강의) 제이슨 SQL 기본 강의
From(join),Where/Group by, having/Select/Order by,limit
📜 제목으로 보기
복습 정리본
- 해석
-
보고싶은 것을 f어떤 테이블(j)에서 w조건으로 보는데 - g그루핑한다면 h어떤조건으로 볼건지 정하고
- s어떤 데이터를 볼 것인지 정한다.
- 보는 데이터를 o어떤순서로, l몇개 볼 것인지도 정해준다.
- 문제 해석은
수식어는join될, fk가진 테이블속 재료 /명사가먼저 찾을 테이블속 재료로 먼저 찾는다.
-
- 문제1 풀이
-
첫번째 재료를어떤테이블에서 어떤조건으로... 어떤 데이터를 볼 지 정해서찾는다.- 탐색용
select *에는 항상limit 100을 붙여서 탐색하자.
- 탐색용
-
첫번째 재료에 달린 조건 속 숨은 재료도 첫번째 재료가 담긴 테이블에 없다면, 첫번째 재료 테이블에 연결될 수 있게fk_id가지면서,숨은 재료를 가진 테이블을 찾는다.(연결 재료는 조건이 +1)- my) 첫재료테이블id를 fk로 가지는지부터 확인해서 필터링하자
- 첫번째 재료가 포함된
테이블명_id를 기억해서 fk로 가진 테이블만 연결된다는 것을 생각하자. - 연결된 재료 찾기는
연결될 재료뿐만 아니라연결에 필요한 첫번째 재료의 테이블_id(fk)까지 필요하여, 조건이 2개가 필요한 것이 차이점이다.
-
연결에 필요한
첫재료테이블_id-> join을 통해 ->첫재료자체로 연결하여 변환할 수 있다.- fk자리를 join연결을 통해 첫재료로 바꿔볼 수 있다.(
ProductId -> ProductName)의 새로운 관점 -
실제 join은 fk테이블(다)에 자리바꿔들어가는게 아니라, PK테이블(일)에 left로 꽂는다.
left로 꽂으면서 첫재료의 데이터가 (다)로 늘어나는데, fk테이블은 꽂으면서 fk를 PK테이블의 원하는 데이터 중 1개로 대체한다는 관점으로 가져가보자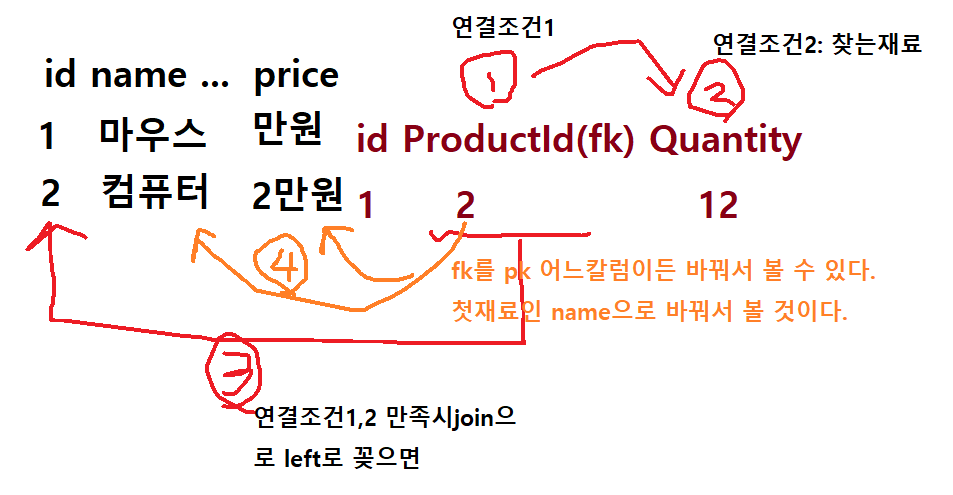
- fk자리를 join연결을 통해 첫재료로 바꿔볼 수 있다.(
-
연결조건을 갖춰 연결하여 fk를 통해 left에 꽂아 연결한 뒤, 원하는 데이터로 대체해서 볼 수 있지만, 1:1관계가 아닌 이상
1 <- m을 갖다 꼽았다면,꽂임 당한 PK테이블 쪽은 없던 중복이 생길 수 밖에 없다꽂힘 당하면서 중복이 생긴 PK테이블은 select에서 id를 distint()를 걸어 중복제거후 count()를 씌워 갯수를 확인한다.- (고객이)
상품(목적어m)을주문(동사, 1)한다. -> 주문:상품 = 1:m관계- 반대로, 1상품이 여러개의 주문에 들어갈 수 도 있으니 m:n관계다. 어디든 m이 꽂히는 입장이니, 중복은 생긴다.
