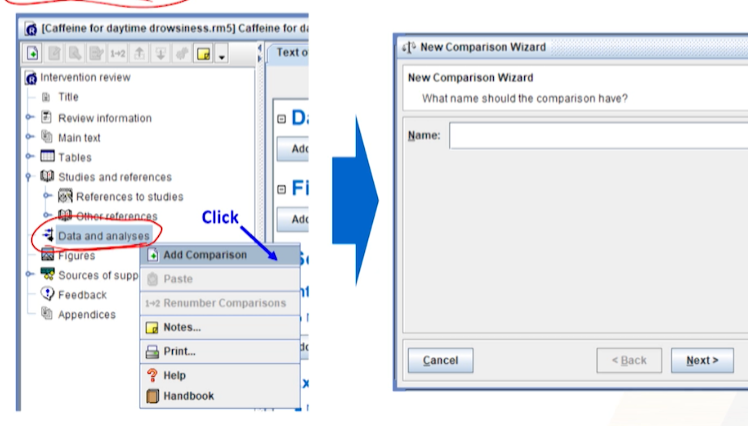
- 여기서부터 메타분석이 시작된다.
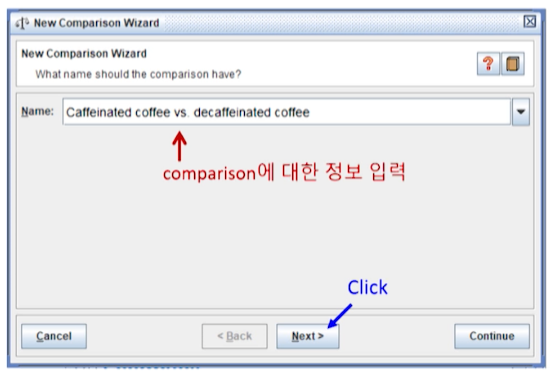
- Name에
Caffeinated coffee vs. decaffeinated coffee을 입력 한 후 Next를 클릭한다
-
2번째에 있는
Add an outcome under the new comparison을 선택한 후, Continue를 클릭한다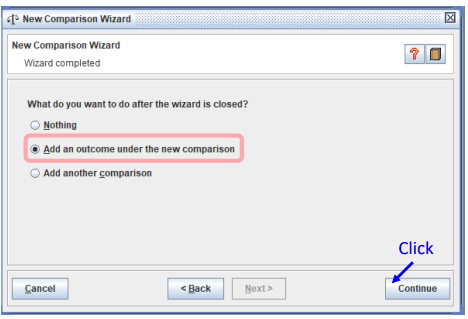
-
outcome 종류에 따라
Data Type을 선택한다.- binary(두통) ->
Dichotomous - 연속형(생리 활동) ->
Continuous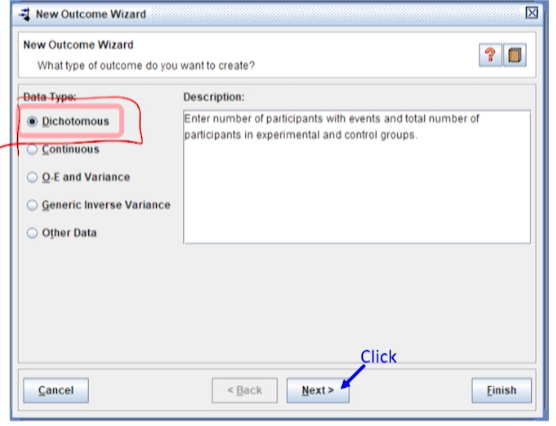
- binary(두통) ->
-
Name에는 Outcome명칭을 쓴다. ‘Headache’을 입력한다. -
Group Label 1에 ‘Caffeinated coffee’를, Group Label 2에 ‘Decaffeinated coffee’를 입력한 후, Next를 클릭한다.
- 각 군의 이름을 쓰는 것이다. 기본적으로 중재군을 group 1, 대조군을 group 2로 쓴다.
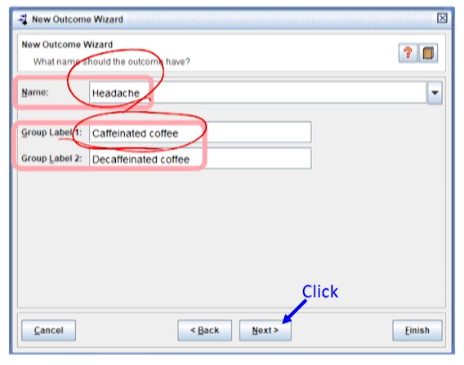
- 각 군의 이름을 쓰는 것이다. 기본적으로 중재군을 group 1, 대조군을 group 2로 쓴다.
-
Outcome에 대한 statistical method를 선택한다.
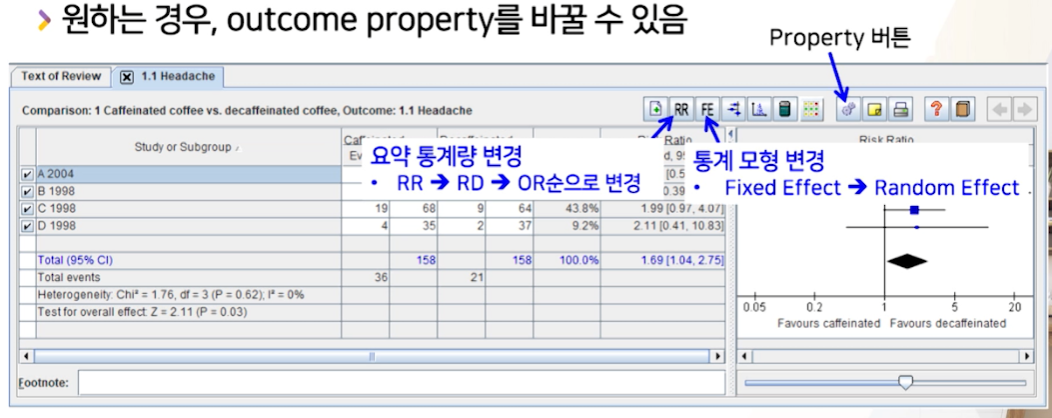
- Statistical Method (가중치 부여 방법) :
Mantel-Haenszel-
Inverse Variance는total n수만 의지하는 것 Mantel-Haenszel는total n수 + event수까지 반영하는 것으로binary(Dichotomous) outcome에 추천됨.
-
- Analysis Model (통계 모형) :
Fixed effects- 아직 이질성에 대한 것을 모르므로
기본으로 Fiexed effects모형으로 선택함
- 아직 이질성에 대한 것을 모르므로
- Effect Measure (요약 통계량) :
Risk Ratio- 연구가 RCT나 코호트(전향적)인 경우, RR을 이용함
- 그외 OR?!
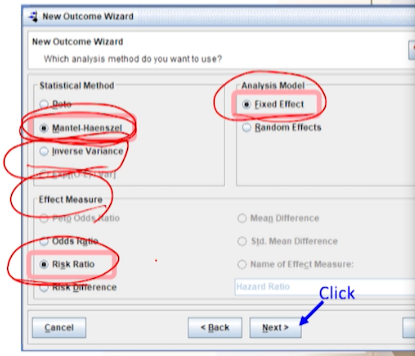
- Statistical Method (가중치 부여 방법) :
-
메타분석 결과 세부사항 -> 신뢰구간 95%로 둔다.
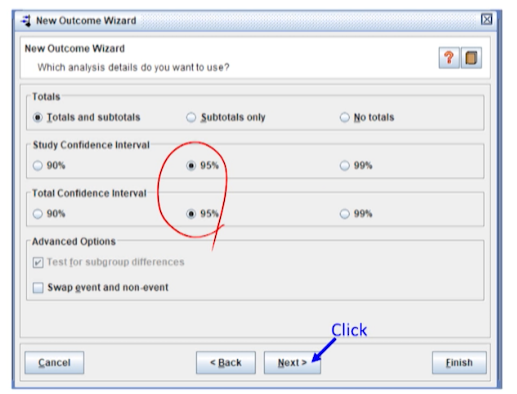
-
메타분석 그래프에 대한 세부사항 정보를 입력한다.
-
outcome이 안좋은 것인 경우, (ex> 두통) ->
RR가 1을 넘길 경우 안좋은 것. 1이하일 경우 좋은 것인 상황이라면-
그래프 왼쪽= RR이 1보다 낮은 것:안좋은 결과를 일으키는 군의 이름을 입력 -
그래프 오른쪽= RR이 1보다 높은 것:좋은 결과를 일으키는 군의 이름을 입력 - scale은 나중에 조정하면 되서 default로 준다.
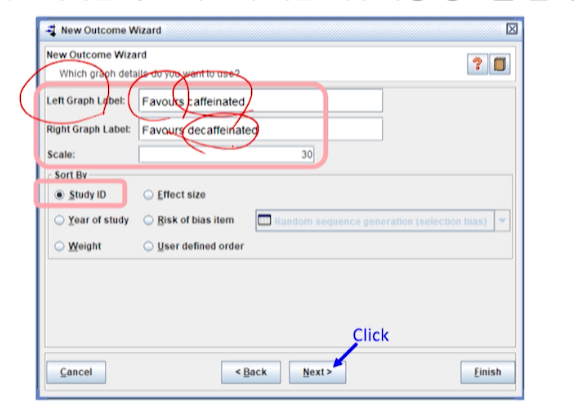
-
-
outcome이 안좋은 것인 경우, (ex> 두통) ->
-
raw data를 입력하기 위해
Add study data for the new outcome을 선택한다.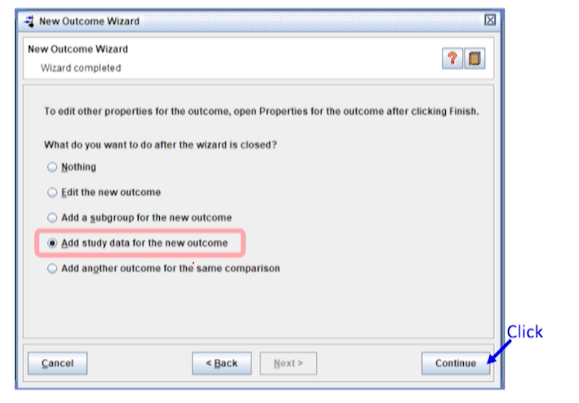
-
Included Studies(SR대상) 중 에서메타분석에 포함될 study들만 선택한다.- Ctrl or Shift key를 누른 상태에서 마우스로 해당되는 논문들을 직접 선택
- or year를 이용한 Filter 기능을 이용
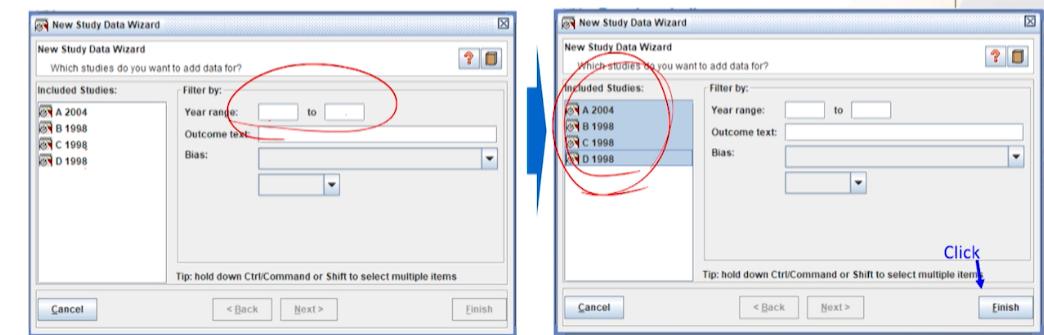
- 데이터 입력칸만 하얀색으로 활성화 된다.
- Headache outcome을 입력하기 위한 data table이 생성됨
- Dichotomous outcome의 경우,
- number of events (= number of headache) 및 total number (= number of participants or patients)을 입력해야 함.
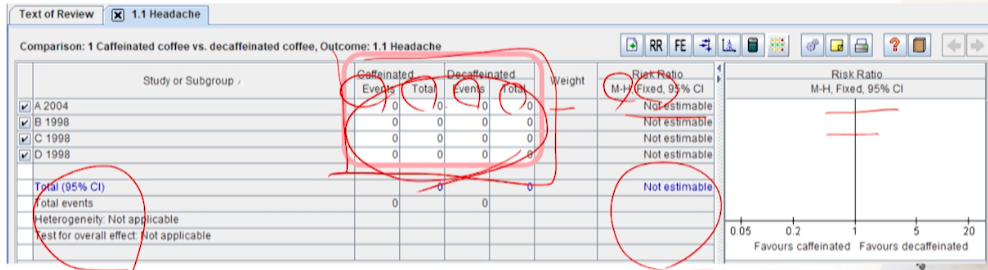
- number of events (= number of headache) 및 total number (= number of participants or patients)을 입력해야 함.
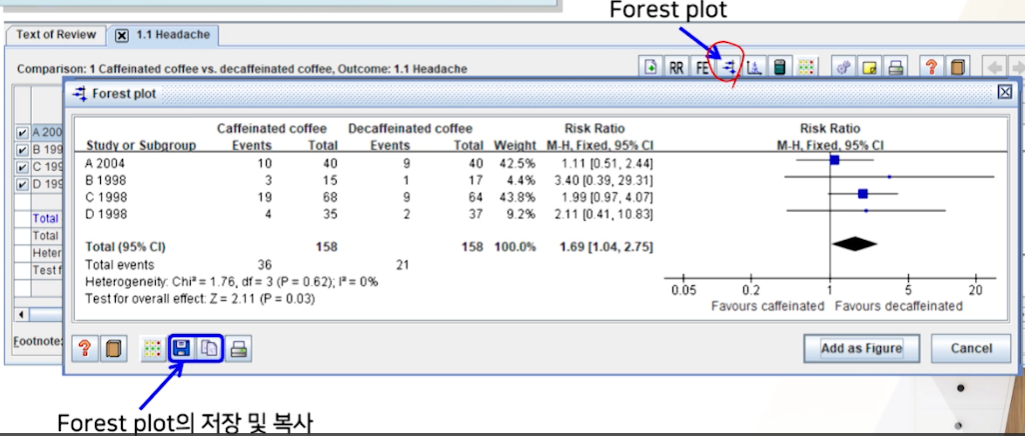
메타분석결과 해석
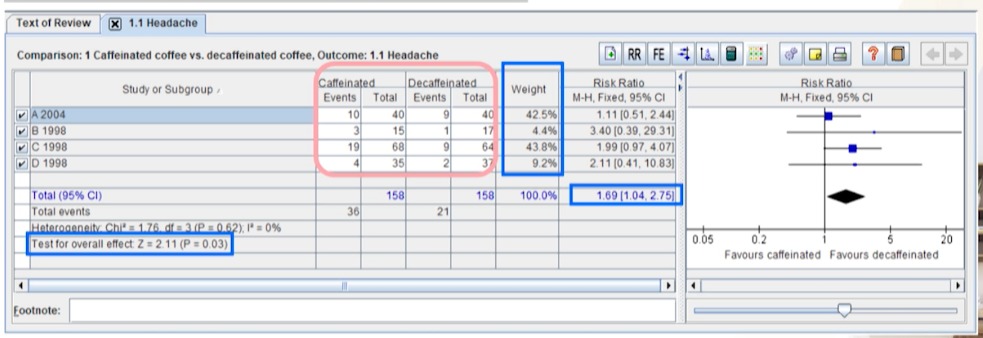
- 3번째, 1번째 study가 환자수도 많고, event수도 많아서 weight가 높게 잡힌다.