-
주로 fk를 가진 m이 꽂히며 -> join결과
1쪽에 대해 중복이 발생한 상태이다.- 1주문당 m이꽂히므로,
주문갯수 n x 꽂힌 m 상품이 총 데이터 갯수다. 주문당 여러개란 뜻이지 항상 m개를 가지고 있지 않으므로 그만큼 많이 중복?!
- 1주문당 m이꽂히므로,
join후 1(PK)에 생긴 중복을 고려해서 select에서 id를 distinct로 중복제거하여 실제 사용된 데이터 갯수를 준비를 하자
- (고객이)
- distinct(pk.id)는 첫재료(1)쪽의 사용된 갯수 확인일 뿐이다.
연결된 중복 데이터에 대해집계하여 중복제거를 하기 위해서는group by + 집계함수로 해야한다. 이 때, 1쪽에 대한group by는 원본재료의 id를 통해하는 것이다.필요한 재료는 select절에서 id이후 1쪽은 나열, m쪽은 집계해서 가져온다.id를 통해 groupby 집계해놓고, 거기에select절에서는 id기본 + 타 컬럼정보를 가져다가 1쪽은 어차피 중복제거되었으니 나열, m쪽은 집계할 수 있다.- m쪽을 집계안하면? 첫번째 데이터만 올라오니 조심
-
m쪽을 집계안하고, 1쪽처럼 나열만 한경우
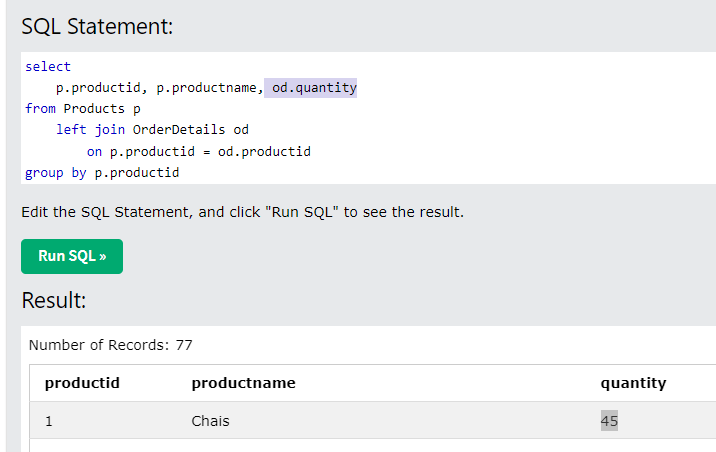
-
1쪽은 나열, m쪽은 집계한 경우
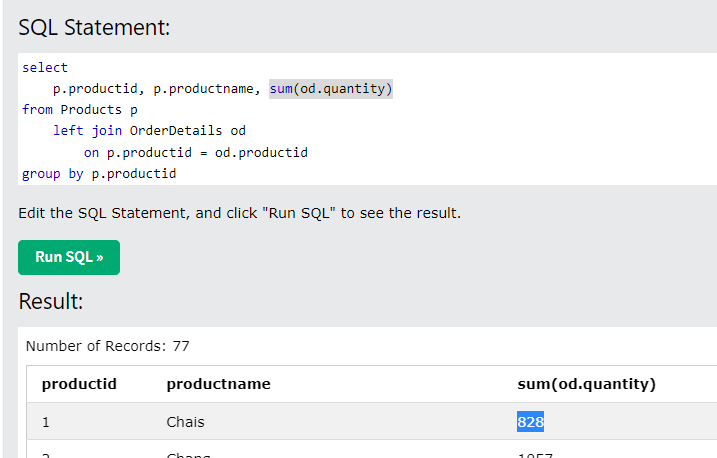
-
m쪽을 집계안하고, 1쪽처럼 나열만 한경우
-
m쪽 집계까지 끝난 뒤에야,
having으로 m쪽 집계한 메서드를 그대로 가져와 조건을 걸어준다.- having의 작성은
groupby -> select 1id, 1칼럼나열, m집계 -> m집계에 대해 조건순이지만 - having의 실제 실행은 select이후이므로
select에서 작성한 AS는 사용불가이다.select에서 준 m집계함수를 그대로 having에 걸어줘야한다.
- having의 작성은
- join후 집계, 집계조건 걸기까지 끝난 뒤, 순서없는 것에 대해 order by/limit 등을 걸어준다.
- order by는 m집계함수를 그대로 걸어줘도 되지만
- select이후라서 alias를 걸어줘도 된다.
-
alias주는 리팩토링
- from 에 걸린 대문자TABLE에 대해
AS 소문자로 alias를 준다. - 대문자로 쓰였던 TABLE_NAME들을 소문자alias로 교체한다.
select에서 준 소문자 칼럼alias는 having까지는 못준다. order by에서는 집계함수라도 alias로 줄 수 있다.