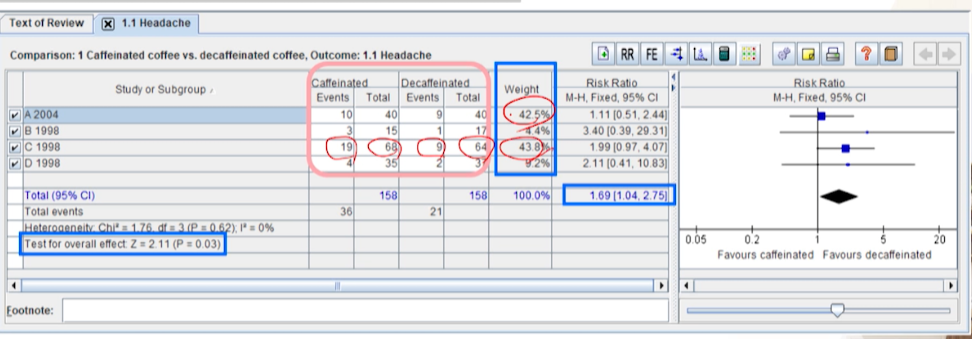
- 모든 스터디들이 RR이 1을 넘었다 -> outcome headache -> 중재군(카페인커피)가 대조군(디카페인 커피)보다는 두통을 좀 더 일으키는 것 같다고 해석한다.
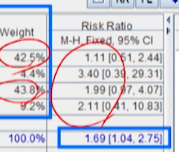
- 그런데, 개별 결과들은 신뢰구간이 모두 1을 포함한다
- 개별 스터디들은 통계적으로 유의하지 않다고 해석한다.
- 그러나, 통합된 결과는 RR이 1을 넘으면서, 신뢰구간이 1을 포함하지 않아 통계적으로 유의하다
-
카페인커피가 디카페인커피보다 두통을 1.69배 더 일으킨다.(통계적의 유의)

-
카페인커피가 디카페인커피보다 두통을 1.69배 더 일으킨다.(통계적의 유의)
- 메타분석의 이유
- 각각의 study들은 통계적으로 유의하지 않으나, 방향성은 카페인이 더 두통을 일으킨다고 나오고 시그널을 주고 있다.
- 통합된 결과를 봐야한다.

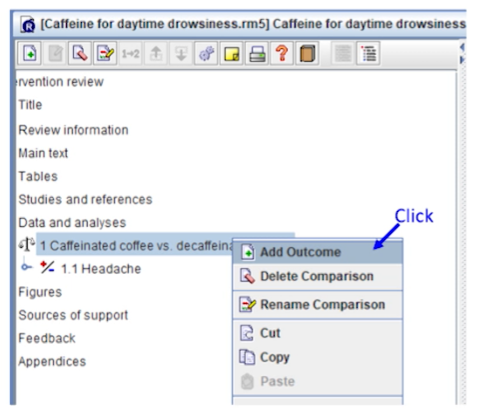
Continuous outcome의 추가
- 추가적인 outcome이 존재할 때 추가해주면 된다.
-
기존 분석의 중재군vs대조군을 그대로 사용할 것이라면
Caffeinated coffee vs. decaffeinated coffee comparison에서RMB > Add Outcome을 클릭한다- 군이 바뀌면 새롭게 해야함.
- 군이 바뀌면 새롭게 해야함.
-
Data type 중
Continuous을 선택한 후, Next를 클릭한다.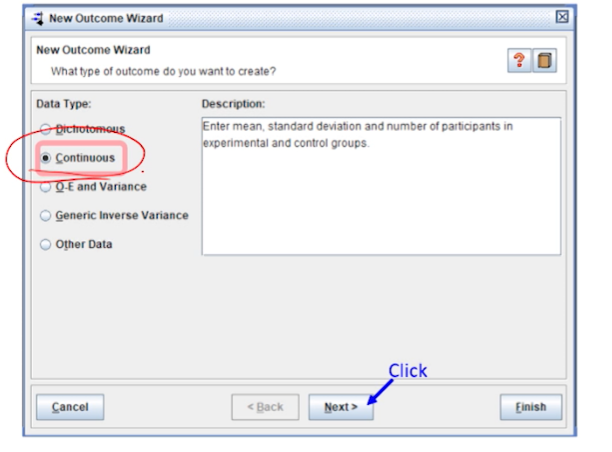
-
Outcome 이름으로
Physical activity에 이라고 입력한 후, Next를 클릭한다- 기존 군은 그대로 사용한다.
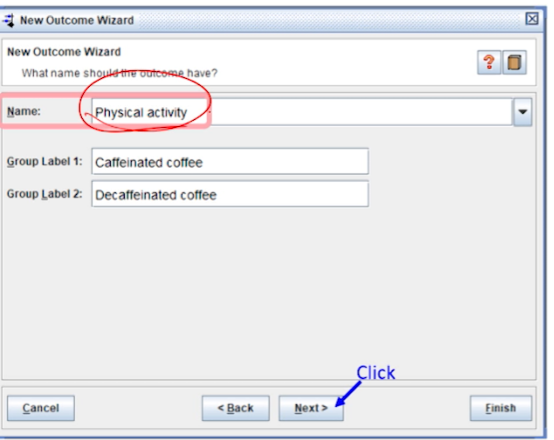
- 기존 군은 그대로 사용한다.
-
가중치 부여 방법, 통계 모형, 요약 통계량 등을 선택한다.
-
연속형 outcome에 대한 가중치부여방법(
statistical method)는 1가지Inverse Variance밖이다.- 표본수만 근거한 가중치 부여방법(각 그룹의 환자수가 많은 것에 가중치 많이 부여)
- 분석모형은 Fixed로 일단 시작
- Effect Measure에서는 측정단위(scale)가 동일하면 MD / 다르면 표준화시키는 Std MD를 사용한다.
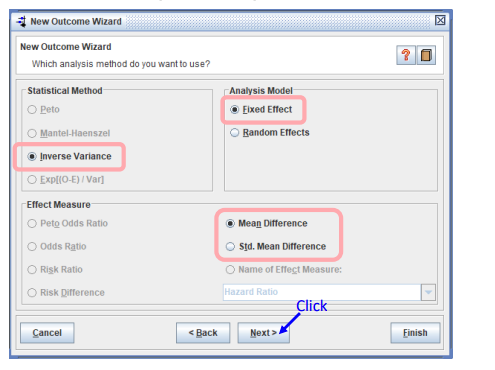
-
연속형 outcome에 대한 가중치부여방법(
-
결과 및 그래프에 대한 세부사항은 앞과 동일하다. 마지막 finish전에 데이터를 입력하는
add study data for the new outcome을 선택하고 finish해준다.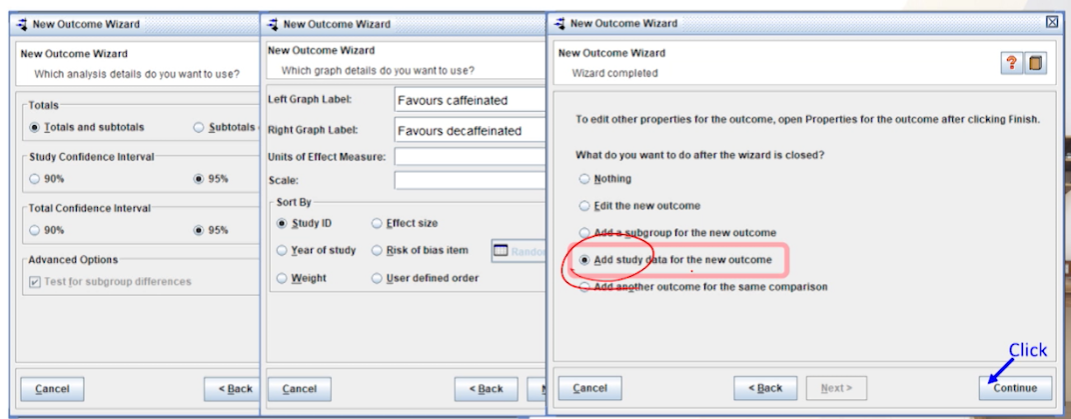
-
이미 추가된 4개의 study중에 3개 study에만 데이터가 존재하므로 3개만 선택한다.
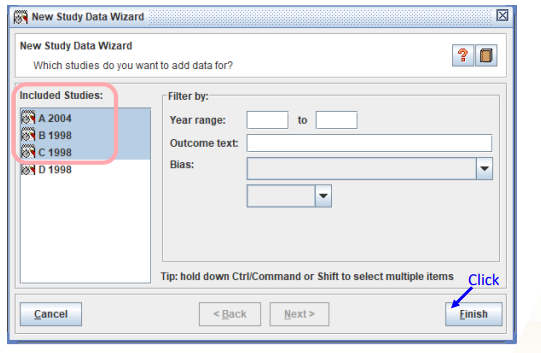
-
데이터를 입력할 땐, 칼럼 순서를 잘 확인하자(환자수가 제일 마지막)
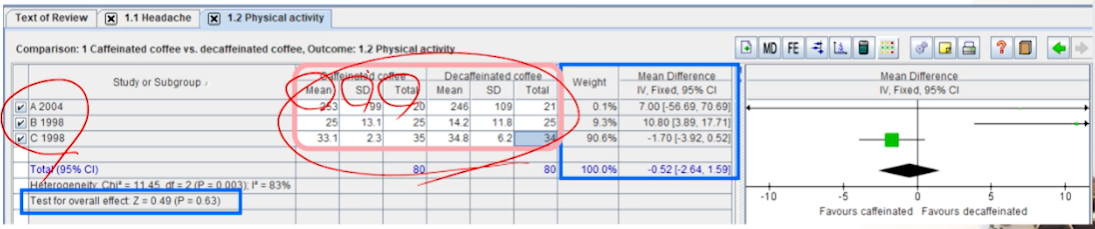
-
결과 확인
- 3번째 연구가
가중치가 제일 크다.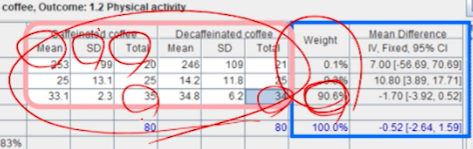
- MD에서는 0을 포함하지 않아야
통계적으로 유의하다고할 수 있다.-
total MD가 0을 포함하고, test에서도 p-value가 유의하지 않기 때문에
physical activity에 대해서는 2군간의 평균 차이가 없다라고 말할 수 있다.
-
total MD가 0을 포함하고, test에서도 p-value가 유의하지 않기 때문에
-
이질성을 확인해보니, P-value랑 I^2에 의해 이질성이 크다라고 나온다.-
이질성이 있을 경우, FE -> RE모형으로 바꿔줘야한다.
FE버튼만 한번 클릭해주면 된다.- 가중치가 바껴서 -> MD(effect size)가 아예 바뀐다.(음수 -> 양ㅅ)
- 신뢰구간도 넓어진다.
- total effect의 p-value로 바뀐다.
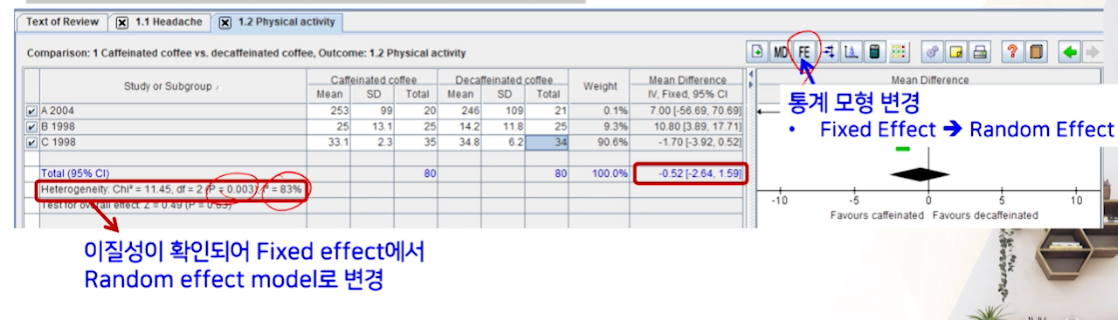
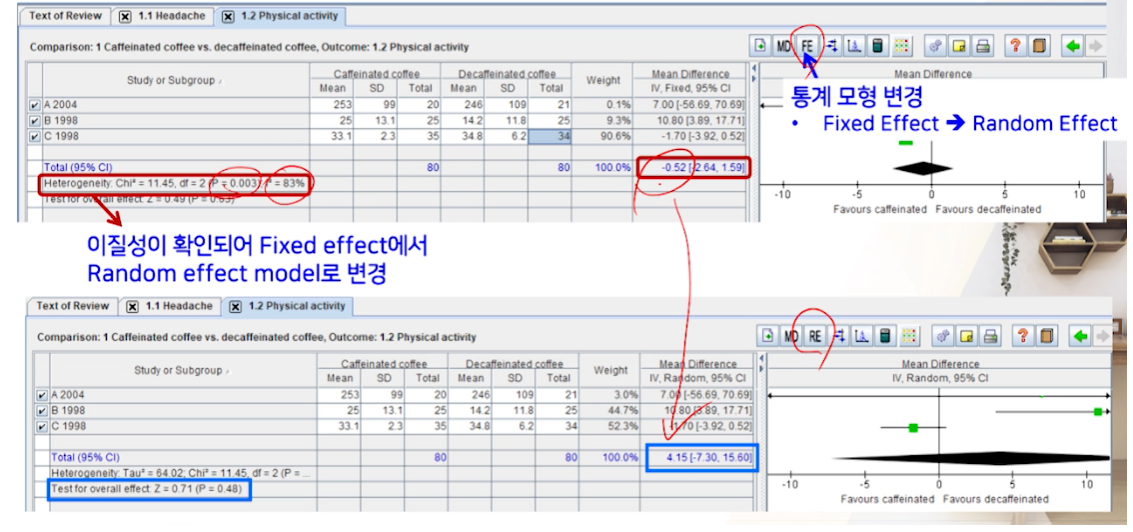
- 최종적으로 MD가 0보다 크기 때문에 카페인 > 디카페인 커피가 physical activity가 약간 큰 것 같긴한데, 통계적으로 유의한 차이는 없다
-
이질성이 있을 경우, FE -> RE모형으로 바꿔줘야한다.