- from 에 걸린 대문자TABLE에 대해
select c.CustomerId as "고객ID", c.CustomerName as "고객이름", sum(od.Quantity) as "총 주문횟수" from Customers c left join Orders o on c.CustomerId = o.CustomerId left join OrderDetails od on o.OrderId = od.OrderId group by c.CustomerId order by sum(od.Quantity) desc; -
- 문제2 풀이
- customer(1) <- Orders(n) <- OrderDetails(m)을 join해놨어도, 중복이 n x m으로 생긴 customer에 대해 id로 group by하더라도 customer에 대해서만 하면 된다. Orders x OrderDetails(n x m)에 대해 집계하면 집계메서드에 의해 다 모이게 되어있다.
- Orders는 OrderDetails에 대해 집계로 중복제거 안해도 되나? -> 목표가
고객별 집계니까,, 알아서 다 집계된다. 목표가고객별/주문별 집계가 아니라는 점을 인식하자.
- Orders는 OrderDetails에 대해 집계로 중복제거 안해도 되나? -> 목표가
-
m:1 관계에서
fk를 가진 m에다가pk - 1쪽의 데이터를 left join할 수 있다.- Customers(1) <- Orders(k-830) <- OrderDetails(n-2155,
Quantity) <- Products(1,prices)- 필요재료는
총 구매금액 = quantity \* prices을customers별 집계해야한다.
- 필요재료는
-
이 경우,
join을 받는 m쪽에 데이터 중복이 안생기고 row 당 1개 정보만 추가된다.
-
my) left join을 받는 쪽은
받는 쪽 row 1개당 정보가 추가되는데- 보통은
1(PK)쪽에 <—M(fk)를 left join으로 박아서,row 1개당 대략 m개의 데이터 중복이 생긴다고 생각한다.- 다른 의미로는 m(fk)테이블 쪽에 있는 fk(pk_id)대신 (join된 테이블에서) pk테이블의 칼럼 중 택하여 정보를 바꿔 볼 수 있다. pk테이블의 칼럼 기반으로 나열하여 집계 + fk테이블(m)은 집계메서드하여 살펴볼 수 있다.
-
연결하다보니
M(fk)<—1(PK)를 **left join으로 박아서,(m쪽이지만) row 1개당 중복없이 1개의 정보 추가만 발생한다고 생각하자.- my) left join을 fk(
연결당할 놈이 fk를 가지고 있는 경우) <— (연결할 놈이지만 fk를 안가지고 있는)pk방향으로 하는 것은row 1개당 1:1로 추가정보만 1개 더 추가한다고 생각하자.
- my) left join을 fk(
- 보통은
- my)
fk를 안들고 있는데 연결해야한다? ->최초 박힘의 테이블orfk는 없지만, fk있는 곳에 1row당 1개 정보를 제공해주는 테이블 -
my) 현재 테이블이 fk를 들고 있다면,
m <- 1 left join을 통해서pk테이블로, fk를 들고 있는 현재 테이블에 row당 1개 정보 를 제공한다.- ex> 고객의 주문정보들(fk_productId) <— (productId) 1row당 상품정보(prices)를 중복없이 정보만 제공
-
my) 1쪽을 두고 m(fk)를 박아야, group by시 id로 해놓고, 1쪽칼럼은 나열 vs m쪽칼럼은 집계를 편하게 할 수 있을 것 같다.
select c.CustomerId, c.CustomerName AS name, sum(od.Quantity * p.price) AS total from Customers c left join Orders o on c.CustomerId = o.CustomerId left join OrderDetails od on o.OrderId = od.OrderId left join Products p on od.ProductId = p.ProductId group by c.CustomerId order by total desc
- Customers(1) <- Orders(k-830) <- OrderDetails(n-2155,
- customer(1) <- Orders(n) <- OrderDetails(m)을 join해놨어도, 중복이 n x m으로 생긴 customer에 대해 id로 group by하더라도 customer에 대해서만 하면 된다. Orders x OrderDetails(n x m)에 대해 집계하면 집계메서드에 의해 다 모이게 되어있다.
SQL
update
-
where을 안주면 테이블 전체가 바뀐다.
distinct 와 groupby로 중복제거
-
distinct: 종류별로 1개만 남기도록 중복제거
-
group by로 인해 그루핑으로기준칼럼별 중복제거된 데이터로 보기가 편해진다- select이니까 결국엔 보이는 중복만 제거하지만,
같은 그룹기준별로 보여주니그룹기준칼럼이 종류별로 1개가 되는 점+ 그 1개에 대한 여러 중복데이터들은 필요시 강제집계을 이용하는 것이다.