- 3번째 연구가
Standardized Mean Difference
-
연속형 변수에 대한 raw data(Mean, SD, n)을 봤더니 첫번째 연구의 mean만 너무 높다 -> scale이 다른 것으로 측정됬을 것이다.
- 연속형 type의 outcome을 가지는 study를 모을 때 꼭 확인해야한다.
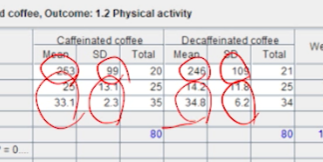
- 연속형 type의 outcome을 가지는 study를 모을 때 꼭 확인해야한다.
-
동일한 outcome을 different scale로 평가한 자료들의 입력
- Different scale로 측정된 outcome들의 경우 이들의 표준편차에 기초해 표준화 한 뒤 결합할 수 있다.
- 요약통계량을 MD ->
SMD로 변경해줘야한다.- weight도 %가 다 비슷해진다.
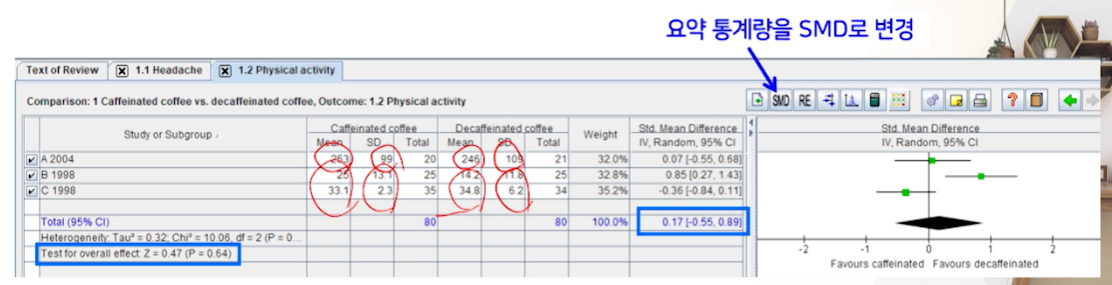
- 하지만, total MD나 test p-value로 봤을 땐, 통계적으로 유의하진 않다.
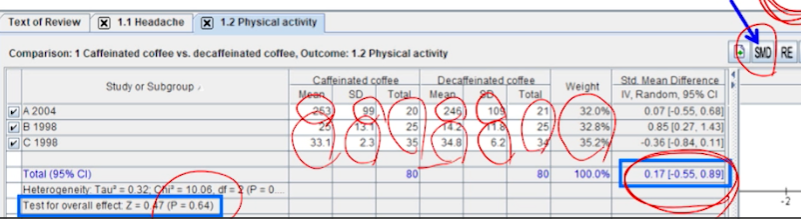
- weight도 %가 다 비슷해진다.
Subgroup Analysis(추가 연구)
- Outcome을 먼저 생성한 후, 생성된 outcome에 대한 subgroup을 정의할 수 있음.
-
Headache에 대한 결과가 이미 나온 상태에서, 별도로 subgroup을 나눠서 분석하려면
-
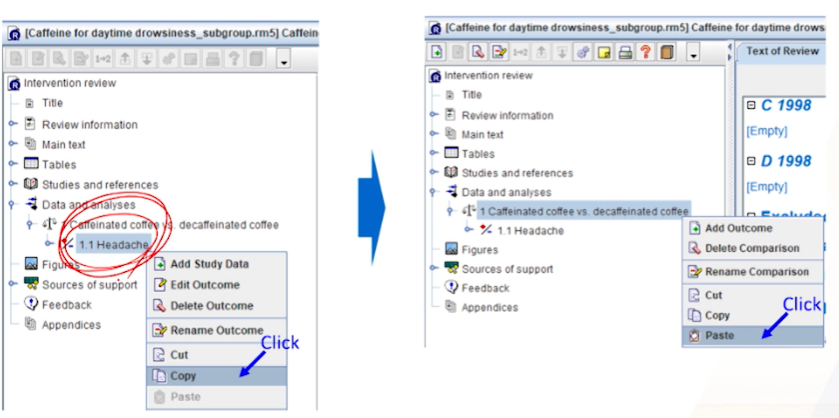
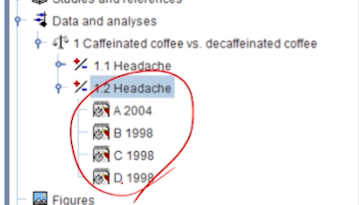
기존 Headache 결과를, comparison에 그대로 Copy해서 붙여넣는다.
-
기존 Headache 결과를, comparison에 그대로 Copy해서 붙여넣는다.
-
복사된 outcome에 RMB >
introduce subgroup을 클릭한다.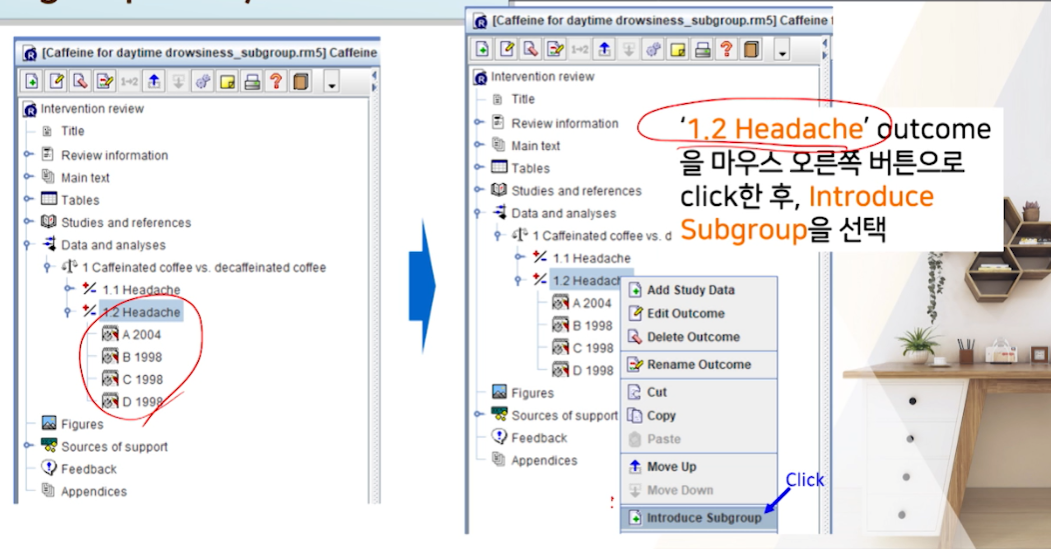
- 하위에
New Subgroup이 추가된다.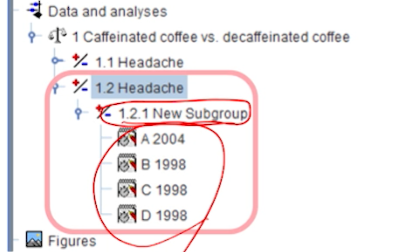
- 하위에
-
RMB >
Rename Subgroup을 통해, subgroup 중 1개의 이름만 명시해준다.(나머지 이름은 추가해서 나눌 것임)- 원래는 study수가 적기 때문에 subgroup을 나누는 것을 추천하지 않지만 연습이라서 해본다.
-
Subgroup으로 출판년도를 고려해보자. (1998년 vs 2004년) -Subgroup에 대한 이름으로 ‘year 1998`으로 입력한다.
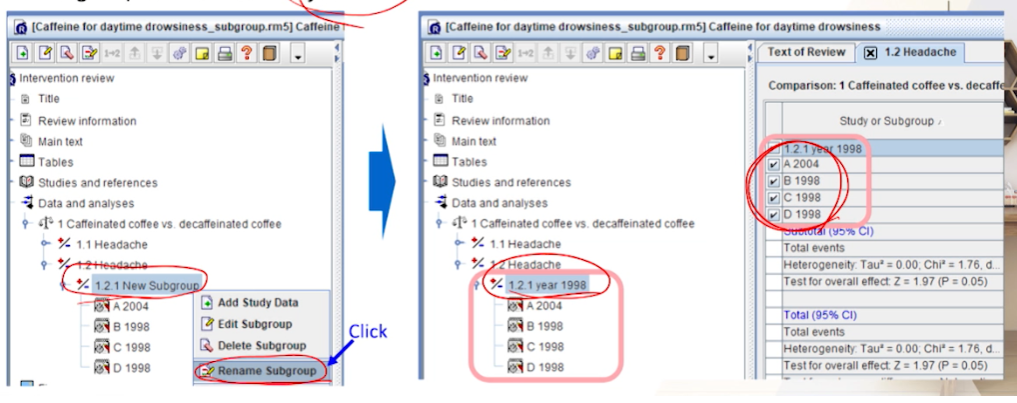
-
두 번째 subgroup 지정: ‘1.2 Headache’ outcome을
RMB > Add Subgroup을 선택한다. 그러면 New Subgroup Wizard 창이 열린다. 두 번째 subgroup 이름으로year 2004라고 입력한 뒤, Next를 클릭한다.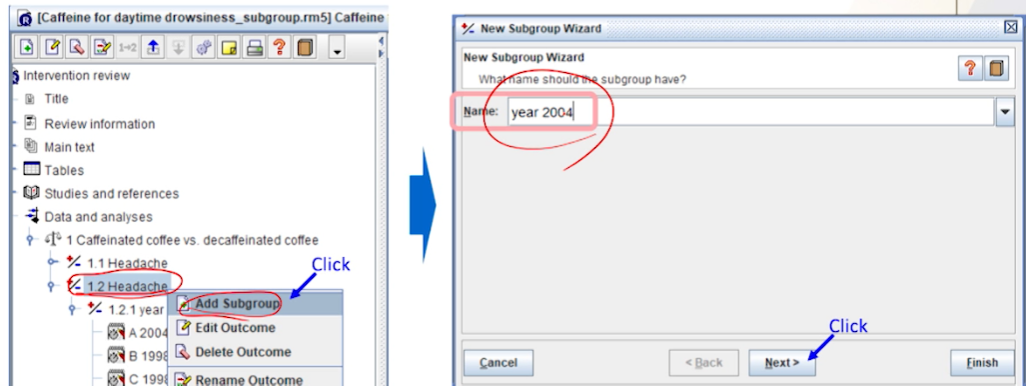
-
Edit the new subgroup을 선택한 뒤, Finish를 클릭한다.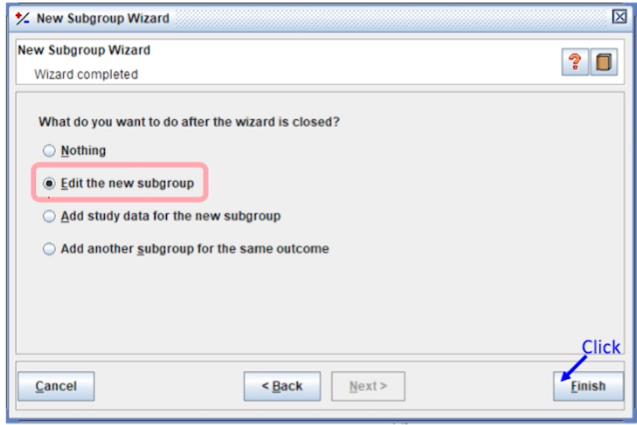
-
기존 그룹에 속해있는 2004 study를 잘라내기 해서 가져온다
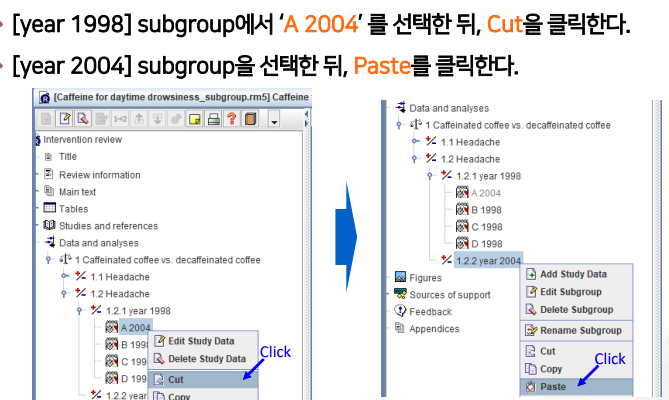
- 결과 확인
- subgroup별로 결과 및 그래프가 나온다.
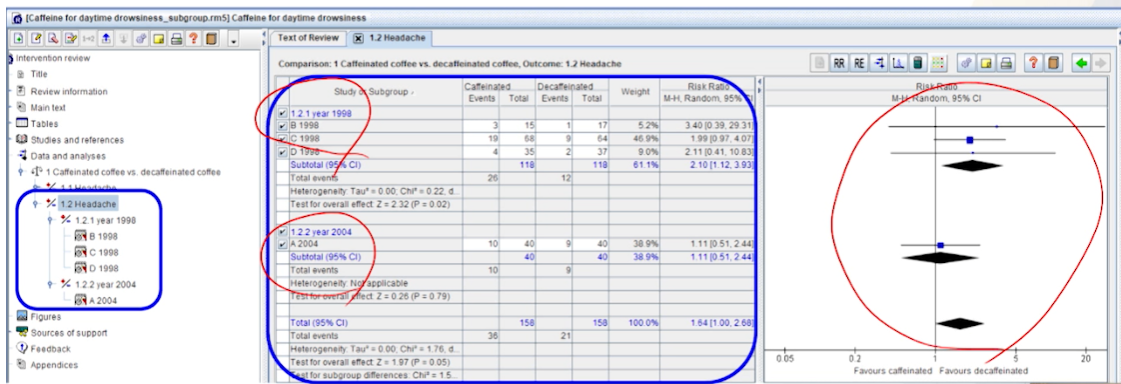
- 각 그룹별 결과 뿐만 아니라 2그룹간의 차이가 있는지도 나온다.