-
원래 그룹바이는 1000000개의 데이터를
보기 편하게 묶어서 보기위함이다.- 그 과정에서 그룹의 기준이되는 칼럼은 중복이 제거되어 1개가 된다.
- select이니까 결국엔 보이는 중복만 제거하지만,
-
group by이 궁극적인 목적은 기준칼럼의 중복제거가 아니라 ->중복제거된 기준칼럼에 속하는 단일 or 여러데이터들의 집계가 목적이다
-
having으로 그루핑한 상태에서 where를 걸 수 있다. -
select(셀렉)시 limit 100, limit 1000을 버릇화해야한다.order by-
limit- 체스게임 같은 경우, 생성날짜가 있다면 orderby limit1을 적용할 수 있다.
select(쎌렉!)
보는 순서

from부터 where, group by, having까지 내려가되, select한 뒤 order by+limit

-
from 부터 볼 건데
join이 올 수 도 있다. - where로 조건을 줘서
어떤 범위들을 볼 지 조건으로 지정하고 - group by로
그룹별로 묶어서 보고 -
having
그룹 중 어떤 그룹을 볼지 조건으로 지정하고 -
f(j)-w/g-h으로 만들어진 데이터 중 select으로어떤 데이터만 골라서 볼 것이며 - select이후 order by, limit으로
어떤 정렬로, 얼만큼 짤라 볼 것인지 지정한다
쎌렉이 제일 마지막 같지만, 5.쏄렉에서 지정한 alias를 -> 6. order by + limit에서 사용할 수 있다. -> where은 fw gh 다음 select이라 select의 별칭이 안먹힌다
sql해석방법
from부터 내려가면서 [어떤 테이블f에 어떤범위w로부터 그룹핑g을 한다면, 어떻 그룹h을 골라볼 것인지 정해지면 -> 어떤데이터s만 골라서 볼지 정한 뒤 -> 그 데이터를 어떻게 정렬orderby하고 어떻게 짜를limit 것인지는 [쎌렉이후 칼럼선택 + alias주고] 본다
해석시 쎌렉은 fw-gh- 다음인줄알았는데, 직접 작성시에는 groupby까지하고 쎌렉에 집계메서드로 집계해놓고 -> 그대로 칼럼처럼 가져와 having에 조건을 추가한다.
심지어 order by에서도 쎌렉에 있는 [[집계칼럼메서드를 칼럼]]으로 그대로 가져다 쓴다.
주의! 작성은 쎌렉 집계후 having에서 갖다썼지만, 실행은 having후 쎌렉이라서-> having절(+where절)에 쎌렉alias못쓴다!
실습
- 실습 사이트 w3schools: https://www.w3schools.com/sql/trymysql.asp?filename=trysql_func_mysql_concat
주의점: 서브쿼리X + innerjon외 left or right 1개만 섞을 것
문제1
1. 200개 이상 팔린 상품명과 그 수량을 수량 기준 내림차순으로 보여주세요.
풀이1
# 1. 200개 이상 팔린 상품명과 그 수량을 수량 기준 내림차순으로 보여주세요.
## 1-1. 재료가 일단 어디있는지, 재료가 속한 <테이블> 찾는다. [상품명] -> [수량] 단독 재료같지만, [상품명] 앞에 200개 이상 팔린 -> (연결된 조건재료)에 속한다.
## [상품명]은 왠지 Products테이블에 있을 것 같다
-- select * from Products; -- 지금은 77개 밖이지만, 테이블 전체데이터 쎌렉시 limit 100, 1000을 고려하자
-- * from Products limit 100;
## ProductName의 [상품명]이 있는 테이블을 찾았다.
## 1-2. [재료:상품명]에 (수식어)가 있으니 ([재료]와 연결된=찾은테이블+Id를 Fk로 가져 연결이 가능한 (조건 연결재료))로서 (200개 이상 팔린)의 (주문량,팔린량)을 가진 <테이블>을 찾아야한다.
## (팔린) -> 주문과 관련있는 것 같아서 <Orders>테이블을 조회해본다.
-- select * from Orders limit 100;
-- OrderID CustomerID EmployeeID OrderDate ShipperID
## 뭐야 (팔린량,주문량)도 없고 [상품명과 연결될 ProductId]도 안가지고 있다.
## my) 추가정보를 얻기 위해선
## 다시 테이블을 보니, <OrderDetails>가 있다.
-- select * from OrderDetails limit 100;