- 여기선 P=0.22로 차이점가 없다고 나온다.
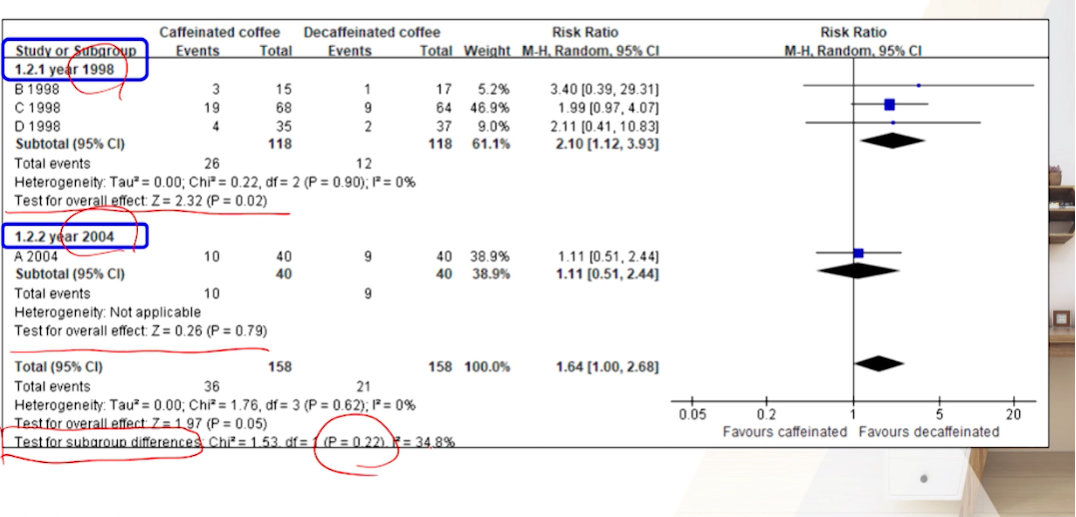
- 여기선 P=0.22로 차이점가 없다고 나온다.
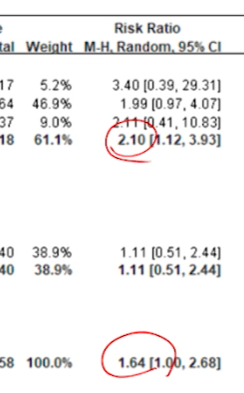
- effect는 1998년도가 더 effect가 높으니, 연구간 이질성을 해결해보거나 특정한 서브그룹 결과에 집중해본다.
- subgroup별로 결과 및 그래프가 나온다.
Risk of bias(Rob) graph &summary
- 메타분석 전단계인
문헌에 대한 질평가 =비뚤림 위험성평가를 그래프로 만들어주는 기능을Revman에서 제공한다.- risk of bias는 코크만에서 만들었으며, revman 역시 코크만에서 만들었다.
-
Figure를 만들건데, 먼저
Tabe > Chracteristics ~ > Chracteristics ~내려간다
-
2가지 연구에 대해 각 스터디들 정보를 기입해야한다(원래는)
- 밑에 보면
Risk of bias table탭이 보인다.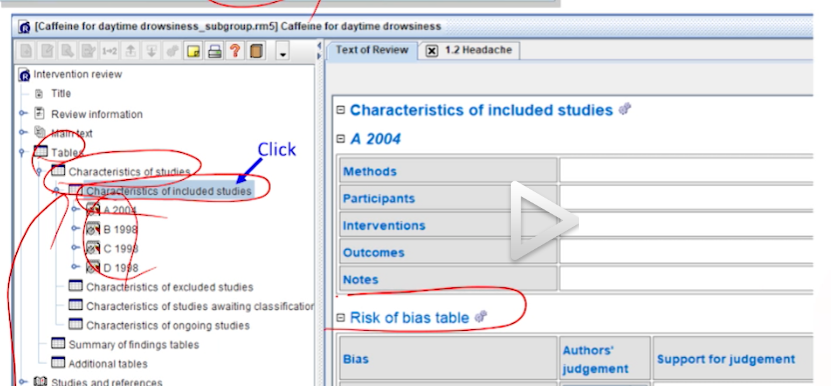
- 원래 Rob는 RCT를 평가하는 것이기 때문에, RCT관련 항목들이 나온다.
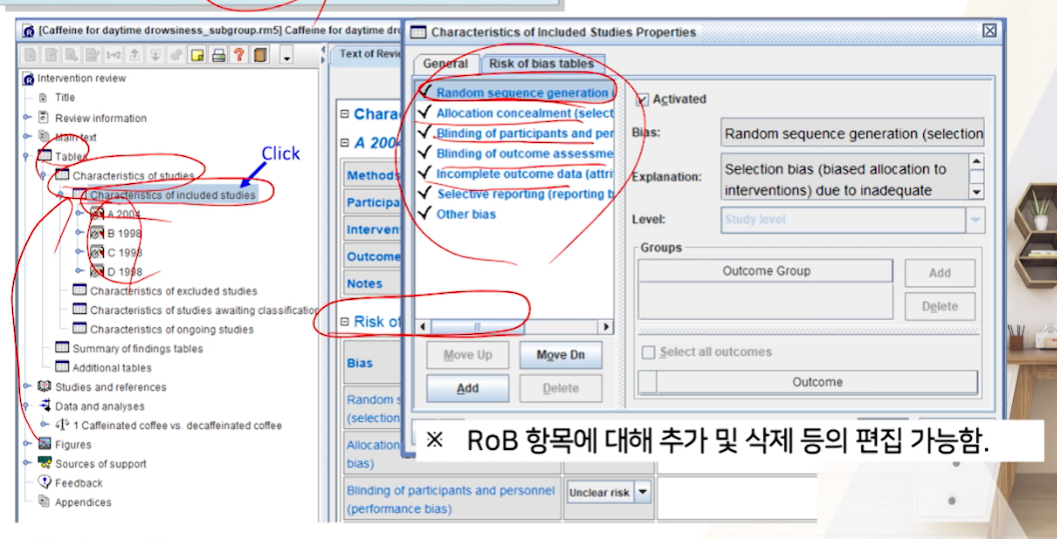
- 각 스터디마다 risk를 판단해서 평가한다
- Unclear risk (잘모르겠다)를 선택할 경우 -> 우측 Support for judgement를 클릭해줘야한다. 안해주면 그래프가 안그려짐
-
여기서는 blank를 넣어줬는데, 이것도 graph에서 누락되니 꼭 적어줘야한다.
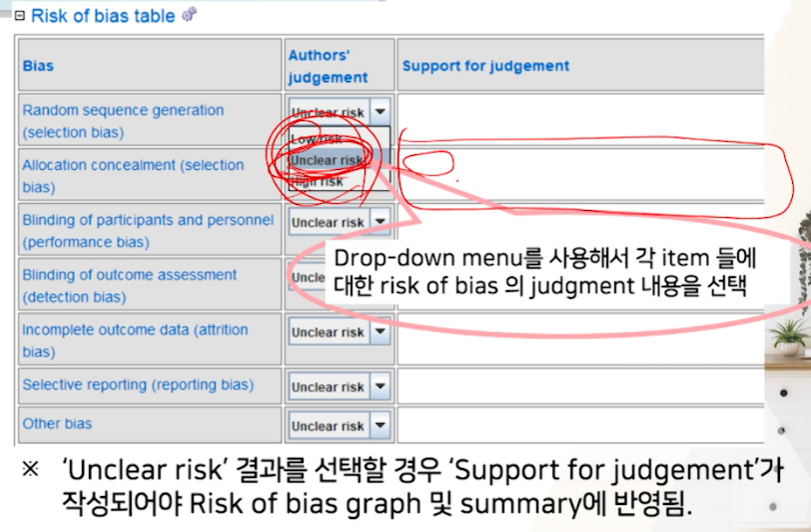
-
여기서는 blank를 넣어줬는데, 이것도 graph에서 누락되니 꼭 적어줘야한다.