-- OrderDetailID OrderID ProductID Quantity
-- 1 10248 11 12
-- 2 10248 42 10
-- 3 10248 72 5
## 여기에 [상품명]과 연결시켜주는 [ProductID]와 + (주문량, 팔린량 Quantity)가 동시에 있다.
## my) 수식어, 조건 재료를 찾을 때는 (수식재료) 뿐만 아니라 [원본재료의 테이블과 연결된 원본재료테이블ID]도 가지고 있어야한다.
## FK인 ProductId는, Product테이블입장에서 [상품명]을 대표하는 그야말로 Id이므로,
## -> (연결재료)찾을 시 [FK테이블+ID]의 FK자체를 -> [연결된 기존재료]로 해석해도 된다.
## --> [FK 테이블Id]를 [상품명]등 [재료]로 바꿔보기위해선 join이 필요한 것
-- OrderID ProductID Quantity
-- 10248 11 12
## ex> ProductId(FK)가 11인 것은 주문량이 12다
## = [해당 11번 상품명]은 12개 팔렸다
## -> join으로 연결해서보면 [11번 상품명] [주문량 12개 팔림]으로 보인다.
## 1-3. 재료들을 다 찾았다면, join해서 보는 것으로 결정낸다.
## -> join시 on자리에 <기존테이블>.[기존재료]의PK_ID ---- <연결재료테이블>.(연결 재료)를 찾을 때 보이던 [FK_id]로 연결해주면 된다.
select * from Products
inner join OrderDetails on Products.ProductId = OrderDetails.ProductID;
## 이 때, Products >- Orders : (고객이) 상품을 주문한다 -> 주문:상품 = 1:m 관계다.
## -> 1주문당 여러개의 상품을 가질 수있으며 -> 주문들을 모아놓은 테이블은, 각 주문마다의 상품들이 겹칠 수 밖에 없다.
## 즉, 1:m 을 join했다면, 1(주문량, 상품FK)에서 m에 있는 정보(상품명 with 상품PK)를 얻기위해 붙인 것으로 [중복이 발생할 수 밖에] 없다
## 2. 재료들을 합친 상태라면, 이제 (조건재료)속 조건 or 요구사항을 만족시켜줘야한다.
-- select * from Products
-- inner join OrderDetails on Products.ProductId = OrderDetails.ProductID;
## 2-1. (200개 이상 팔린) [상품명]의 (요구사항)은 어떻게 처리?
## 2-2. 1:m의 join에서 1order당 mProduct명 -> n order : n x m Product -> n X m개의 row속에 중복이 무조건 존재한다.
## -> 일단 m쪽에서 제공해준 FK을 [[ 쎌렉 distinct( FK ) ]]로 중복제외한 종류별로 1개씩이라면 총 몇개가 사용됬는지 확인한다.
## -> on에 걸린 아무FK or PK를 가져와서 쎌렉으로 복붙해서 * 대신 -> distinct( FK )를 넣어준다
## --> 1쪽인 order도 자기가 가졌던 m개의 product에 대해 모두 같은 orderId를 가져 중복이 된다.
## --> 1쪽은 1:m으로 1order라도, m쪽에서 본다면, m개의 order를 가지게 되는 것.
## my) 1:m에서 1개 데이터라도 m입장에서는 기본 m개 중복이네!
## my) 오히려 1입장에서 1개 데이터라면, m은 중복없기 수량칼럼을 가질 듯.
## my) 1:m은 join전에는 m이 미중복, 1은 m개만큼 중복 -> [[1개 데이터일 땐 미중복 m개의 데이터]] join후 [[1이었떤 order가 늘어남에 따라 m에서도 중복이 생길 가능성이 높아진다]]
## 2-3. <<distinct()>>로 [join전 1개 order에 대해 미중복이던 m쪽 Product]가 join후 중복됬는데,
## << join으로 생긴 중복들 속에 [[ 실제 사용된 m쪽의 데이터]]는?>> by <<distinct( on에 걸려있는 m의 FK)>>
-- select * from Products -- 2155
-- inner join OrderDetails on Products.ProductId = OrderDetails.ProductID;
-- 77 : 중복이 발생한 m Product 중에 실제로는 77종류(distinct종류별 1개씩이니)만 사용되었다.
select distinct(Products.ProductId)
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID;
# 3. join후 생긴 m쪽 Product가 중복된 상황에서 (77개 -> 2155개 데이터로 중복된 상태)
## - cf) 1쪽 Order는 1개의 order에 대해 m개의 OrderId가 동일한 중복상태 -> join하더라도, order의 갯수만큼만 distinct함.
## - my) 1쪽은 join시, 달라붙는 order만 추가되고 매번 그 안의 m개 Product에 대해 중복이므로, -> Order의 row수 == join시 distinct()한 orderId수 동일함.
## - my) m쪽은 1order시 중복없다가, join시 중복이 발생할 가능성이 있으니 [[m쪽만 중복을 필수 확인]]해야함.
-- select distinct(Products.ProductId)
-- from Products
-- inner join OrderDetails
-- on Products.ProductId = OrderDetails.ProductID;
## 3-1 요구사항을 보면 (200개 이상 팔린) [상품명] -> 중복가능성이 있는 m쪽이므로
## -> distinct가 아닌 [[m쪽의 Id로 groupby]]해서 중복을 제거와 함께 집게해야 [수량]을 판단할 수 있게 된다.
select *
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID
group by Products.ProductID;
-- 77;
-- Number of Records: 77
## (m쪽id)로 groupby하여 집계를 하면, distinct(m쪽Id)한 것과 동일한 갯수가 나온다 -> 집계로 중복제거
#### 근데 집계함수를 안쓰고 group by 만 상태 -> distinct하기만 하고 집계는 안되어있는 상태다!
#### -> group by는 되어있는데, 첫데이터만 대표로 내어놓은 상태
# 4. 집계준비가 되었다면, 쎌렉에서 집계한다.
## 현재 [group by 재료ID]로 -> [ distinct한 mProduct별로 집계된 데이터] && 쎌렉에서 집계는 안해줬다면, 첫데이터만..
## 4-1. 일단 쎌렉절에 각 테이블에서 가져온 [재료]들과 그 [ID]까지 쎌렉해야한다. group by는 id로 하는 것이다.
## -> <타테이블>.(연결재료)는 꼭 ID가 없어도 되긴한다.
## -> 마지막으로 집계(연결재료) 등 집계대상을 집계해준다.
## --> <해당테이블>.[재료ID] <해당테이블>.[재료(상품명)] <타테이블>.(연결재료)
## --> <해당테이블>.[재료ID] <해당테이블>.[재료(상품명)] sum ( <타테이블>.(연결재료) )
-- select *
-- select Products.ProductID, Products.ProductName, OrderDetails.Quantity
select Products.ProductID, Products.ProductName, sum( OrderDetails.Quantity )
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID
group by Products.ProductID;
-- Number of Records: 77
-- ProductID ProductName sum( OrderDetails.Quantity )
-- 1 Chais 828
-- 2 Chang 1057
-- 3 Aniseed Syrup 328
## 4-2. 집계가 완료된 데이터에서 having을 건다.
## my) 해석시 쎌렉은 fw-gh- 다음인줄알았는데, 직접 작성시에는 groupby까지하고 쎌렉에 집계해놓고 -> 그대로 가져와 having에 조건을 추가한다.
## -> 쏄렉: sum( OrderDetails.Quantity ) -> having : sum( OrderDetails.Quantity ) >= 200
select Products.ProductID, Products.ProductName, sum( OrderDetails.Quantity )
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID
group by Products.ProductID
having sum( OrderDetails.Quantity ) >= 200;
## 4-3. 심지어 order by에서도 쎌렉에 있는 [[집계칼럼메서드를 칼럼]]으로 그대로 가져다 쓴다.
select Products.ProductID, Products.ProductName, sum( OrderDetails.Quantity )
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID
group by Products.ProductID
having sum( OrderDetails.Quantity ) >= 200
order by sum( OrderDetails.Quantity ) desc;
쎌렉에 집계 alias 리팩토링 for order by, limit
## 4-4. 이제 쎌렉을 가져다 쓰는 놈들(order by, limit ) 을 위해 [[ 쎌렉에 alias주는 리팩토링 ]] 하기
## -> 주의! 작성은 쎌렉후 having에서 갖다썼지만, 실행은 having후 쎌렉 -> having절에 쎌렉alias못쓴다!
## 1) select 집계에 alias주기 -> total
## 2) order by, limit에서 alias로 바꾸기
select Products.ProductID, Products.ProductName, sum( OrderDetails.Quantity ) as total
from Products
inner join OrderDetails
on Products.ProductId = OrderDetails.ProductID
group by Products.ProductID
having sum( OrderDetails.Quantity ) >= 200
order by total desc;