- Unclear risk (잘모르겠다)를 선택할 경우 -> 우측 Support for judgement를 클릭해줘야한다. 안해주면 그래프가 안그려짐
- 밑에 보면
- Tables에서 각 risk 판단을 해줬다면,
Figure로 내려와서Add Figure를 클릭한 뒤,Risk of bias graph혹은Risk of bias summary를 선택한 후, Next를 클릭한다.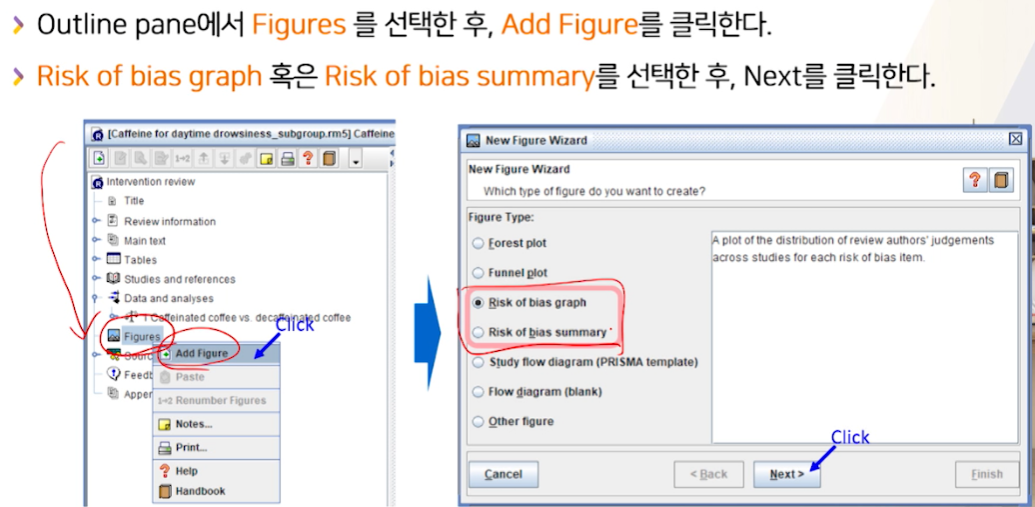
- caption이 필요하면 적어준다.
- caption이 필요하면 적어준다.
- Unclear risk에 대해서 안채워졌더니, 노란색이 아예 안나타난다.
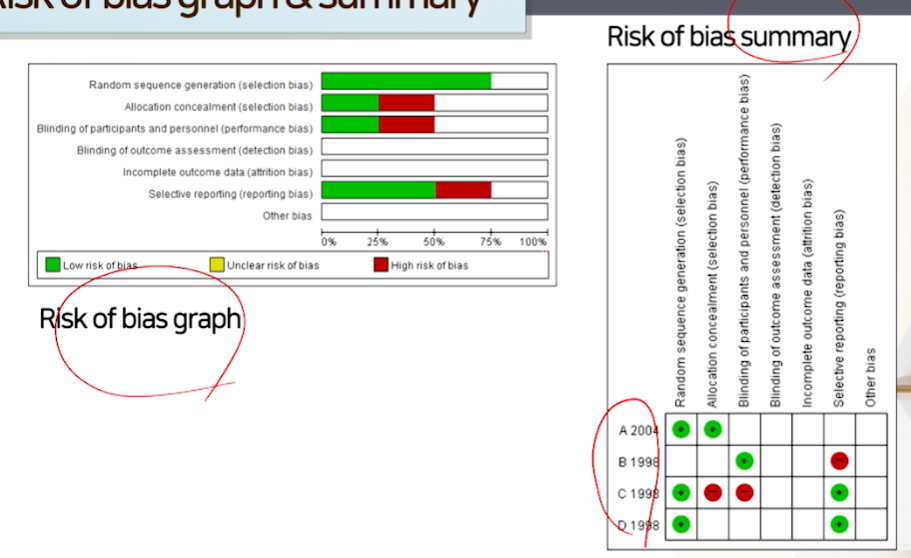
정리하기
메타분석은 체계적 문헌 고찰 수행과정에서 2개 이상의 개별 연구의 요약 통계량을 합성함으로써 해당 중재법의 통합된 가중평균 요약 통계량을 정량적으로 산출하여 임상적 효과성을 평가하기 위해 사용되는 통계적 기법이다.
메타분석을 수행할 수 있는 통계 소프트웨어 중 RevMan 5(Revman Manger)은 코크란 그룹에서 무료로 제공하며 설치하기 용이하다.
RevMan 5은 요약 통계량을 결합하기 위한 메타분석의 통계모형으로 고정효과 모형과 변량효과 모형을 제공하고 있다.
RevMan 5은 이질성(Heterogeneity) 평가를 위한 통계분석방법을 제공하고 있다.
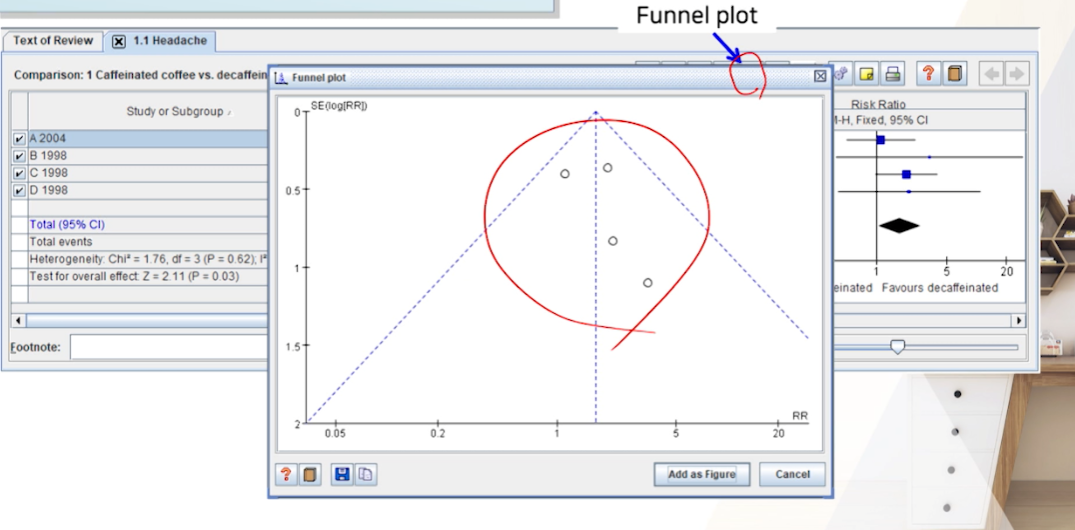
RevMan 5은 출판 비뚤림(publication bias) 평가를 위한 funnel plot만을 제공하고 있다.