from(+join)에서 에만 테이블 as 소문자 별칭 -> 이후 fw-gh-select까지 보이는 테이블 모두 alias주는 리팩토링
## 4-5. from(+join)에 주어지는 테이블의 대문자만 따서 alias로 주는 리팩토링 -> fw-gh-s까지 다 리팩토링 가능해진다.
## from에만 as 소문자 -> 그 뒤로는 테이블들 모조리 소문자로 변경
select p.ProductID, p.ProductName, sum( od.Quantity ) as total
from Products as p
inner join OrderDetails as od
on p.ProductId = od.ProductID
group by p.ProductID
having sum( od.Quantity ) >= 200
order by total desc;
문제2
2. 많이 주문한 순으로 고객 리스트(ID, 고객명)를 구해주세요. (고객별 구매한 물품 총 갯수)
풀이2
-- 후니
select c.CustomerID, c.CustomerName, sum(od.Quantity) total from Customers c
join Orders o on c.CustomerID = o.CustomerID
join OrderDetails od on o.OrderID = od.OrderID
group by c.CustomerID
order by total desc;
-- 아리
SELECT Customers.CustomerID , Customers.CustomerName , SUB.Quantity
FROM Customers
JOIN (SELECT Orders.CustomerID AS ID , SUM(OrderDetails.Quantity) AS Quantity
FROM Orders
JOIN OrderDetails
ON Orders.OrderID = OrderDetails.OrderID
GROUP BY Orders.CustomerID
) AS SUB
ON Customers.CustomerID = SUB.ID
ORDER BY SUB.Quantity DESC;
-- 아서
SELECT c.customerid "고객 ID", c.customername "고객 이름", sum(od.quantity) "총 주문갯수"
FROM Customers c join Orders o ON c.customerid = o.customerid JOIN OrderDetails od ON o.orderid = od.orderid JOIN Products p ON p.productID = od.productId
GROUP BY c.customerid
ORDER BY SUM(od.quantity) DESC
-- 필즈
SELECT c.CustomerId, c.CustomerName, od.orderQuantity
FROM Orders o
inner join (
SELECT
OrderId,
sum(Quantity) "orderQuantity"
FROM OrderDetails
group by OrderId
) od
on o.OrderId = od.OrderId
inner join Customers c
on c.CustomerId = o.CustomerId
order by orderQuantity desc
;
-- 베루스
select c.CustomerId as ‘고객 아이디‘, c.CustomerName as ‘고객 이름‘, sum(od.Quantity) as ‘주문량’
from Customers as c
left join Orders as o on c.CustomerId = o.CustomerId
left join OrderDetails as od on o.OrderId = od.OrderId
group by c.CustomerId
order by sum(od.Quantity) desc
-- 루키
SELECT Customers.CustomerID, Customers.CustomerName
FROM Customers inner join Orders on Customers.CustomerID = Orders.CustomerID
GROUP BY Customers.CustomerID
ORDER BY COUNT(Orders.CustomerID) DESC;
-- 유콩
SELECT Customers.CustomerID AS `고객아이디`, Customers.CustomerName AS `고객이름`, sum(Quantity) AS `주문량`
FROM Orders
JOIN OrderDetails ON Orders.OrderID = OrderDetails.OrderID
RIGHT JOIN Customers ON Orders.CustomerID = Customers.CustomerID
GROUP BY Customers.CustomerID
ORDER BY `주문량` DESC;
-- 케이
SELECT Orders.CustomerId, Customers.CustomerName, sum(Quantity) FROM OrderDetails join Orders on OrderDetails.OrderId = Orders.OrderId join Customers on Orders.CustomerId = Customers.CustomerId group by Customers.CustomerName order by sum(Quantity) desc
-- 배카
문제3
3. 많은 돈을 지출한 순으로 고객 리스트를 구해주세요.
풀이3
-- 아서
SELECT c.customerid "고객 ID", c.customername "고객 이름", sum(od.quantity * p.price) "총 주문가격"
FROM Customers c join Orders o ON c.customerid = o.customerid JOIN OrderDetails od ON o.orderid = od.orderid JOIN Products p ON p.productID = od.productId
GROUP BY c.customerid
ORDER BY SUM(od.quantity * p.price) DESC
-- 케이
SELECT Orders.CustomerId, Customers.CustomerName, sum(Quantity*Price) FROM OrderDetails join Orders on OrderDetails.OrderId = Orders.OrderId join Customers on Orders.CustomerId = Customers.CustomerId join Products on OrderDetails.ProductId = Products.ProductId group by Customers.CustomerName order by sum(Price*Quantity) desc
-- 베루스
select c.CustomerId as ‘고객 아이디‘, c.CustomerName as ‘고객 이름‘, sum(od.Quantity*p.Price) as ‘지출액’
from Customers as c
left join Orders as o on c.CustomerId = o.CustomerId
left join OrderDetails as od on o.OrderId = od.OrderId
left join Products as p on od.ProductId = p.ProductId
group by c.CustomerId
order by sum(od.Quantity*p.Price) desc
-- 디우
select Customers.CustomerID, Customers.CustomerName, sum(OrderDetails.Quantity * Products.price)
from Customers, OrderDetails, Orders, Products where Customers.CustomerID = Orders.CustomerID AND
OrderDetails.OrderID = Orders.OrderID AND Products.ProductID = OrderDetails.ProductID
group by Customers.CustomerID
order by sum(OrderDetails.Quantity * Products.price) desc;
-- 후니
SELECT c.CustomerID, c.CustomerName, (p.Price * od.Quantity) total FROM Customers c
join Orders o on c.CustomerID = o.CustomerID
join OrderDetails od on o.OrderID = od.OrderID
join Products p on od.ProductID = p.ProductID
order by total desc;
-- 코린
select c.CustomerID, c.CustomerName, sum(od.Quantity * p.price) as total_price
from Orders o
join OrderDetails od on o.OrderID = od.OrderId
join Customers c on o.CustomerID = c.CustomerID
join Products p on od.ProductId = p.ProductId
group by c.CustomerID
order by total_price desc;
-- 이프
select c.CustomerID, c.CustomerName, sum(od.Quantity * p.Price) as total
from Customers as c
join Orders as o on c.CustomerID = o.CustomerID
join OrderDetails as od on o.OrderID = od.OrderID
join Products as p on p.ProductID = od.ProductID
group by c.CustomerID
order by total desc
-- 루키
SELECT Customers.CustomerName
FROM Customers
INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID
INNER JOIN OrderDetails ON Orders.OrderID = OrderDetails.OrderID
INNER JOIN Products ON Products.ProductID = OrderDetails.ProductID
GROUP BY Customers.CustomerID
ORDER BY SUM(OrderDetails.Quantity * Products.price) DESC;
-- 더즈
select c.CustomerId, sum(p.Price) as '총지출' from Customers c
inner join Orders o on c.CustomerId = o.CustomerId
inner join OrderDetails od on od.OrderId = o.OrderId
inner join Products p on p.ProductId = od.ProductId
group by c.CustomerId
order by sum(p.Price) desc;
-- 필즈
SELECT
c.CustomerId,
c.CustomerName,
od.quantity * p.price "orderPrice"
FROM Customers c
inner join Orders o
on c.CustomerId = o.CustomerId
inner join OrderDetails od
on o.OrderId = od.OrderId
inner join Products p
on od.ProductId = p.ProductId
order by orderPrice desc;
-- 유콩
SELECT Customers.CustomerID AS `고객아이디`, Customers.CustomerName AS `고객이름`, sum(Price * Quantity) AS `지출금액`
FROM Orders
JOIN OrderDetails ON Orders.OrderID = OrderDetails.OrderID
JOIN Products ON OrderDetails.ProductID = Products.ProductID
RIGHT JOIN Customers ON Orders.CustomerID = Customers.CustomerID
GROUP BY Customers.CustomerID
ORDER BY `지출금액` DESC;
-- 썬
select c.CustomerID, c.CustomerName, sum(od.quantity * p.price) as price_total
from Customers c
inner join Orders o on c.CustomerID = o.CustomerID
inner join OrderDetails od on o.OrderID = od.OrderID
inner join Products p on p.ProductID = od.ProductID
group by c.CustomerID
order by price_total desc;
-- 수달
select c.CustomerName as '고객명', sum(d.Quantity * p.price) as '지출금액'
from Customers c inner join Orders o on c.CustomerID = o.CustomerId
join OrderDetails d on o.OrderID = d.OrderId join Products p on d.ProductID = p.ProductID
group by c.CustomerID
having sum(p.price * d.Quantity)
order by sum(p.price * d.Quantity) desc;
-- 릭
SELECT c.CustomerID AS `ID`, c.CustomerName AS `고객명`
FROM Customers AS c
INNER JOIN Orders AS o ON c.CustomerID = o.CustomerID
GROUP BY o.CustomerID
ORDER BY SUM(o.CustomerID) DESC;
-- 연로그
select c.CustomerID
, c.CustomerName
, sum(p.Price * od.Quantity) total
from Customers c
join Orders o on o.CustomerID = c.CustomerID
join OrderDetails od on o.OrderID = od.OrderID
join Products p on p.ProductID = od.ProductID
group by c.CustomerID
order by total desc;
-- 봄
SELECT c.customerId, c.customerName, sum(p.price * od.quantity) as total FROM Customers as c
JOIN Orders as o ON c.customerId = o.customerId
JOIN OrderDetails as od ON o.orderId = od.orderId
JOIN Products as p ON od.productId = p.productId
GROUP BY c.customerId
ORDER BY total DESC;
-- 라라
select c.CustomerID, c.CustomerName, sum(p.Price * od.Quantity) as total
from Customers as c
inner join Orders as o on c.CustomerID = o.CustomerID
inner join OrderDetails as od on od.OrderId = o.OrderId
inner join Products as p on p.ProductId = od.ProductId
group by c.CustomerID
order by total desc